Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hello,
I am relatively new to using Azure, currently working on a data migration project. Part of that is to extract separate files (mainly data files and header files), and merge them in ADF.
I was able to create a data flow that merged the header files to the data files and sort them so that the header showed as the first row. It had been working fine for a while - the output showed the header at the top and then the data. Recently though, the header no longer shows up as the first row but is randomly inserted in the data.
When I look at the data preview the data seems to show up correctly (see 1st screenshot), but in the output is where I see the differences (see 2nd screenshot - cut off due to sensitive data).
1st screenshot

2nd screenshot

The weird thing is that there are other output files that are showing up correctly (use the same data flow - see screenshot 3):
3rd screenshot

I have checked that all the configurations are identical to the ones that work but it just doesn't make sense. At this point, I'm reaching out to see if anyone has any suggestions on how to fix this.
4th is a screenshot of the data flow used to merge the header files with the data files and sort the header rows:

Another thing to note: these are not the final (FINAL) outputs, just the first transformation. The actual final output files show up correctly (header at top)...which is very bizarre.
Thanks.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Anonymous ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is to preserve row order during union transformation .
The union transformation uses a SQL union. SQL unions do not guarantee row order by default. To speed things up, rows are added as soon as they are ready. However there is a way around this. Link to relevant stack overflow thread. They give each 'table' a number, then sort after the union.
Now the question becomes how to implement this in Data Factory Data Flow.
To add a (temporary) column to order by, we put a Derived Column transformation after each source. Lets call it orderColumn in each. For the value, lets just give a number, 1 for the header, 2 for the body. Assuming things line up during the Union , we just add a Sort transformation (ascending on orderColumn) afterwards. Then discard the orderColumn. Picture below.
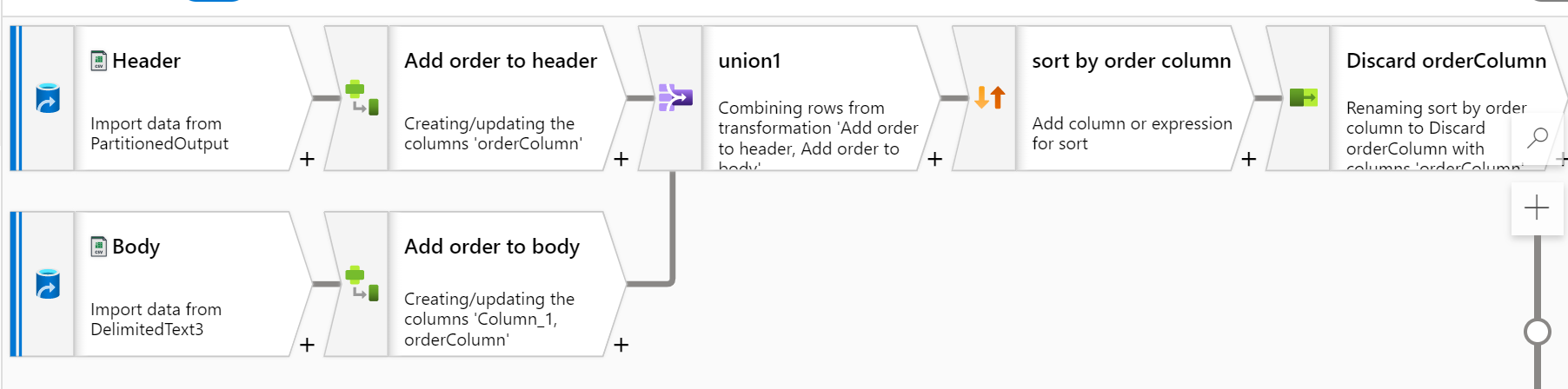
Please do let me if you have any queries.
Thanks
Martin
P.S. I know the transformation names break, but I did that to make the picture easier to read.
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Thank you for taking the time to respond. The process that you shared is the same process I have followed since the beginning. This is why it's weird that it is no longer working - it worked just fine a few weeks ago, but now I am getting the header not in the top row as specified. Any thoughts on why this would be?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @Anonymous ,
Thanks for the response .
You should be able to accept the below answer now .
Thanks
Himanshu
Hmm, all I can think of is perhaps a side affect of partitioning, @Anonymous . Keeping everything in 1 single partition should guarantee there is no shuffling after the sort.
The Sort transformation has an "only sort within partition". Turn that off.
The Sink transformation has options on how to partition. Assuming your data is small, try single partition.
The Source transformations have partition options, but I don't think this matters, because the data and header are in separate streams.
Can you tell me where the header row is showing up? Just checking it isn't something like, at the bottom, which means we got the sorting backwards.
Hi,
I will turn off that option on the sort and report back. The header is showing up around the middle of the dataset. And only does it for a few files - not all. Which makes it even more bizarre. Thank you!
Laura
Hello @Anonymous ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
@HimanshuSinha for some reason I thought I had selected "accepted an answer".
I turned off the sort partition and that seemed to do the trick! Thank you.