Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,661 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
Hello,
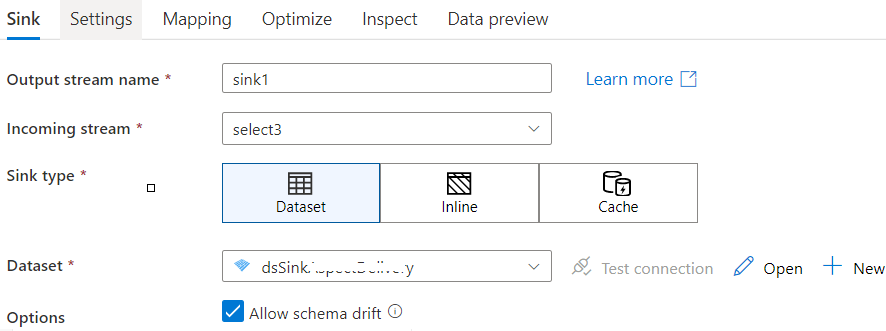
I am using a sink dataset in ADF as follows:
dataset1
file path: containername/foldername/subfoldername/
Note that the file box is blank
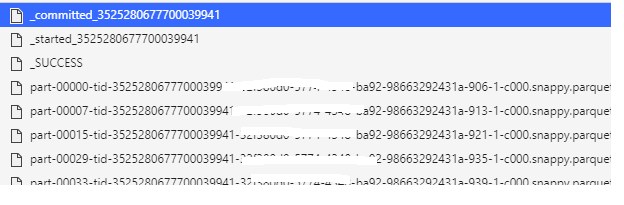
Once the ADF job is completed, the storage folder looks like it has files such as:
_committed...
_started...
_success
part-0000-...parquet
part-0007...parquet
...
Question:
Are these what is referred to as Delta files?
I ask because as you see in screenshots, I do not use Inline Sink Type or Delta dataset in Sink.
Thank you


Hi @arkiboys ,
Thankyou for using Microsoft Q&A platform and posting your query.
As I understand your query , you want to know the significance of different metadata files generated after the pipeline execution completes. Also, looks like you want to know why the output parquet files are split across into different small files. Could you please confirm that your pipeline consists of activity that runs on Spark cluster , eg: Dataflow / Notebook or Databricks activities ?
_committed,_started,_successare the transactional files created using a commit protocol when we run a spark job. These are generally used to implement fault tolerance in Apache spark.
To better understand why job commit is necessary, let’s compare two different failure scenarios if Spark were to not use a commit protocol:
Either of these scenarios can be extremely detrimental to a business. To avoid these data corruption scenarios, Spark relies on commit protocol classes from Hadoop that first stage task output into temporary locations, only moving the data to its final location upon task or job completion.
When DBIO transactional commit is enabled, metadata files starting with started<id> and committed<id> will accompany data files created by Apache Spark jobs. Generally you shouldn’t alter these files directly. Rather, use the VACUUM command to clean the files.
You can refer to the following documents and video for more details:
Transactional Writes to Cloud Storage on Databricks
Transactional writes to cloud storage with DBIO
https://youtu.be/w1_aOPj5ILw?t=533
Coming to the output parquet file which are partitioned into small chunk of files , since the file name in your sink dataset is empty , ADF will automatically create multiple output files with automatically generated filename for the partitioned files.
In copy activity sink settings, you can specify the maximum number of rows per file you want to allow for each partitioned file and also can provide the FileName prefix which would create the files in this format: <fileNamePrefix>_00000.parquet. If not specified, prefix will be auto generated.
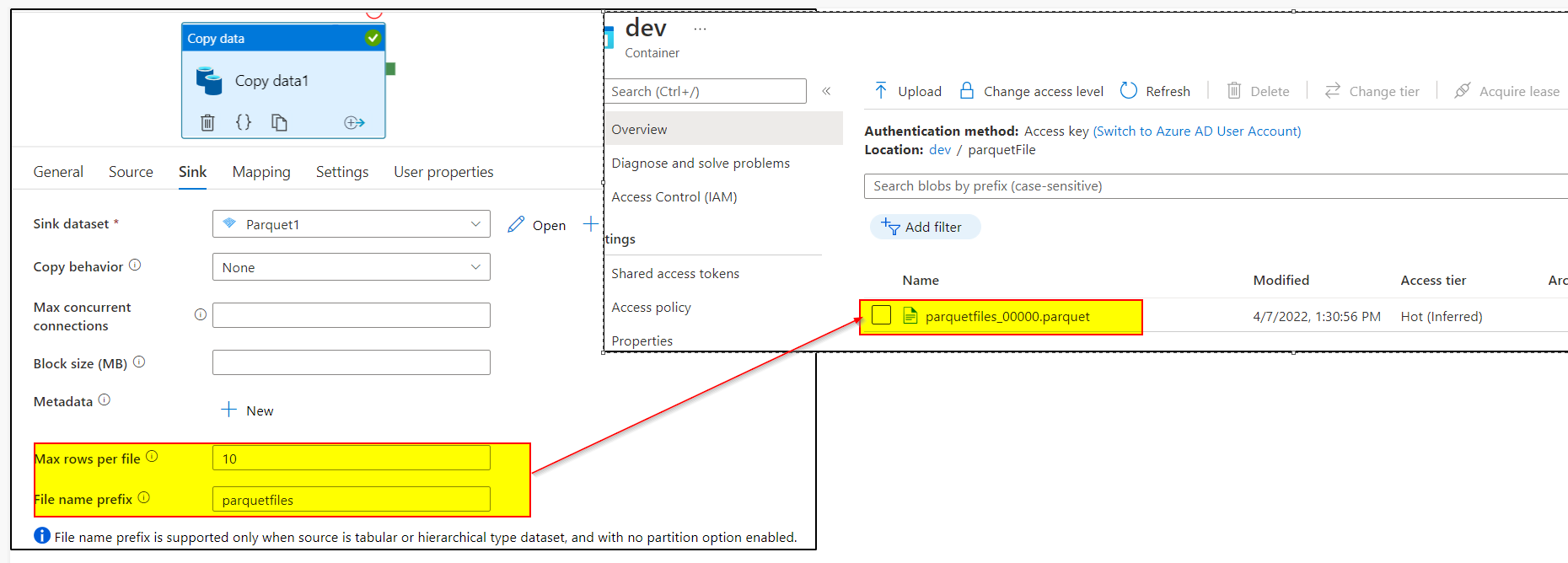
If you want to see your output in a single file instead of partitioned files , then you need to provide the fileName in your sink dataset which is currently empty in your case.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
I am using dataflow which produces split files.
Does this mean I am using delta ? and everytime the data is updated then these split files get updated rather than re-written over?
Thank you