Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EQC%3C/text%3E%3C/svg%3E)
Hi everyone,
I'm trying to import parquet and excel files into the Pyspark notebook but I encounter the same probleme with both type of file. Here is the code I was trying to run :
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark=SparkSession.builder.appName("PySpark Read Parquet").getOrCreate()
account_name = '' # fill in your primary account name
container_name = '' # fill in your container name
relative_path = '' # fill in your relative folder path
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
print('Primary storage account path: ' + adls_path )
spark.conf.set("fs.azure.account.auth.type.%s.dfs.core.windows.net" %account_name, "SharedKey")
spark.conf.set("fs.azure.account.key.%s.dfs.core.windows.net" %account_name ,"Your ADLS Gen2 Primary Key")
df1 = spark.read.parquet(adls_path + 'NDFGSE/NDFGSE.parquet')
Then i get this error message where only the number is changing : Py4JJavaError: An error occurred while calling o636.parquet.
: Failure to initialize configuration
I might think it's coming from the java configuration or the spark version but I'm not sure.
Thanks for the help,
Kind regards
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EH%3C/text%3E%3C/svg%3E)
Hello @Quentin Chiffoleau ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Himanshu
Hello @Quentin Chiffoleau ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet .In case if you have any resolution please do share that same with the community as it can be helpful to others .
If you have any question relating to the current thread, please do let us know and we will try out best to help you.
In case if you have any other question on a different issue, we request you to open a new thread .
Thanks
Himanshu
Hello @Quentin Chiffoleau ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is to read a paraquet file which is stored in ADLS gen2 , please do let us know if its not accurate.
I have tried the below code and it does work fine for me . I am not sure if you are using the SAS key or access key , I am using the access key below .
You will have to update the account key , account name , container name and relative path to work
import pyspark
from pyspark.sql import SparkSession
from pyspark.sql.types import *
spark=SparkSession.builder.appName("PySpark Read Parquet").getOrCreate()
account_name = 'accountName # fill in your primary account name
container_name = 'himanshu' # fill in your container name
relative_path = 'NYCTaxi/PassengerCountStats.parquet/part-00000-21161a2b-1c65-4a76-9999-0b2403785f46-c000.snappy.parquet' # fill in your relative folder path
adls_path = 'abfss://%s@%s.dfs.core.windows.net/%s' % (container_name, account_name, relative_path)
spark.conf.set('fs.azure.account.key.%s.dfs.core.windows.net' %(account_name) ,"accesskey")
df1 = spark.read.parquet(adls_path)
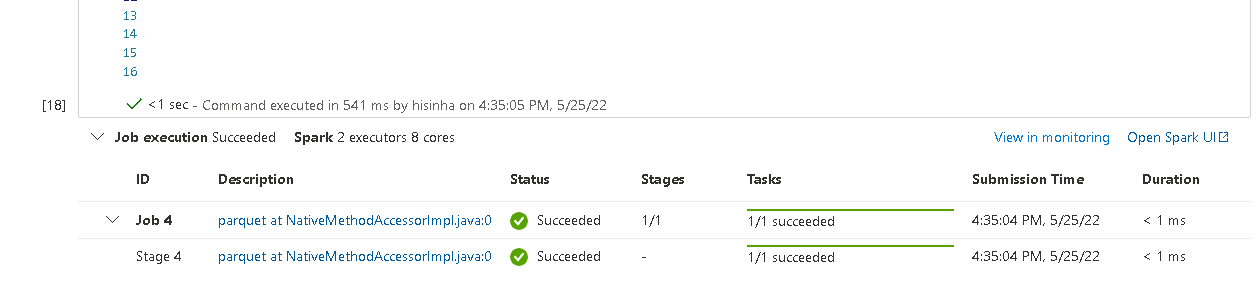
Please do let me if you have any queries.
Thanks
Himanshu
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how