Azure Blob Storage
An Azure service that stores unstructured data in the cloud as blobs.
3,192 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EKS%3C/text%3E%3C/svg%3E)
Hi, I'm looking to create pipeline like below.
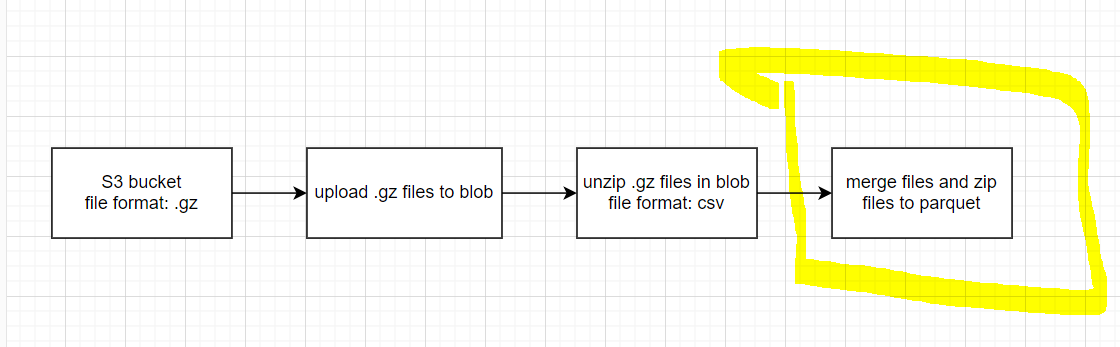
I created pipeline in Azure Synapse Analytics and run it, but the pipeline failed.

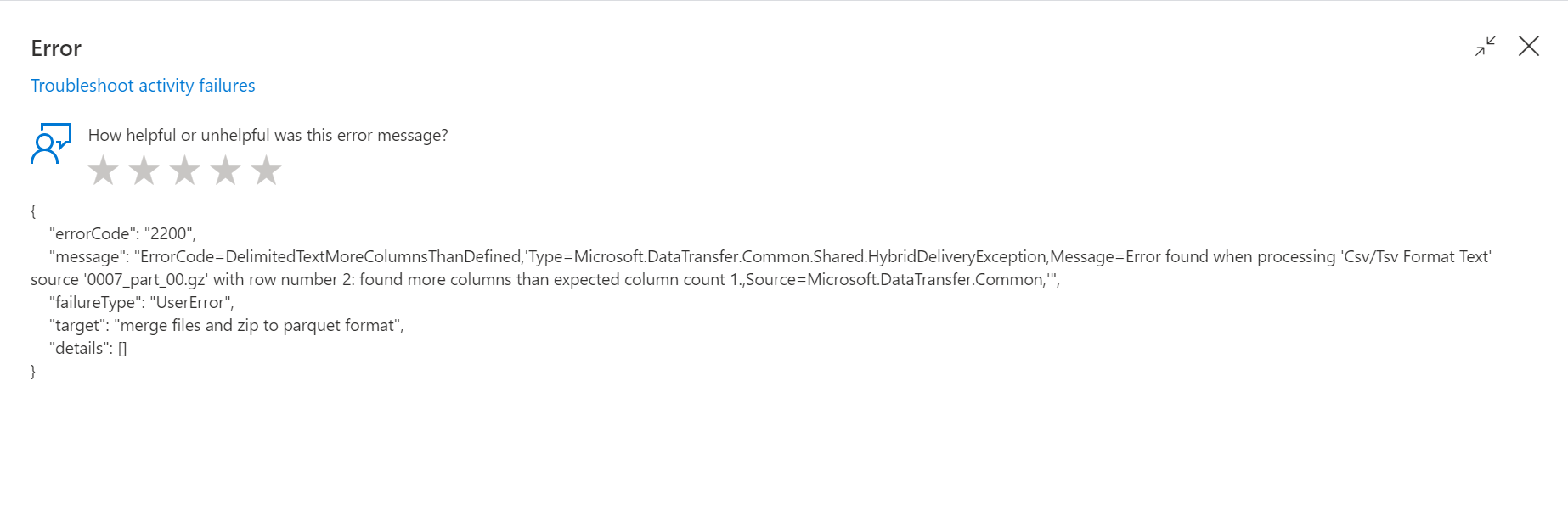
I don't know how to solve this problem.
CSV files format that I wanna marge is like below and all files are the same format.
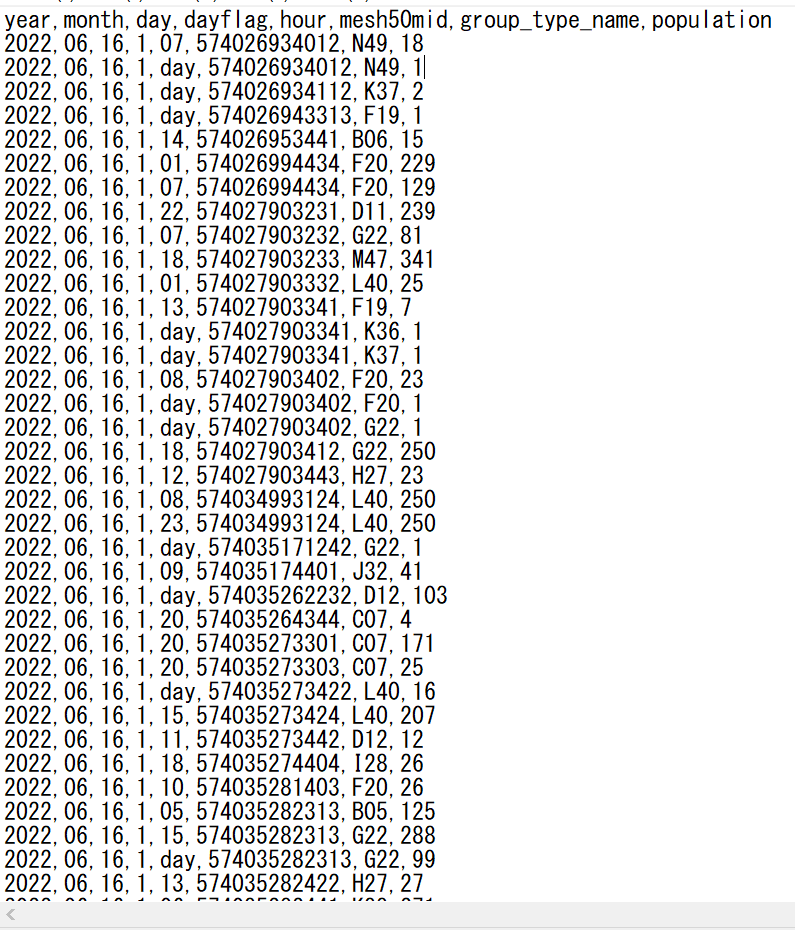
Any help would be appreciated.
If you need some additional information, please do not hesitate to tell me.
Thank you.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Kakehi Shunya (筧 隼弥) ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others . Otherwise, will respond back with the more details and we will try to help .
Thanks
Martin
Hello @Kakehi Shunya (筧 隼弥) ,
We haven’t heard from you on the last response and was just checking back to see if you have a resolution yet. In case if you have any resolution please do share that same with the community as it can be helpful to others .
If you have any question relating to the current thread, please do let us know and we will try out best to help you.
In case if you have any other question on a different issue, we request you to open a new thread .
Thanks
Martin
Hello @Kakehi Shunya (筧 隼弥) , welcome to Microsoft Q&A.
I see, during Copy Activity merging files, you get error stating it found more columns than expected. I also see your data looks uniform inside the indicated file. You want help resolving this.
There are a few things I can think of. First, did it write any data?
First, check your mapping in the Copy activity. Is any mapping set? If so, how many columns are there? Does the number of columns in the mapping match the number of columns shown in your file?
There are many things I would look at, but the mapping is my first suspect for several reasons:
Is your dataset using option "first row as header"?
Another think to check: Is your dataset using the correct "row delimiter"?
If the row delimiter is set to "newline" (\n), while the data is using "carriage return" (\r), then the entire file looks like one row. This would mean too many columns.
There is one more thing to try. The Copy activity settings has option to log incompatible rows. We can use this to determine which data is the problem, or in this case, how much of the data. Is it all data or just some data?
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how