Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,559 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMG%3C/text%3E%3C/svg%3E)
What are the different ways in which we could query data from ADLS. I would like to know the difference between
Data Explorer, Data Bricks and Synapse Studio to query the data.

Hello @Manoj G ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
---------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hello @Manoj G ,
Welcome to the MS Q&A platform.
You can use Azure services to ingest data, perform analytics, and create visual representations. The below list of supported Azure services, discloses their level of support, and provides you with links to articles that help you to use these services with Azure Data Lake Storage Gen2.
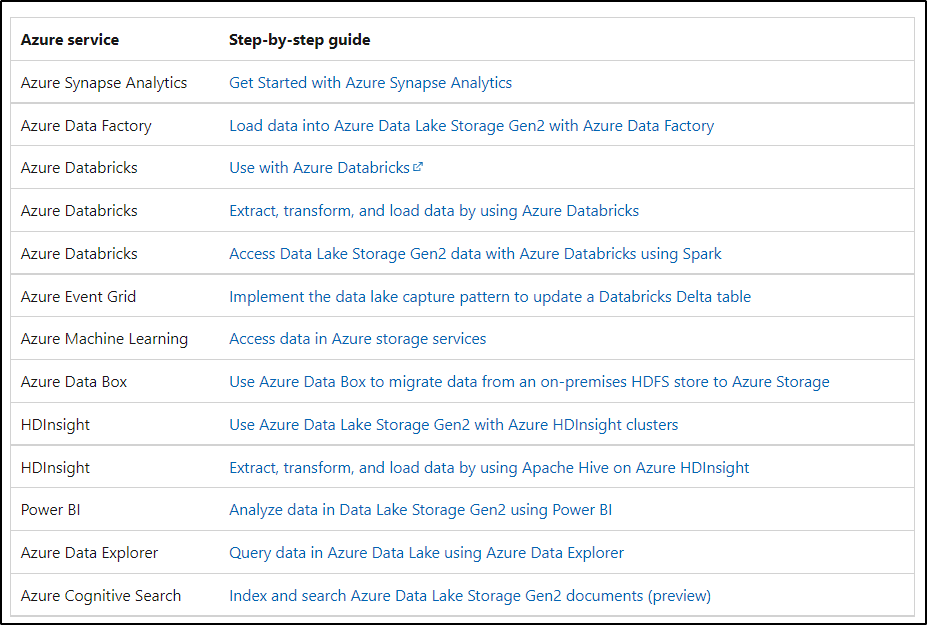
For more details, refer to Tutorials that use Azure services with Azure Data Lake Storage Gen2.
Azure Synapse started as a cloud data warehousing solution but recently evolved into a multipurpose data processing solution. Not only it allows to store data inside dedicated SQL pools, but also using Synapse Studio we can do ad-hoc analysis, data processing, create and schedule pipelines and event create PowerBI reports. Basically, Azure Synapse Studio is providing a unified environment for end-to-end data analysis, from raw data on ADLS to PowerBI dashboards. Also, Spark notebooks are first-class citizens together with SQL. With Spark pools and notebooks, we can utilize a Spark cluster while paying only for the time that we use them. Also, Spark notebooks support .NET for Spark so you can reuse C# code. These notebooks and other artifacts can be versioned with Git. Synapse studio provides integration with Git like ADF, and whatever you do in ADF can be in Synapse Studio.
Azure Databricks is a data analytics platform optimized for the Microsoft Azure cloud services platform. Azure Databricks offers three environments for developing data intensive applications: Databricks SQL, Databricks Data Science & Engineering, and Databricks Machine Learning.
There are several differences between Databricks workspace and Synapse Spark poll. Databricks support classical set languages for Spark API: Python, Scala, Java, R, and SQL. While Synapse supports Python, Scala, SQL, and C#. Another important difference is the runtime. Synapse is using Azure Synapse for Spark which is based on Apache Spark but optimized by the Synapse team. Meanwhile, Databricks is using its own custom runtime again based on Apache Spark but optimized by Databricks (creators of Spark). There are some benchmarks for each one compared to vanilla Apache Spark but I am not aware of Synapse vs Databricks runtime comparison.
Azure Data Explorer serves a different role in comparison to Azure Databricks and Synapse. Its main purpose is interactive analytics of structured and unstructured data such as logs and telemetry. Not only data can be ingested from streaming sources such as EventHub, but also it becomes immediately available for querying after ingestion. ADX can serve also as backing storage for your dashboards such as Grafana and PowerBI.
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Manoj G ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.