Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
I have created a delta table using the following query in azure synapse workspace, it is uses the apache-spark pool and the table is created successfully. And in that, I have added some data to the table
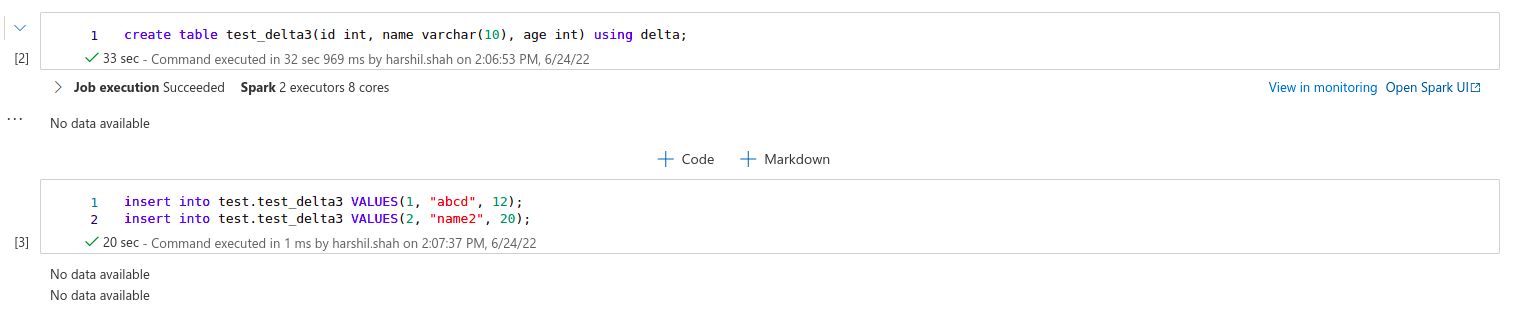
After that I want to remove all records from that table as well as from primary storage also so, I have used the "TRUNCATE TABLE" query but it gives me an error that TRUNCATE TABLE is not supported for v2 tables.

And the error stack is:
Error: TRUNCATE TABLE is not supported for v2 tables. org.apache.spark.sql.execution.datasources.v2.DataSourceV2Strategy.apply(DataSourceV2Strategy.scala:353) org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$1(QueryPlanner.scala:63) scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484) scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490) scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:489) org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:93) org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:68) org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$3(QueryPlanner.scala:78) scala.collection.TraversableOnce.$anonfun$foldLeft$1(TraversableOnce.scala:162) scala.collection.TraversableOnce.$anonfun$foldLeft$1$adapted(TraversableOnce.scala:162) scala.collection.Iterator.foreach(Iterator.scala:941) scala.collection.Iterator.foreach$(Iterator.scala:941) scala.collection.AbstractIterator.foreach(Iterator.scala:1429) scala.collection.TraversableOnce.foldLeft(TraversableOnce.scala:162) scala.collection.TraversableOnce.foldLeft$(TraversableOnce.scala:160) scala.collection.AbstractIterator.foldLeft(Iterator.scala:1429) org.apache.spark.sql.catalyst.planning.QueryPlanner.$anonfun$plan$2(QueryPlanner.scala:75) scala.collection.Iterator$$anon$11.nextCur(Iterator.scala:484) scala.collection.Iterator$$anon$11.hasNext(Iterator.scala:490) org.apache.spark.sql.catalyst.planning.QueryPlanner.plan(QueryPlanner.scala:93) org.apache.spark.sql.execution.SparkStrategies.plan(SparkStrategies.scala:68) org.apache.spark.sql.execution.QueryExecution$.createSparkPlan(QueryExecution.scala:420) org.apache.spark.sql.execution.QueryExecution.$anonfun$sparkPlan$4(QueryExecution.scala:115) org.apache.spark.sql.catalyst.QueryPlanningTracker.measurePhase(QueryPlanningTracker.scala:120) org.apache.spark.sql.execution.QueryExecution.$anonfun$executePhase$1(QueryExecution.scala:159) org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) org.apache.spark.sql.execution.QueryExecution.executePhase(QueryExecution.scala:159) org.apache.spark.sql.execution.QueryExecution.sparkPlan$lzycompute(QueryExecution.scala:115) org.apache.spark.sql.execution.QueryExecution.sparkPlan(QueryExecution.scala:99) org.apache.spark.sql.execution.QueryExecution.assertSparkPlanned(QueryExecution.scala:119) org.apache.spark.sql.execution.QueryExecution.executedPlan$lzycompute(QueryExecution.scala:126) org.apache.spark.sql.execution.QueryExecution.executedPlan(QueryExecution.scala:123) org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$5(SQLExecution.scala:105) org.apache.spark.sql.execution.SQLExecution$.withSQLConfPropagated(SQLExecution.scala:181) org.apache.spark.sql.execution.SQLExecution$.$anonfun$withNewExecutionId$1(SQLExecution.scala:94) org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) org.apache.spark.sql.execution.SQLExecution$.withNewExecutionId(SQLExecution.scala:68) org.apache.spark.sql.Dataset.withAction(Dataset.scala:3685) org.apache.spark.sql.Dataset.<init>(Dataset.scala:228) org.apache.spark.sql.Dataset$.$anonfun$ofRows$2(Dataset.scala:99) org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) org.apache.spark.sql.Dataset$.ofRows(Dataset.scala:96) org.apache.spark.sql.SparkSession.$anonfun$sql$1(SparkSession.scala:618) org.apache.spark.sql.SparkSession.withActive(SparkSession.scala:775) org.apache.spark.sql.SparkSession.sql(SparkSession.scala:613)
So, any alternate approach to remove data from the delta table
And in Databricks this query is working properly.
Thank you for giving a solution.

Hi @Anonymous ,
Welcome to Microsoft Q&A platform and thanks for posting your question here.
As I understand your query, you have created delta table in Azure synapse workspace and are trying to truncate the table , however, it's throwing an error. Please let me know if my understanding about your query is incorrect.
When you create a delta table in Azure Synapse , it's doesn't create an actual physical table . It actually creates corresponding files in ADLS .
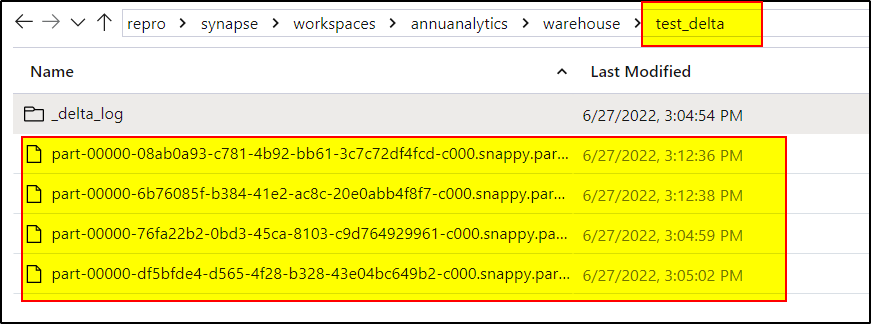
Truncate is not possible for these delta tables. You can either use delete from test_delta to remove the table content or drop table test_delta which will actually delete the folder itself and inturn delete the data as well.
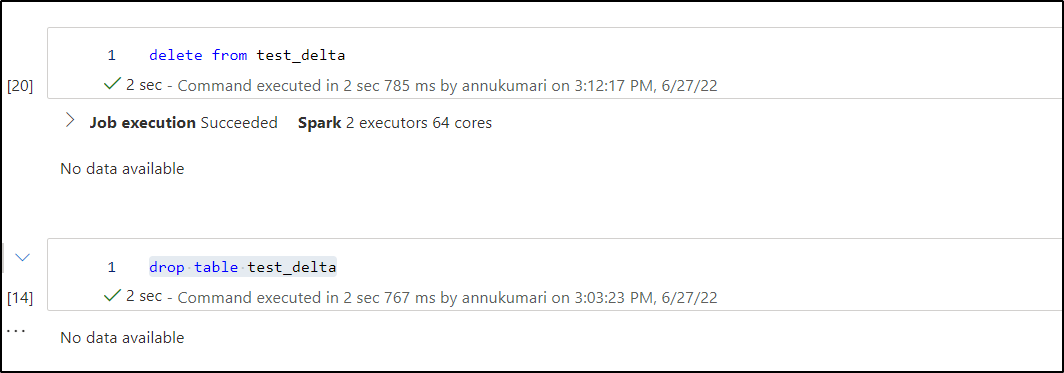
Kindly refer to this documentation for more details : Delete from a table
Note: 'delete' removes the data from the latest version of the Delta table but does not remove it from the physical storage until the old versions are explicitly vacuumed. See vacuum for details.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Thank you for your answer.
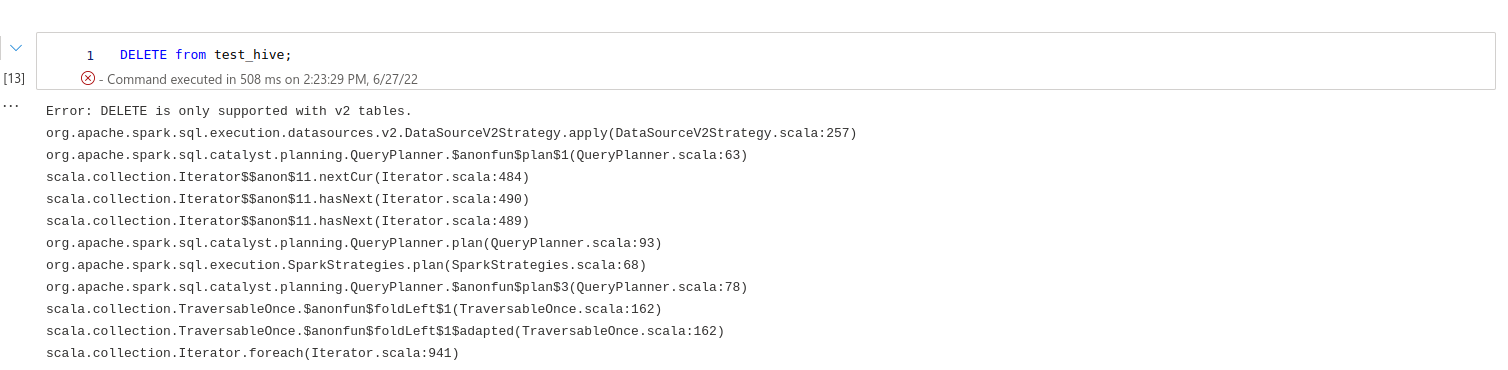
Yeah, delete statement will help me but the truncate query is faster than delete query. And one more thing that hive table is also saved in ADLS, why truncate is working with hive tables not with delta?
And when I run delete query with hive table the same error happens