Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
9,617 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EAE%3C/text%3E%3C/svg%3E)
Hello
Let me give you some background:
I have to copy data from an ADLGen2 to an Azure PostgreSQL table. The data stored in ADLGen2 is AVRO format data from an Event Hub. I have configured a DataFlow and a Pipeline that works perfectly and allows me to copy the data without problems every time I run a trigger.
 This is the Dataflow taking as source only one record to make the tests
This is the Dataflow taking as source only one record to make the tests
 And this is the Pipeline
And this is the Pipeline
At this point I have some doubts because I need to automate the process.
The files in ADLGen2 are stored in a folder structure as follows: store name/container name/0/year/month/day/hour/minute/20.avro
Each time a record from the eventhub is saved, a new folder with this structure is created.
How can I make my Data Factory go through all the folders and how can I configure it to only copy new data into the PostgreSQL table?
Thank you in advance

Hi @Andres Esteban ,
Thankyou for using Microsoft Q&A platform and posting your query.
As I understand your question here, you are trying to copy data from ADLS to Postgre SQL and the data stored in the ADLS is in the format - 'store name/container name/0/year/month/day/hour/minute/20.avro'. You want to process only the new data which arrives in a newly created folder and copy the same to PostGre SQL table.
So , you want to know how to fetch the latest and greatest data from the new folder. Please correct me if my understanding is incorrect.
To achieve this, you can use one of the following approaches:
Option1:
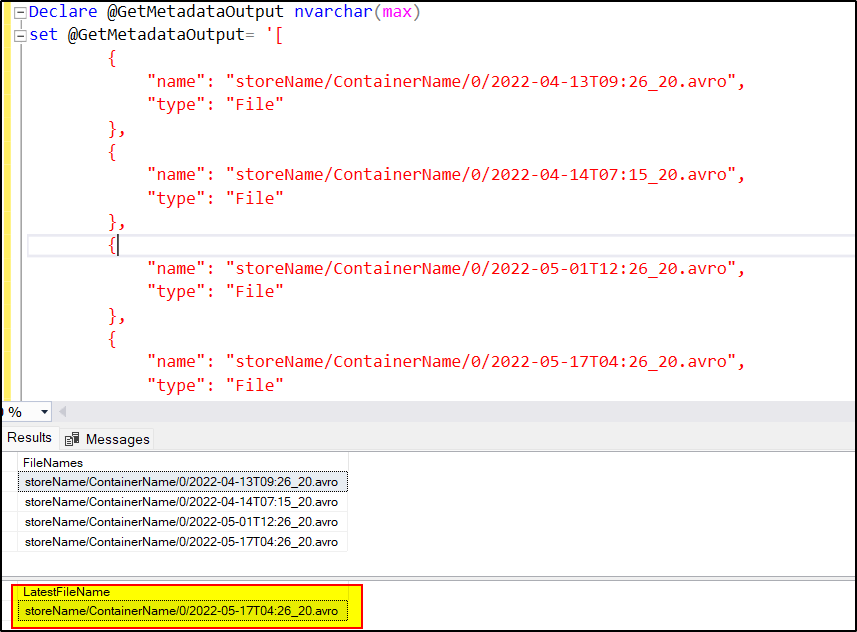
Create an ADF pipeline and use Get Metadata activity to fetch all the files present in ContainerName/0 folder and then use LookUp activity having dataset pointing to PostGreSQL /Azure SQL and write SQL query to fetch the max value of the fileName. Example:
Declare @GetMetadataOutput nvarchar(max)
set @GetMetadataOutput= '@{activity('Get Metadata1').output.childItems}'
Select * FROM OPENJSON(@GetMetadataOutput) WITH(FileNames NVARCHAR(200) '$.name')
select max(fileNames) as LatestFileName from (
Select * FROM OPENJSON(@GetMetadataOutput) WITH(FileNames NVARCHAR(200) '$.name'))a
Option2:
Hope this will help. Please let us know if any further queries.
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @Andres Esteban ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
Hello
Your answer was really helpful. What I did was to change the folder structure generated in my Data Lake as you suggested. Now, all the AVROS are saved in the same folder so it is much easier to go through all the files, for that, I changed it in the linked Event Hub data capture.

Once this was changed and all AVROs were stored in the same folder, in Azure Data Factory, in the Data Flow, I set the root folder as the data source and in the source options I set the following:
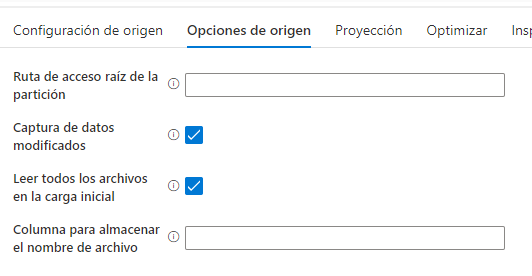
By doing this, it works and copies only the new data that is registered in the data lake.
Thank you very much
@Andres Esteban ,
Glad to know that it helped. Thanks !