Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
2,938 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESA%3C/text%3E%3C/svg%3E)
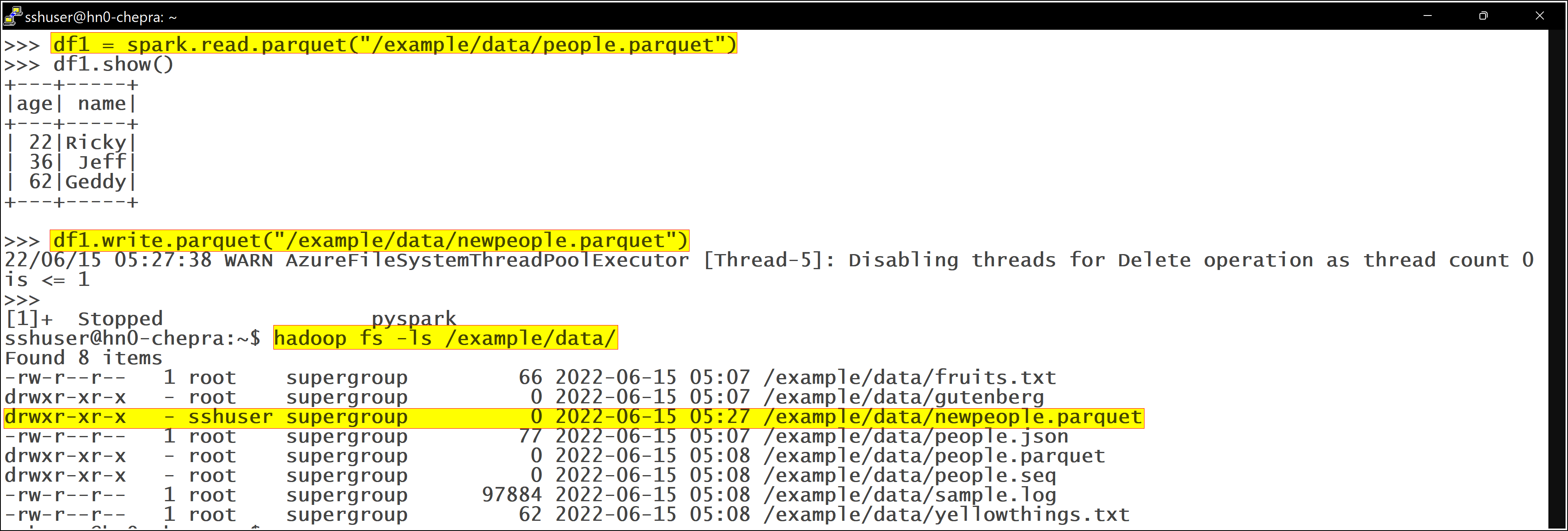
We've setup HDInsights cluster on Azure with Blob as the storage for Hadoop. We tried uploading files to the Hadoop using hadoop CLI and the files were getting uploaded to the Azure Blob.
Command used to upload:
Hadoop fs -put somefile /testlocation
However when we tried using Spark to write files to the Hadoop, it was not getting uploaded to Azure Blob storage but to the disk of the VMs at the directory specified in the hdfs-site.xml for the datanode.
Code used:
df1mparquet = spark.read.parquet("hdfs://hostname:8020/dataSet/parquet/")
df1mparquet .write.parquet("hdfs://hostname:8020/dataSet/newlocation/")
Strange behavior:
When we run:
hadoop fs -ls / => It lists the files from Azure Blob storage
hadoop fs -ls hdfs://hostname:8020/ => It lists the files from local storage
is this an expected behavior?

Hello @Saif Ahmad ,
Following up to see if the below suggestion was helpful. And, if you have any further query do let us know.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hello @Saif Ahmad ,
Thanks for the question and using MS Q&A platform.
This is an excepted behaviour in Azure HDInsight.
As a best practice, you should not use the local storage on the disk of the VMs. Recommended to use the Azure Storage account to save the files.
There are several ways you can access the files in Data Lake Storage from an HDInsight cluster. The URI scheme provides unencrypted access (with the wasb: prefix) and TLS encrypted access (with wasbs). We recommend using wasbs wherever possible, even when accessing data that lives inside the same region in Azure.
For more details, refer to Azure HDInsight - Access files from within cluster and Run Apache Spark from the Spark Shell.
Hope this will help. Please let us know if any further queries.
------------------------------
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
I had to point Hadoop config to spark for it automatically upload the files to Azure Blob storage.