Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
3,192 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
Hi all,
I want to read multiple parquet.gzip files incrementally into a pandas dataframe from my blob storage, do manipulation on them and store them using python. How can this be done effectively?
Note: Tried to read them directly using pd.read_parquet but i guess it doesn't work that way in Azure.
Can you guys help me out with a code snippet?

Hello @Samyak ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hello @Samyak ,
Thanks for the question and using MS Q&A platform.
When I tired to read multiple parquet.gzip files using pandas got it error message:
OSError: Could not open parquet input source '<Buffer>': Invalid: Parquet magic bytes not found in footer. Either the file is corrupted or this is not a parquet file.

After bit of research, found this document - Azure Databricks - Zip Files which explains to unzip the files and then load the files directly.
You can invoke the Azure Databricks
%shzip magic command to unzip the file and read using pandas as shown below:
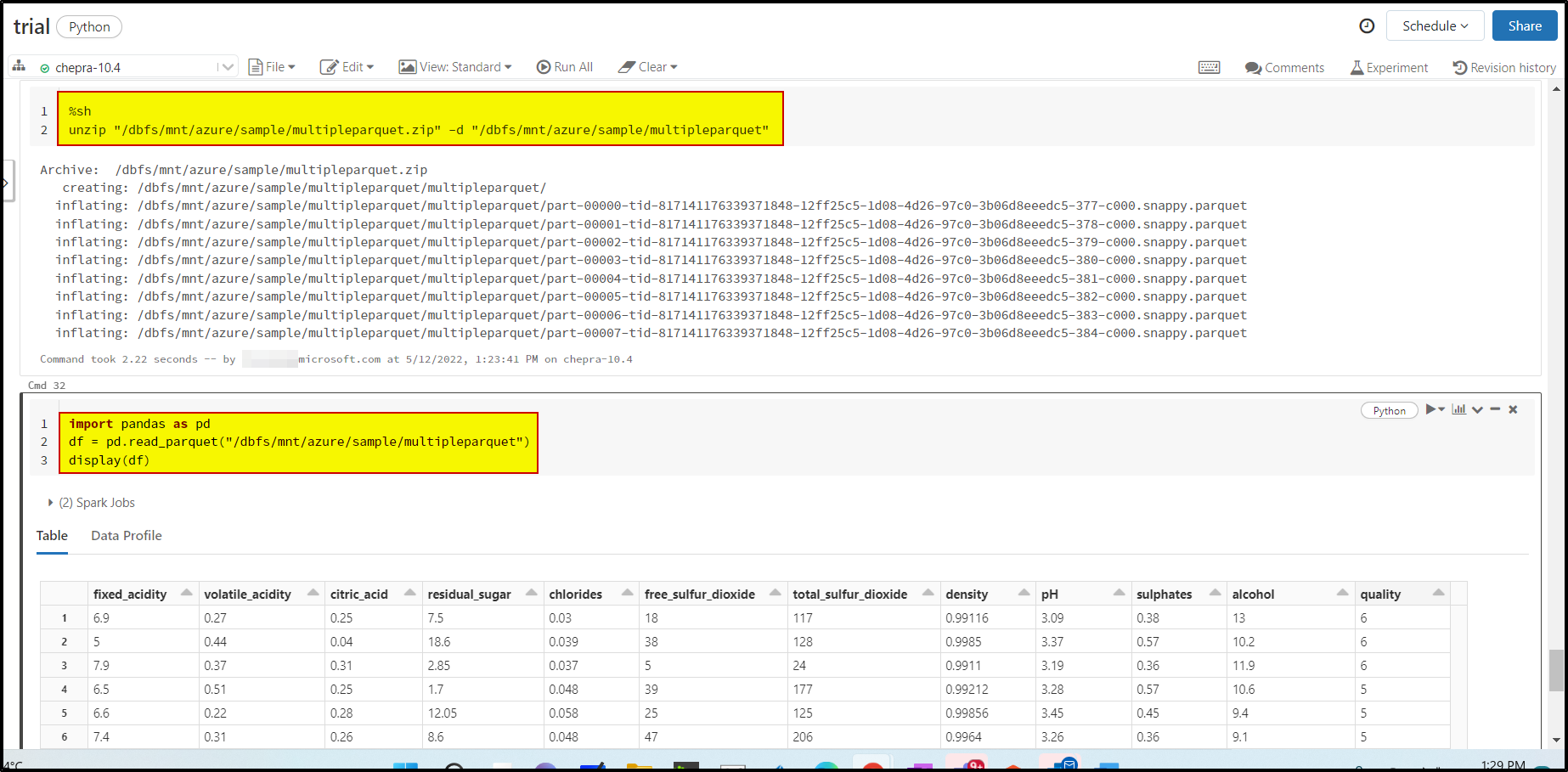
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hi @PRADEEPCHEEKATLA
Thanks for the response. But what I'm doing is uploading a python script with a parquet dataset on blob storage and then triggering that script using ADF and using Batch service for computation. When i trigger the script and read the parquet file, it requires pyarrow. This is where I am stuck and need help with. Also, if in future i need to install certain dependencies then i would like to know how that is to be done.
Hello @Samyak ,
Thanks for sharing additional details.
Could you please share the python script which you are using along with the error message which you are experiencing?
Hello @Samyak ,
Just checking in if you have had a chance to see the previous response. We need the following information to understand/investigate this issue further.