Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESG%3C/text%3E%3C/svg%3E)
Hi all clever people out there.
Assume I have a JSON file with the following structure
{
"Node1": [
{
"id": "xxxxxxxxxx",
"name": "The name",
"Sub-node1": [
{
"Type": "The type",
"id": "xxxxxxxxxxxxxx",
"users": [
{
"UserType": "The main person",
"UserRights": "Owner",
"UPN": "******@yyyyyy.com"
}
]
},
{
"Type": "The type",
"id": "yyyyyyyyyyyyyyy",
"users": [
{
"UserType": "The main main person",
"UserRights": "Admin",
"UPN": "******@yyyyyy.com"
}
]
}
],
"Sub-node2": [
{
"Type": "The type",
"id": "xxxyxxxxxyxxxxxx",
"users": [
{
"UserType": "The main person",
"UserRights": "Admin",
"UPN": "******@yyyyyy.com"
}
]
},
{
"Type": "The type",
"id": "xxxxxxxxxxxyxxyx",
"users": [
{
"UserType": "The main main person",
"UserRights": "Viewer",
"UPN": "******@yyyyyy.com"
}
]
}
],
"users": [
{
"UserType": "Superman",
"UserRights": "Admin",
"UPN": "******@yyyyyy.com"
}
]
}
}
Notice that there is a users node directly under the main node (Node1) and also in each sub-node. Normally I would flatten the JSON in Serverless using CROSS APPLY. Something like this:
SELECT
Node1Id, Node1_Name, Sub-node1Type, Sub-node1_id, Sub-node2Type, Sub-node2_id, UserType, UserRights, UPN
FROM
OPENROWSET(
BULK 'https://xxxxxxxx.dfs.core.windows.net/root/yyyyyyyy/zzzzzzzz/*/*/*/*/*',
FORMAT = 'CSV',
FIELDQUOTE = '0x0b',
FIELDTERMINATOR ='0x0b'
)
WITH (
jsonContent varchar(MAX)
) AS [rows]
CROSS APPLY openjson (jsonContent)
WITH (
Node1 NVARCHAR(MAX) AS JSON
)
CROSS APPLY openjson (Node1)
WITH (
Node1Id VARCHAR(50) '$.id',
Node1_Name VARCHAR(50) '$.name',
Sub-node1 NVARCHAR(MAX) AS JSON,
Sub-node2 NVARCHAR(MAX) AS JSON,
users NVARCHAR(MAX) AS JSON
)
CROSS APPLY openjson (Sub-node1)
WITH (
Sub-node1Type varchar(255) '$.Type',
Sub-node1_id varchar(255) '$.id',
users NVARCHAR(MAX) AS JSON
)
CROSS APPLY openjson (Sub-node2)
WITH (
Sub-node2Type varchar(255) '$.Type',
Sub-node2_id varchar(255) '$.id',
users NVARCHAR(MAX) AS JSON
)
CROSS APPLY openjson (users)
WITH (
UserType varchar(50) '$.UserType',
UserRights NVARCHAR(100) '$.UserRights',
UPN varchar(100) '$.UPN',
)
)
With this method I can only get one for the users nodes out as you cannot CROSS APPLY the same named node multiple times. I cannot seem to figure out a way to name the node differently when I reference it as JSON in the sub-node CROSS APPLY and I cannot figure out a way to reference users as using some kind of path ('$.sub-node1.users' was my initial thought).
Does anyone know if it´s possible to get all the different User nodes from the main node and all the sub-nodes in a single SELECT (I have done it in multiple selects with one sub-node at a time)?
Would love to hear everyone's input.
Ásgeir
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EJP%3C/text%3E%3C/svg%3E)
Instead of multiple CROSS APPLY that will cross-join all nested sub-arrays, try tu use a single top-level cross apply with UNION ALL that will concatenate nested sub-arrays - something like:
SELECT *
FROM
OPENROWSET(
BULK 'https://xxxxxxxx.dfs.core.windows.net/root/yyyyyyyy/zzzzzzzz/*/*/*/*/*',
FORMAT = 'CSV',
FIELDQUOTE = '0x0b',
FIELDTERMINATOR ='0x0b'
)
WITH (
value varchar(MAX)
) AS [rows]
CROSS APPLY (
SELECT [Sub-node1.users].* FROM OPENJSON(value, '$."Sub-node1"') [Sub-node1]
CROSS APPLY OPENJSON([Sub-node1].value, '$.users')
WITH(UserType NVARCHAR(100), UserRights NVARCHAR(100),UPN NVARCHAR(100))
as [Sub-node1.users]
UNION ALL
SELECT [Sub-node2.users].* FROM OPENJSON(value, '$."Sub-node2"') AS [Sub-node2]
CROSS APPLY OPENJSON([Sub-node2].value, '$.users')
WITH(UserType NVARCHAR(100), UserRights NVARCHAR(100),UPN NVARCHAR(100))
as [Sub-node2.users]
UNION ALL
SELECT users.* FROM OPENJSON(value, '$."users"')
WITH(UserType NVARCHAR(100), UserRights NVARCHAR(100),UPN NVARCHAR(100))
as[users]
) as users
Thanks Jovan
I managed to use what you suggested and it works for me.
/Ásgeir

Hi @Ásgeir Gunnarsson ,
Thankyou for using Microsoft Q&A platform and thanks for posting your question.
As I understand your query, you are trying to flatten the JSON data. To achieve the same , you are using Synapse notebook to write the query. Please let me know if that's not the case.
You can consider using Flatten transformation in Mapping Dataflow to achieve the requirement.
To know more about the implementation , kindly watch : https://www.youtube.com/watch?v=zrjYg2_2Y9I
Hi Anna
I´m not using a notebook for it. I´m trying to use Serveless Pool. I´m trying to not use Mapping DataFlows or Spark for this. My aim is to use Pipelines to ingest the data from a web service and then use Serverless pools to shape it. Basically I´m trying to create a simple, cheap and generic solution.
The code I showed is just t-sql in Serverless. I´m hoping someone can help.
Ásgeir
Hi @Ásgeir Gunnarsson ,
I understand you are trying to flatten the JSON data using T-SQL script. However, As I can see the data is having nested arrays which is difficult to be flattened using T-SQL. You can use Dataflow which is UI based Data transformation tool in ADF and Synapse capable of flattening multi-level nested JSON , here is how you can achieve the above requirement using mapping dataFlow.
1. Create a dataset pointing to the JSON file in your storage account, use the same in source transformation.
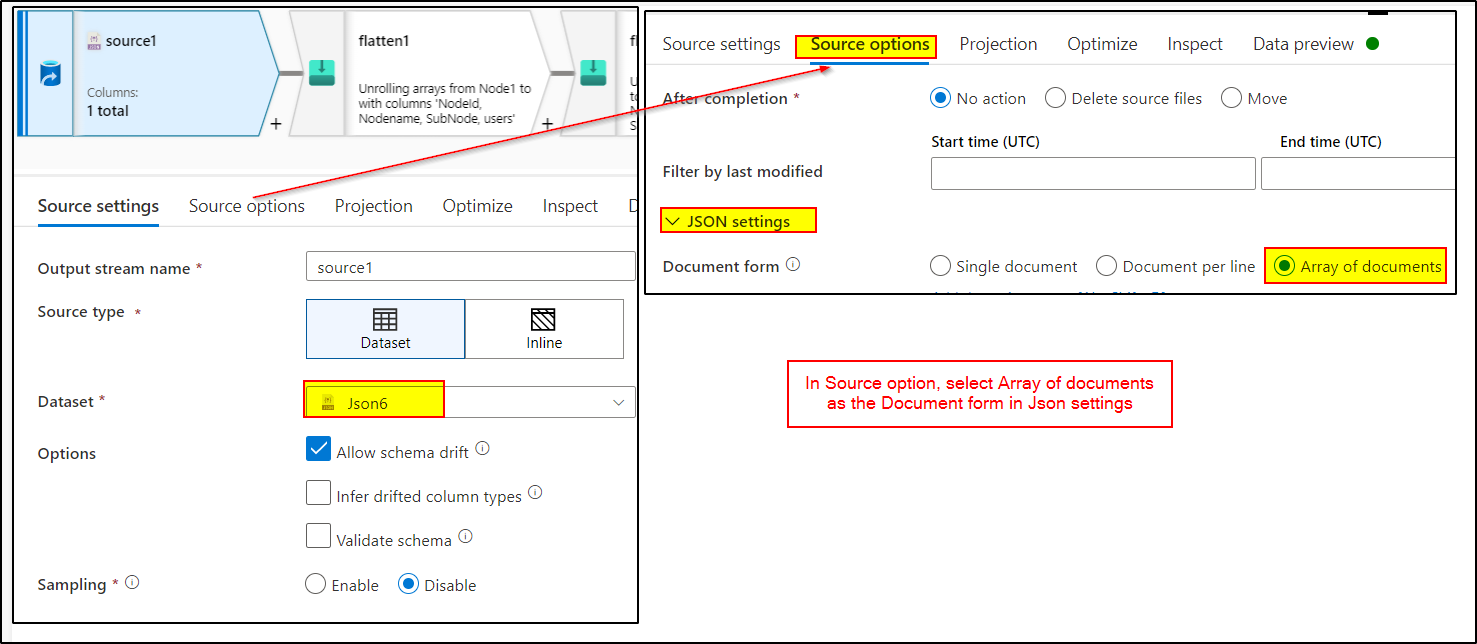
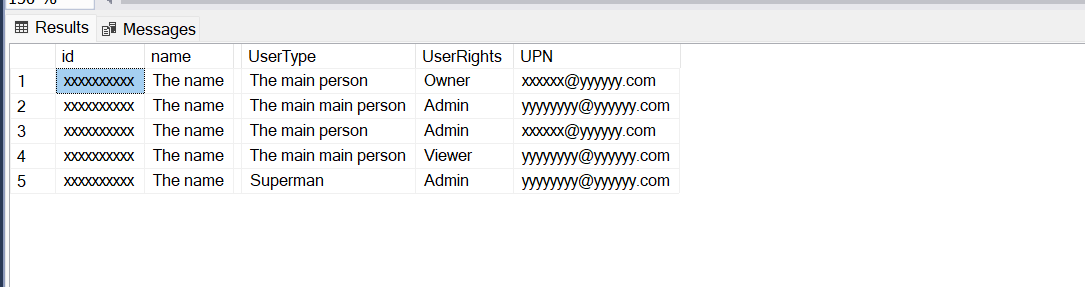
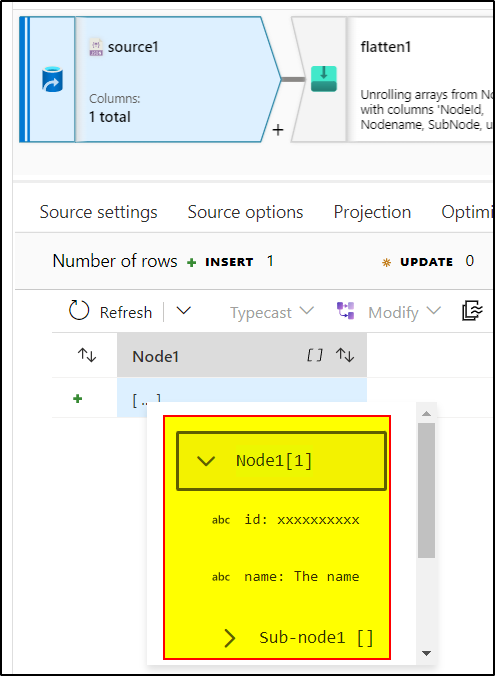 2. Use Flatten transformation to unroll the 'Node1' array.
2. Use Flatten transformation to unroll the 'Node1' array. 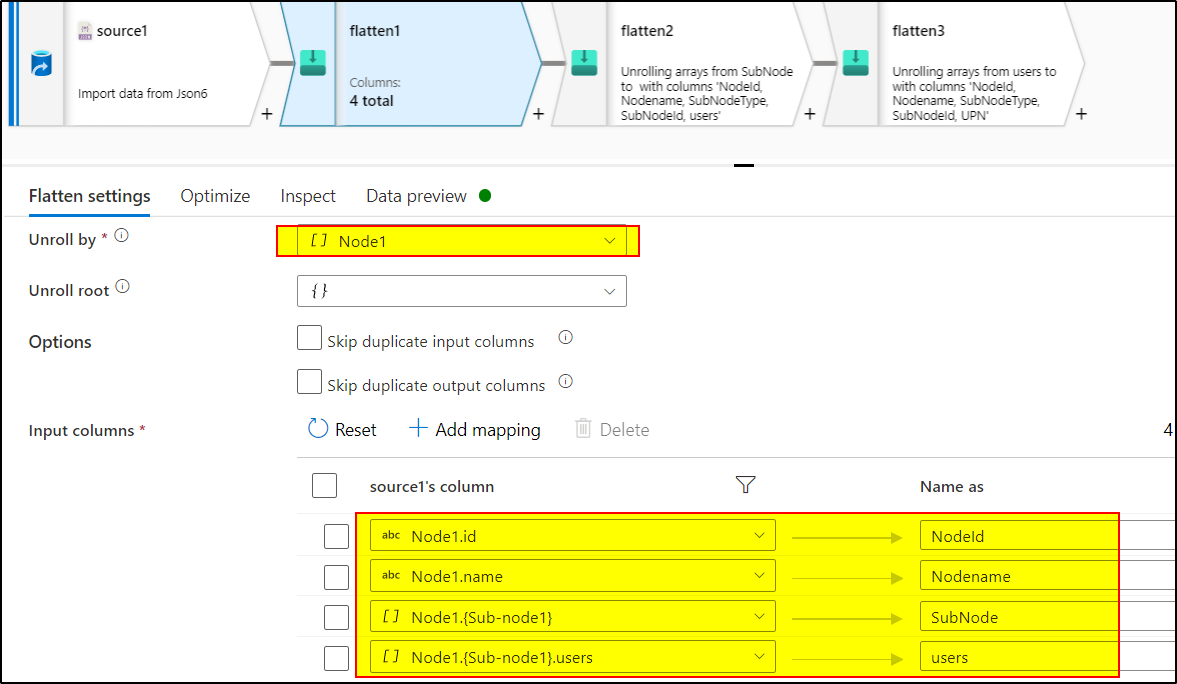
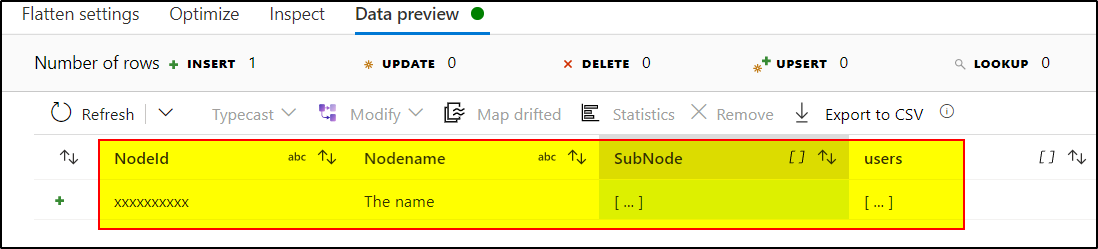
3.
Use another Flatten transformation to unroll the nested array 'SubNode'
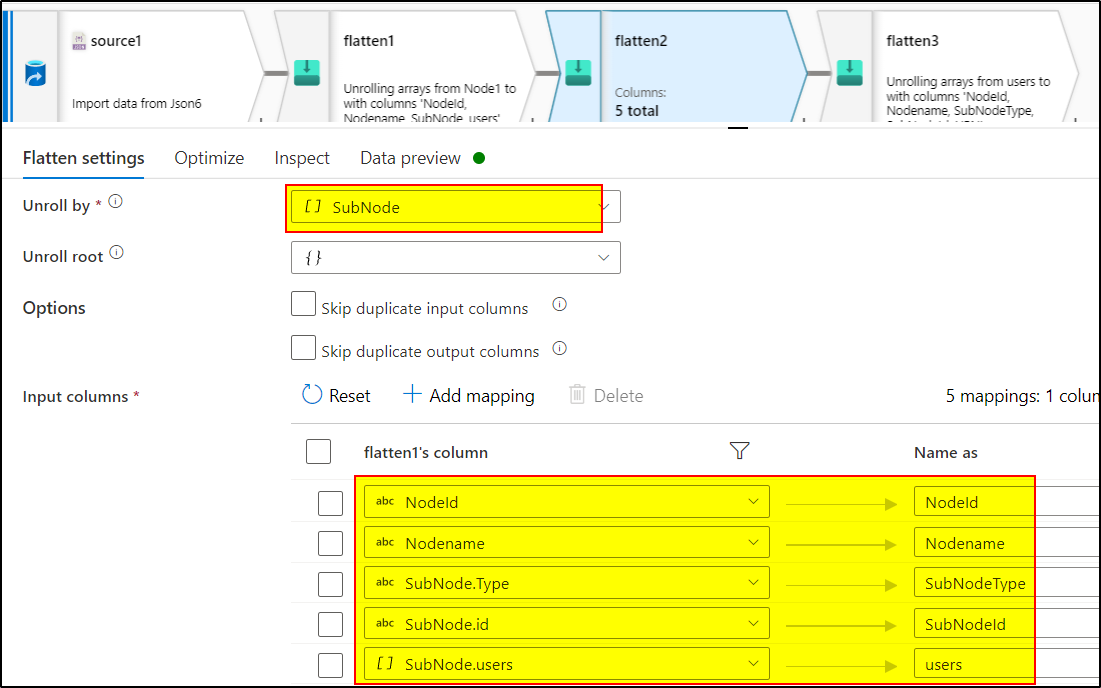
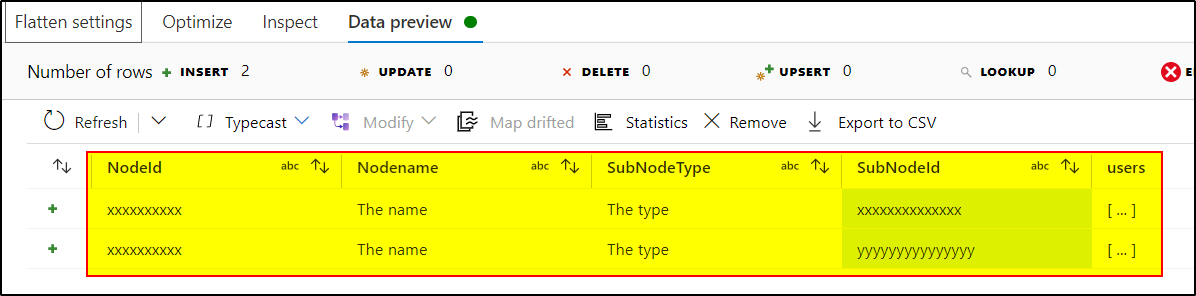
4.
Use another Flatten transformation to unroll the nested array 'Users'
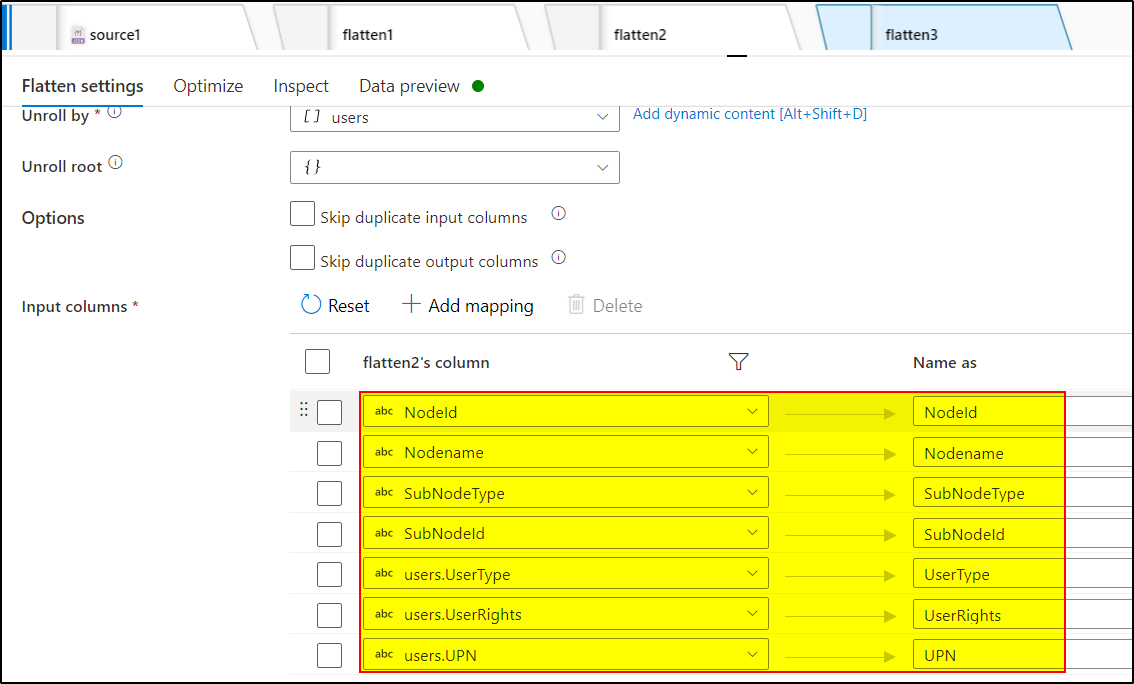

5. Add a sink transformation and point the dataset to the target datastore and load it by running the pipeline after calling dataflow activity.
Hope this will help. Please let us know if any further queries.
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @Ásgeir Gunnarsson ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.
I understand what you are trying to do is find an alternative but that is not what I´m looking for. I know I can use other tools and ways than t-sql but I´m not interested in them. The only thing I´m interested in is a way to do this in Synapse Serverless. If that is not possible then so be it. Then I will use one of the countless alternatives I have including how to do this in t-sql but in multiple queries instead of one.
I will still hope that at some point someone really good at serverless or t-sql will come into this thread and answer the question :-)