Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EC%3C/text%3E%3C/svg%3E)
Hello,
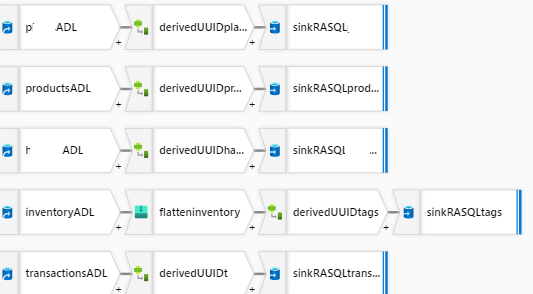
I am using both Data Flows and Data Copies to ETL JSONs from GET/HTTPs.
They will end up in Azure SQL DB staging tables.
A data scientist will later move them to production/reports.
I have access to the API website and templates/examples.
Some of the data is nested, some can almost be copied straight to the DB.
However, the nested tables often have no information, making it difficult to manipulate expected future information.
My questions. (Tables/schema are assumed to be static)
Thank you for any and all help!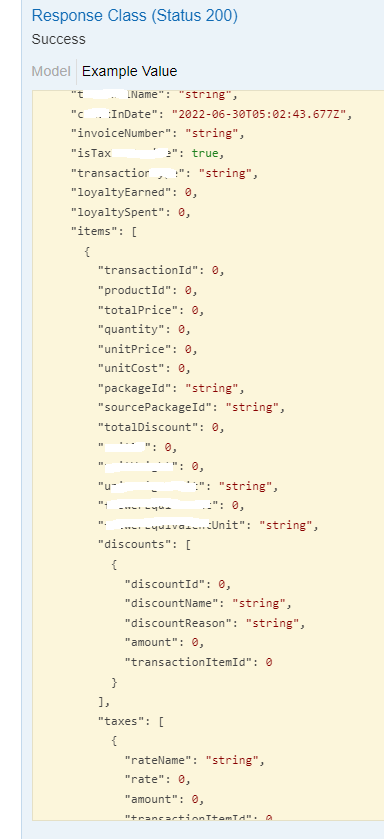
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EMM%3C/text%3E%3C/svg%3E)
Hello @Chris and welcome to Microsoft Q&A.
As I understand, you are looking for advice on both Data Flow and Copy activity for HTTP(JSON) -> Azure SQL DB, or REST -> Azure SQL DB. The schema is not expected to change, and is likely to contain empty or null data, possible the entire thing. The form these will take is another question. First, I will provide some baseline info.
First of all, the Copy Activity can only flatten one level of nesting. For more than one level, you need to either use Data Flow, multiple Copy Activities, or do it SQL side.
Copy Activity supports HTTP data set type, but Data Flow does not support HTTP data set type. Both support REST connector. REST connector expects JSON, or in the case of Data Flow, JSON or XML.
If you need to do pagination, REST is better than HTTP usually.
Data Flow provides more flexibility on null or missing fields than Copy Activity does.
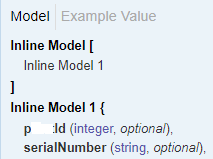
If you want all columns (even if missing from source data) to be present in your dataflow, then the easiest way is to specify them in the Dataset schema.
What you want to do, is when you make the dataset (or afterwards) import the schema from that template file. Screenshot below on a JSON dataset.
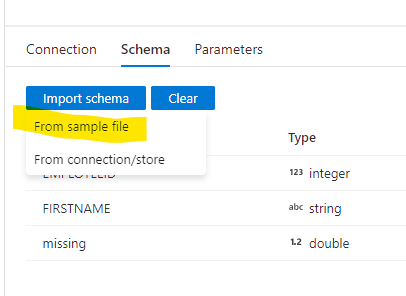
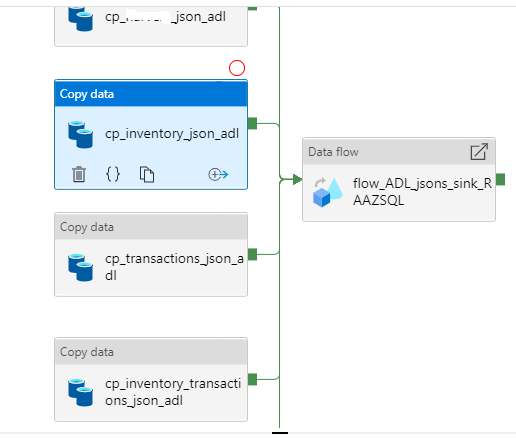
Unfortunately, the REST connector doesn't have a schema to work with. This is probably what brought you here. You mentioned you are using both Data Flow and Copy Activity. Are you perhaps doing a 2-step process?
HTTP --copy_activity--> Blob (JSON) then Blob (JSON) --Data_Flow--> SQL
This would allow us to make use of the schema in the JSON dataset as demonstrated below:
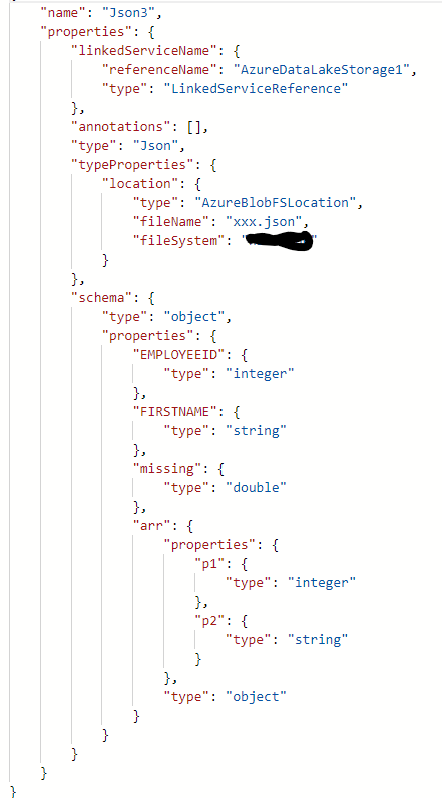
Here I have taken a JSON file (in my blob storage) which only has a couple basic properties. (Data is made up)

Then I altered its schema (manually) to add in complex properties which do not exist in the data.
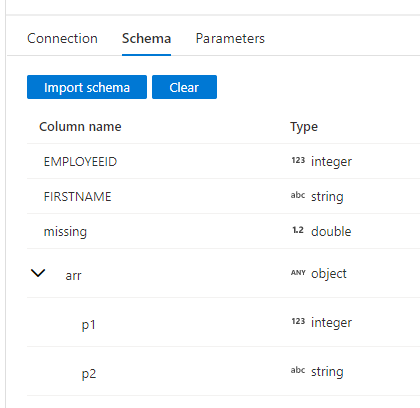
This is then reflected in the Dataflow, and shows up as nulls.
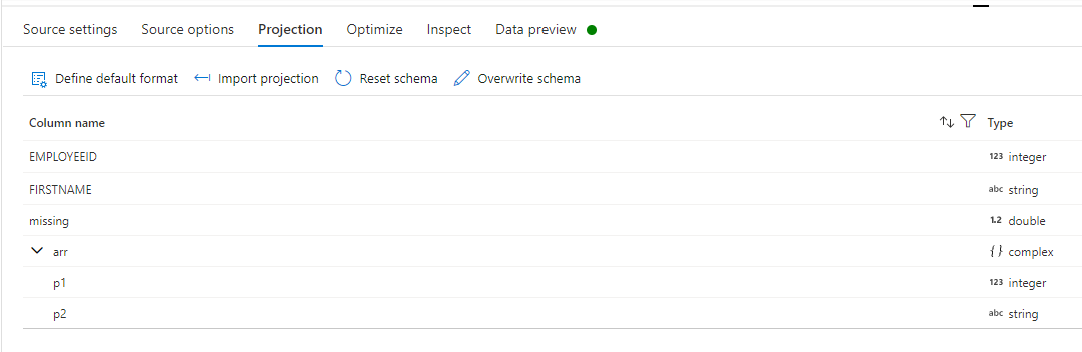
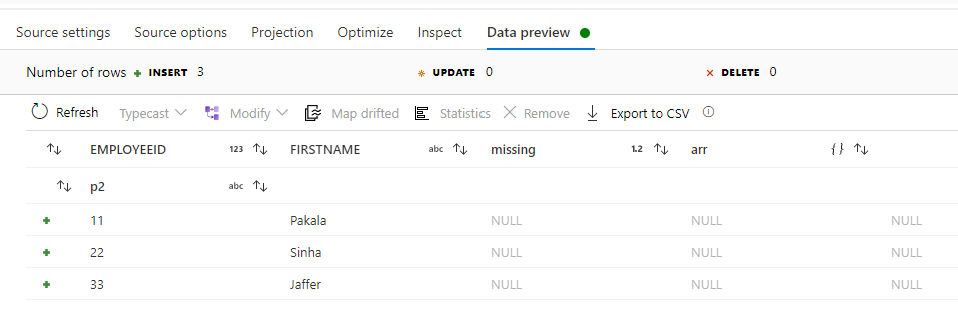
Please do let me if you have any queries.
Thanks
Martin
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how