Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,080 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAM%3C/text%3E%3C/svg%3E)
I have the following scala code that is running without any errors on Azure Databricks runtime 5.5 - 6.4LTS.
Now that we have upgraded to databricks runtime 7.3 the same code is not working. I have added multiple com.azure.* libraries to test, installed jar files for the relevant libraries to no avail.
can someone please provide the specific libraries i need to install / make changes to my code ?
Code sample:
%scala
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
import org.apache.spark.sql.SQLContext
import com.microsoft.azure.sqldb.spark.query._
val query ="""truncate table testable""".stripMargin
val config = Config(Map(
"url" -> HostName,
"databaseName" -> DatabaseName,
"user" -> UsernameName,
"password" -> connectPassword,
"querycustom" -> query))
sqlContext.sqlDBQuery(config)
the error i am getting is as below
error: object sqldb is not a member of package com.microsoft.azure
import com.microsoft.azure.sqldb.spark.config.Config
the microsoft azure libraries i am using are:
com.microsoft.azure:spark-mssql-connector_2.12 Release 1.2.0
using the old libraries (scala 2.11) on the newer cluster i get a different error something like classdef not found Product/$class
also if there is no support for this code to run on newer versions of scala, is there an alternate way for bulkcopy so that i can use that.

Hello @AHMAD Muhammad ,
Welcome to the MS Q&A platform.
(UPDATE:5/4/2022): If you are getting the
sqldberror means all other support libraries already imported to your notebook and only the latest JAR with dependencies are missing.
As per the repro, I got the same error message as shown above:
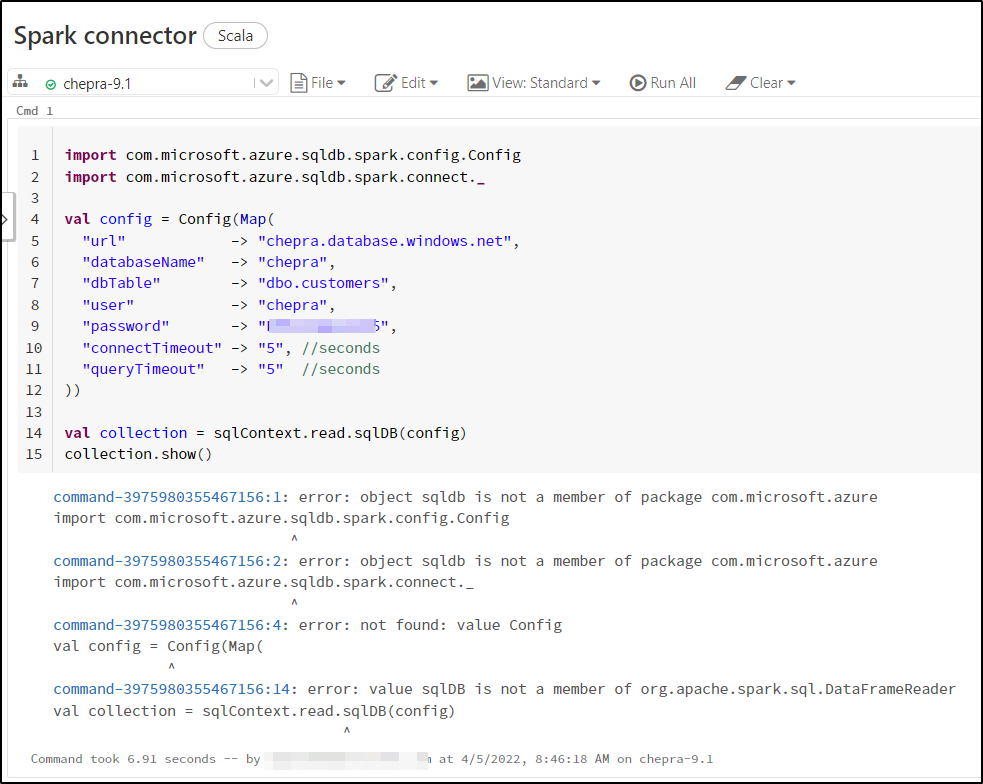
After bit of research, I had found that you will experience this error due to missing JAR with dependencies.
To resolve this issue, you need to download the JAR file from here: https://search.maven.org/artifact/com.microsoft.azure/azure-sqldb-spark/1.0.2/jar
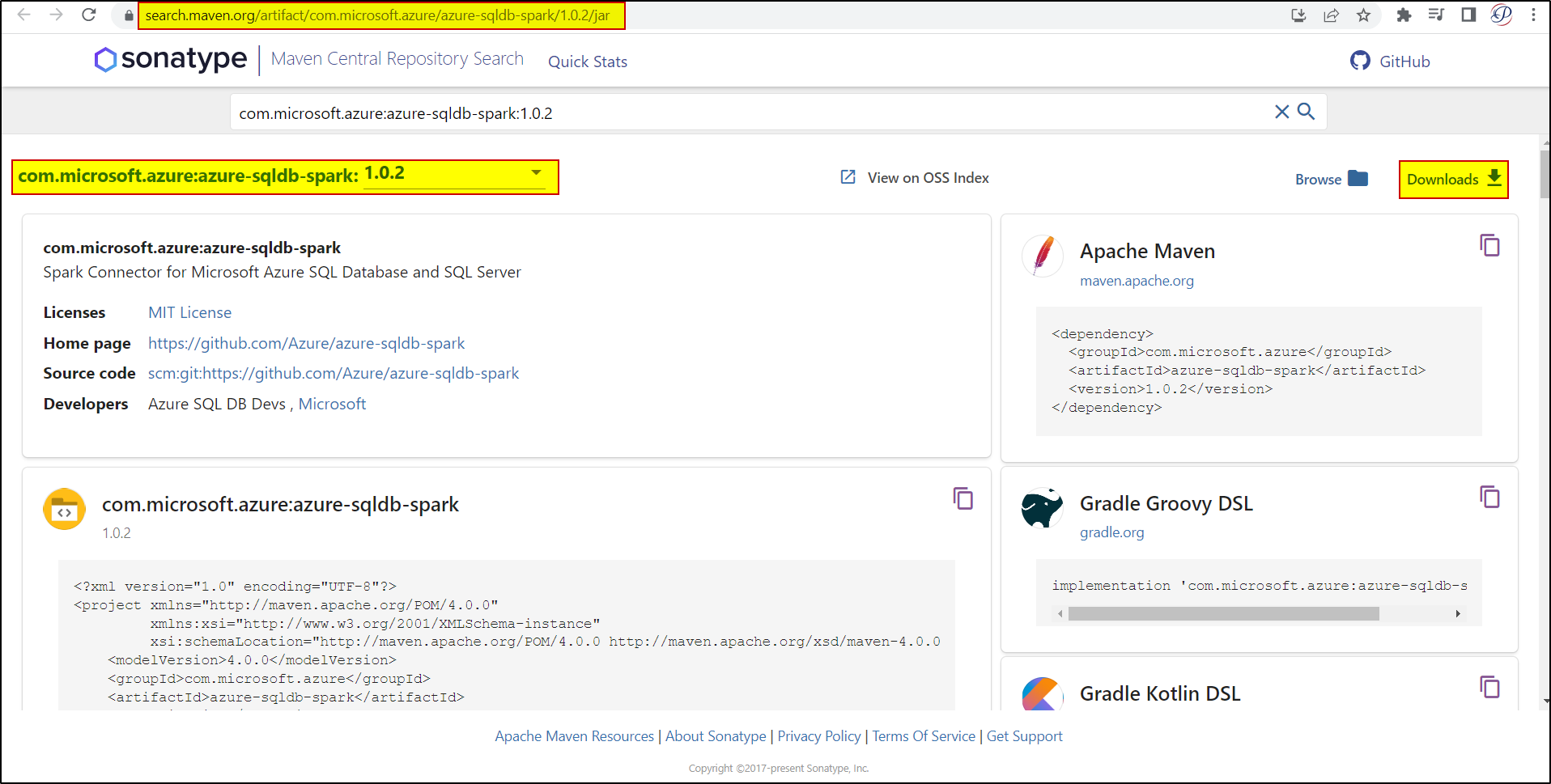
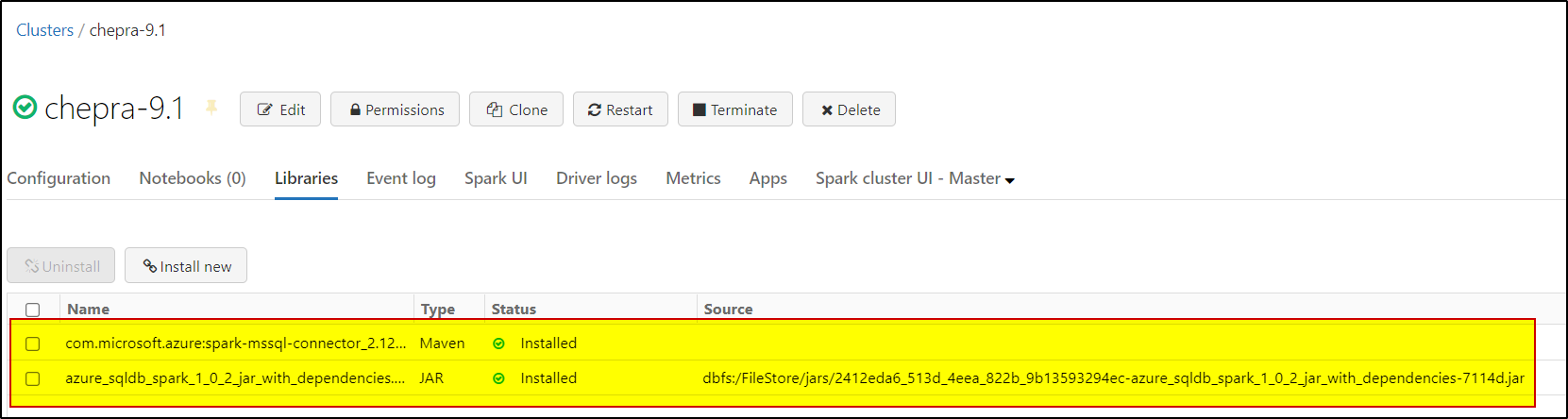
After downloaded the jar file, upload the JAR library into the cluster and install it.
Note: After installing both the libraries, make sure to restart the cluster.
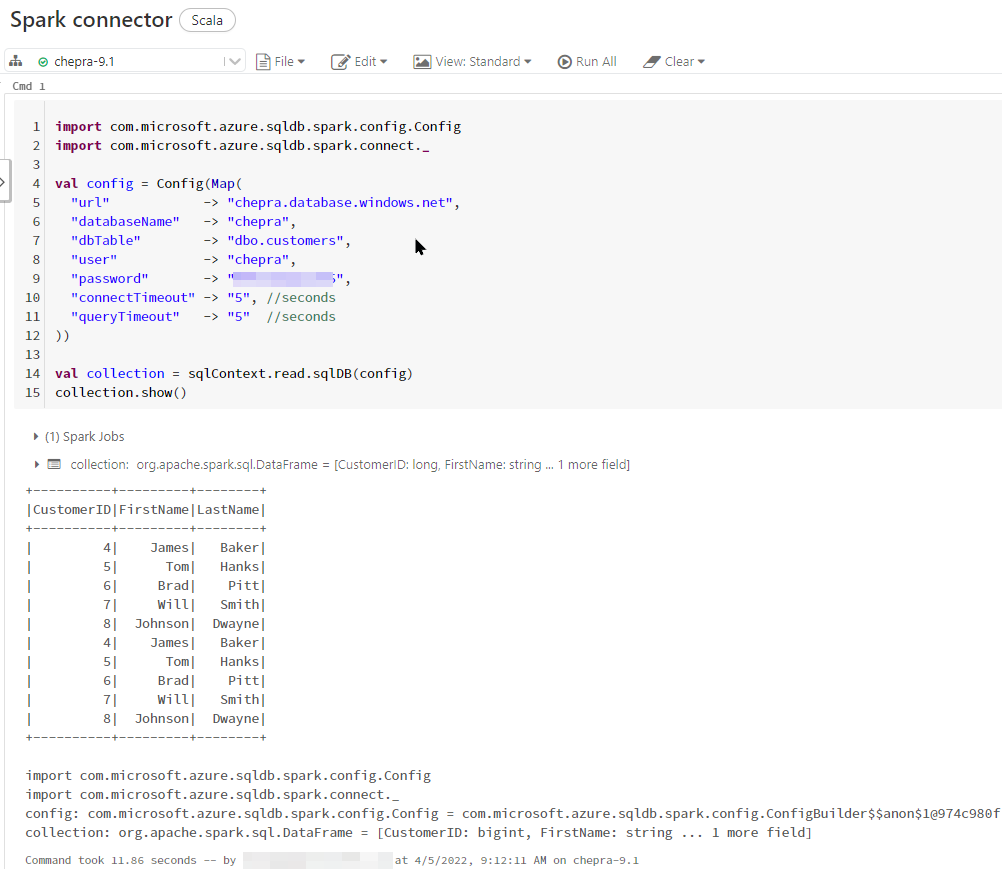
Now, you will be able to run the command successfully.
---------------------------------------
The GitHub repo for the old connector previously linked to from this page is not actively maintained. Instead, we strongly encourage you to evaluate and use the new connector.
There are three version sets of the connector available through Maven, a 2.4.x, a 3.0.x and a 3.1.x compatible version. All versions can be found here and can be imported using the coordinates below:
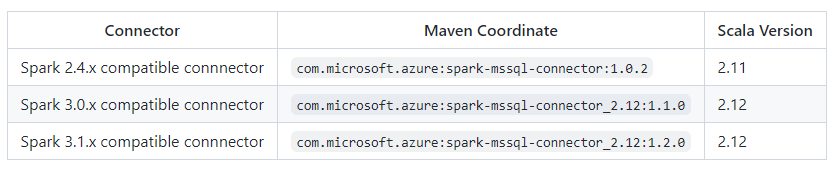
The traditional jdbc connector writes data into your database using row-by-row insertion. You can use the Spark connector to write data to Azure SQL and SQL Server using bulk insert. It significantly improves the write performance when loading large data sets or loading data into tables where a column store index is used.
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
/**
Add column Metadata.
If not specified, metadata is automatically added
from the destination table, which may suffer performance.
*/
var bulkCopyMetadata = new BulkCopyMetadata
bulkCopyMetadata.addColumnMetadata(1, "Title", java.sql.Types.NVARCHAR, 128, 0)
bulkCopyMetadata.addColumnMetadata(2, "FirstName", java.sql.Types.NVARCHAR, 50, 0)
bulkCopyMetadata.addColumnMetadata(3, "LastName", java.sql.Types.NVARCHAR, 50, 0)
val bulkCopyConfig = Config(Map(
"url" -> "mysqlserver.database.windows.net",
"databaseName" -> "MyDatabase",
"user" -> "username",
"password" -> "*********",
"dbTable" -> "dbo.Clients",
"bulkCopyBatchSize" -> "2500",
"bulkCopyTableLock" -> "true",
"bulkCopyTimeout" -> "600"
))
df.bulkCopyToSqlDB(bulkCopyConfig, bulkCopyMetadata)
//df.bulkCopyToSqlDB(bulkCopyConfig) if no metadata is specified.
For more details, refer to Accelerate real-time big data analytics using the Spark connector.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how 3: /api/attachments/189984-image.png?platform=QnA 5: https://github.com/microsoft/sql-spark-connector
Hi Pradeep,
Thankyou for your detaenter code hereiled response. that clarifies many things. Unfortunately i am still getting the same error.
My Databricks cluster is running on 9.1LTS and i installed "com.microsoft.azure:mssql-spark-connector_2.12:1.2.0
i imported the libraries as you advised in a scala cell
%scala
// Insert data using new method
import com.microsoft.azure.sqldb.spark.bulkcopy.BulkCopyMetadata
import com.microsoft.azure.sqldb.spark.config.Config
import com.microsoft.azure.sqldb.spark.connect._
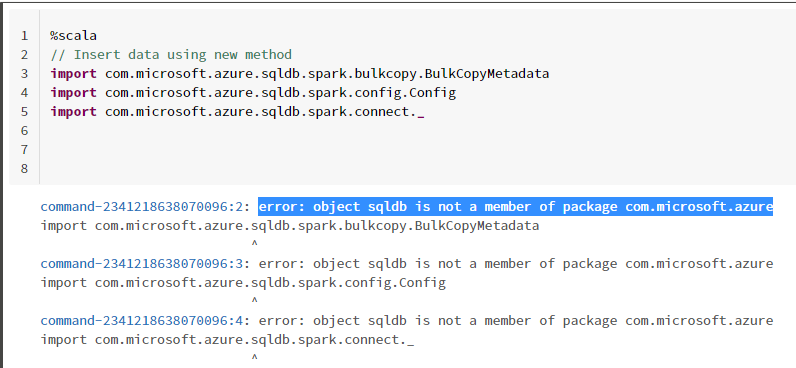
I am still gettin the error "sqldb" is not a member of com.microsoft.azure
error: o![189850-capture.png][1]bject sqldb is not a member of package com.microsoft.azure
![189876-cluster.png][3]
@PRADEEPCHEEKATLA-MSFT - Please have a look at my previous response. The issue is still there.
Hello @AHMAD Muhammad ,
Please check the updated answer and do let us know if you have any questions.
------------------------------
or upvote button whenever the information provided helps you.
@PRADEEPCHEEKATLA-MSFT
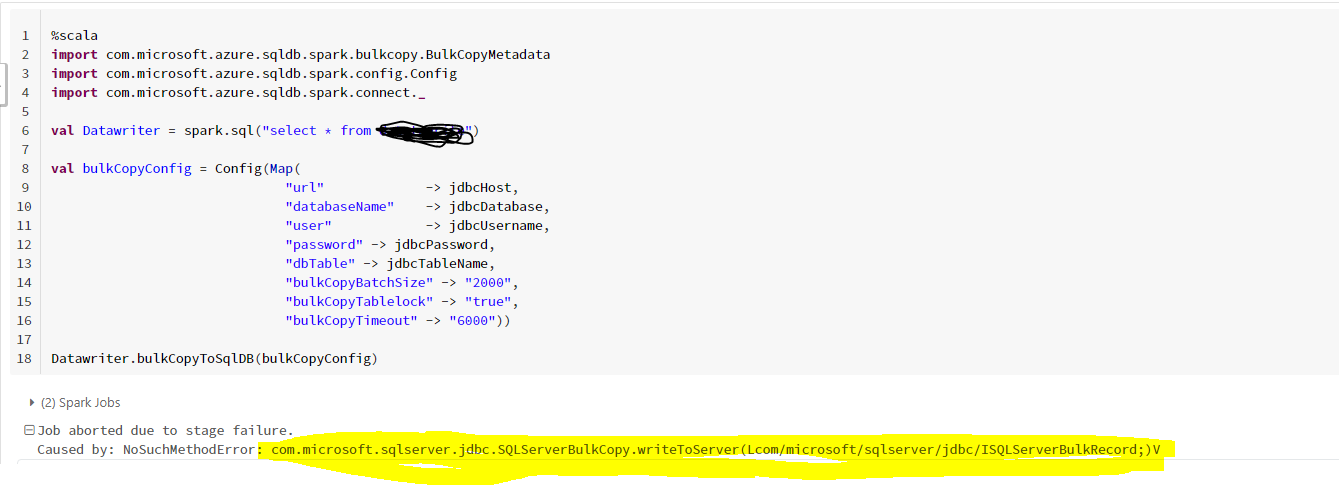
Thanks pradeep, the issue is half resolved. i am able to read from the database, but still unable to write to it with a different error
NoSuchMethodError: com.microsoft.sqlserver.jdbc.SQLServerBulkCopy.writeToServer(Lcom/microsoft/sqlserver/jdbc/ISQLServerBulkRecord;)V
I have tried installing some sql jdbc libraries but surely i am not installing the right one, can you please advise on which one exactly do i need to install to enable datawrite.
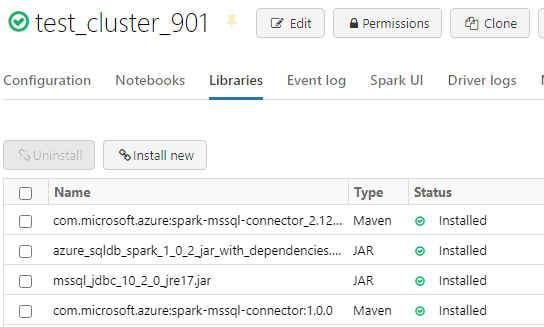
Please refer to the screenshots for the libraries installed.
Hello @AHMAD Muhammad ,
As per the answer, the initial question was addressed in this thread. You can accept it as answer( ). This can be beneficial to other community members. Thank you.
). This can be beneficial to other community members. Thank you.
For the second question, the scope of your question is different compared to the original scope of the question asked.
I would recommend creating a new thread on the same forum with as much details about your issue as possible. That would make sure that your issue has better visibility in the community.