Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
11,624 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EA%3C/text%3E%3C/svg%3E)
The self hosted integration IR that we are using for copy activity is using all of the memory on the machine on which IR is hosted. It is not releasing memory. I am not aware that it would consume memory of the machine. Doesn't it use only CPU? Can you please confirm if SHIR uses memory and doesn't release it?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello @Anonymous ,
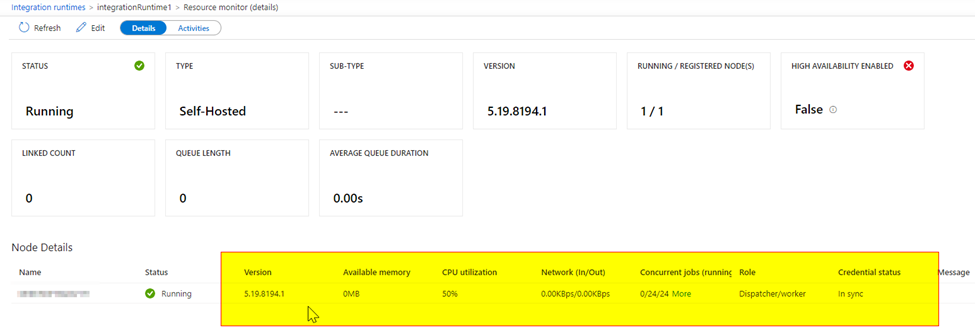
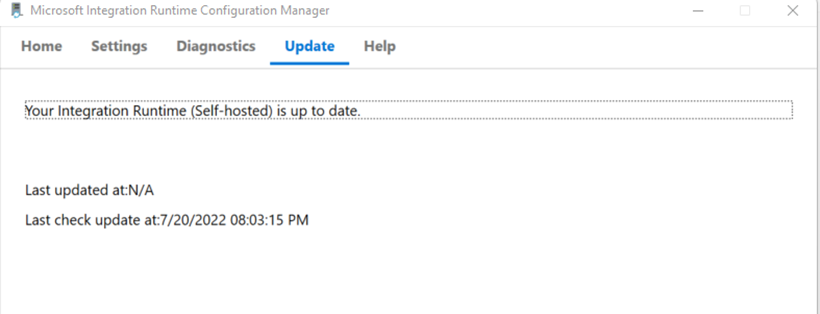
Can you please let me know when did you notice the issue first? The latest version is 5.19.8194.1. Can you please also confirm you are running on the latest version?
Hello @Anonymous ,
I am just checking in to see if you have any updates here. If you need any further help, please let us know.
@Bhargava-MSFT - We are using 5.17.8189.1 IR. Will there be any issues if we not using latest IR ?
Hello @Anonymous ,
Thank you for the response. It is always recommended to update the self-hosted IR to the latest version.
Also, Self-hosted IR needs at least 8GB of RAM and 80GB of available hard drive space for optimal performance. Installing the Self Hosted IR on a machine different than one that hosts the on-premises data source is recommended.
In case, If the above steps didn't help, I would suggest opening a support case for a deeper investigation. If you don't have a support plan, please let me know. I can provide you one-time free support request.
@Bhargava-MSFT
Got it. Currently we have it installed on the same server as data one as we do not have other servers available. But can you advise on the concurrent connections limit. How does that work ?
I was not limiting the concurrent connections and the CPU utilization is going upto 100%.
Hi @Anonymous ,
Sorry, with the latest version the 'limit concurrent jobs' has been increased to 96. Earlier it was 24.
While setting this value, you will need to consider the number of CPU cores and the amount of RAM of the machine. If you have more cores and more memory, you can set this value to a high number.
and you can scale out by increasing the number of nodes. If you increase the number of nodes, the concurrent jobs limit will be the sum of all available nodes.
for ex: if you add 3 nodes to your SHIR, and set '10' in the 'limit concurrent jobs' on each node, then you will get a maximum of 30 concurrent jobs.
We don't recommend a specific number here. It all depends on your workload and cpu/memory of your nodes.
one more advantage of adding another node is 'high availability'
Hope this makes sense to you. Please let me know if you have any further questions.
Hi @Anonymous ,
I am just checking in to see if you have any further questions here.
No, thanks for the details @Bhargava-MSFT
Hello @Anonymous ,
Thank you for the reply. If you have any further questions, please don't hesitate to contact us.
Hello @Anonymous ,
Welcome to the Microsoft Q&A platform, and thanks for posting your query.
Are you seeing any errors when you experiencing high memory usage? Here are a few things I want you to check from your end.
If your memory and CPU are consistently high then it could be due to running more pipelines using self hosted IR. If you see any momentary high memory usage it could be due to a large volume of concurrent activity.
1) Check the settings for limit concurrent jobs. The max limit is 96.
2) Check the network throughput
3) Check if you have the latest version of self hosted IR installed.
4) If you are using single node for self hosted IR, consider adding 2nd node
5) Check the resource usage and concurrent activity execution on the IR node. Adjust the internal and trigger time of activity runs to avoid too much execution on a single IR node at the same time.
6) Look into add more memory
Here is the general troubleshooting self-hosted integration runtime document.
While setting the concurrent connection value, will need to consider the number of CPU cores and the amount of RAM of the machine. If we have more cores and more memory, we can set this value to a high number.
and we can scale out by increasing the number of nodes. If we increase the number of nodes, the concurrent jobs limit will be the sum of all available nodes.
for ex: if we add 3 nodes to your SHIR, and set '10' in the 'limit concurrent jobs' on each node, then we will get a maximum of 30 concurrent jobs.
There is no specific recommend number here. It all depends on workload and cpu/memory of your nodes.
one more advantage of adding another node is 'high availability'
Please let me know if you have any further questions.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EFP%3C/text%3E%3C/svg%3E)
On azure datafactory pipeline, we have this error :
Error: Une panne s'est produite côté « Source ». ErrorCode=SystemErrorOutOfMemory,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Échec d'une tâche avec insuffisance de mémoire
On host of self hosted integration runtime this event is displayed : Microsoft-Windows-Resource-Exhaustion-Detector
Windows successfully diagnosed a low virtual memory condition. The following programs consumed the most virtual memory: diawp.exe (9352) consumed 2760433664 bytes, diawp.exe (12808) consumed 2667466752 bytes, and diawp.exe (3468) consumed 2654556160 bytes.
The Adf pipeline has a looping copy activity, with several small files. (max 3MB)
If we check memory usage, physical memory (working set) is 50%, while virtual memory (commit load) is 100%.
The azure runtime monitoring does not show this load, only a drop from 18 to 16 GB .. :(
Why are commits higher than working set?
Why does the process need this memory and not free it more frequently?
Is it possible to configure the commit/working ratio?
Is it possible to set a max in order to make the treatment more stable?
What is the recommended page file configuration? (here defined by the system on the C: partition).