Azure Event Hubs
An Azure real-time data ingestion service.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESB%3C/text%3E%3C/svg%3E)
Oracle database table has 3 million records. I need to read it into dataframe and then convert it to json format and send it to eventhub for downstream systems.
Below is my pyspark code to connect and read oracle db table as dataframe
df = spark.read \
.format("jdbc") \
.option("url", databaseurl) \
.option("query","select * from tablename") \
.option("user", loginusername) \
.option("password", password) \
.option("driver", "oracle.jdbc.driver.OracleDriver") \
.option("oracle.jdbc.timezoneAsRegion", "false") \
.load()
then I am converting the column names and values of each row into json (placing under a new column named body) and then sending it to Eventhub.
I have defined ehconf and eventhub connection string. Below is my write to eventhub code
df.select("body") \
.write\
.format("eventhubs") \
.options(**ehconf) \
.save()
my pyspark code is taking 8 hours to send 3 million records to eventhub.
My Eventhub is created under eventhub cluster which has 1 CU in capacity
Could you please suggest how to write pyspark dataframe to eventhub faster ?
Databricks cluster config :
mode: Standard
runtime: 10.3
worker type: Standard_D16as_v4 64GB Memory,16 cores (min workers :1, max workers:5)
driver type: Standard_D16as_v4 64GB Memory,16 cores

Hello @Shivasai Bommaraveni ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hello @Shivasai Bommaraveni ,
Thanks for the question and using MS Q&A platform.
You may checkout the below options to increase the write performance:
Option1: Increase the throughput unit capacity or enable Auto-Inflate future.
Auto-Inflate automatically scales the number of Throughput Units assigned to your Standard Tier Event Hubs Namespace when your traffic exceeds the capacity of the Throughput Units assigned to it. You can specify a limit to which the Namespace will automatically scale.
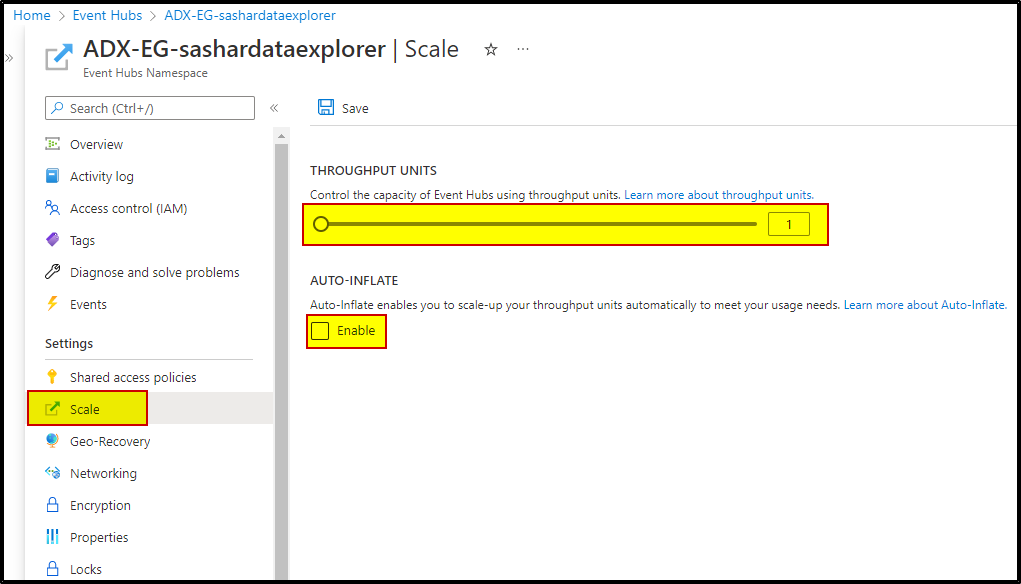
Option2: Setup
maxEventsPerTriggeroption in your query.
Rate limit on maximum number of events processed per trigger interval. The specified total number of events will be proportionally split across partitions of different volume.
After adding below code in the data bricks job to consume more event hub records throughput has been improved.
`.option("maxEventsPerTrigger", 5000000)`
For more information, refer to Azure Databricks – Event Hubs.
Hope this will help. Please let us know if any further queries.
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @Shivasai Bommaraveni ,
Just checking in to see if the above answer helped. If this answers your query, do click Accept Answer and Up-Vote for the same. And, if you have any further query do let us know.