Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ESA%3C/text%3E%3C/svg%3E)
I have 7MB Normalised JSON file(Array of objects). Created a data flow to perform parse and flatten operations and called this data flow by using pipeline.
When I am debug/trigger the pipeline to process 7MB file. It throwing me error "DF-Executor-OutOfMemoryError".
I was using Integration run time with
I surprised to see that it unable to process 7 MB file. When I tried with KB files it was able to process. Any suggestions ?

Hi @Srihari Adabala ,
Welcome to Microsoft Q&A platform and thanks for posting your question.
As I understand your query, you are trying to process a 7MB file using mapping dataflow, however, you are getting the following error : "DF-Executor-OutOfMemoryError" . Please let me know if my understanding is incorrect.
The cause behind this error as the error message suggests, is that "The cluster is running out of memory."
The recommended solution is to retry using an integration runtime with bigger core count and/or memory optimized compute type
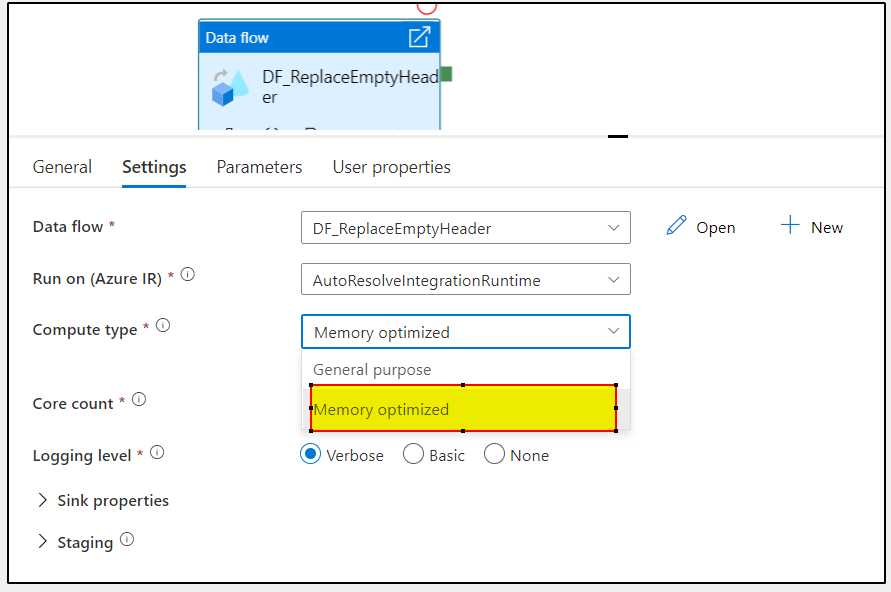
There are two available options for the type of Spark cluster to utilize: general purpose & memory optimized.
General purpose clusters are the default selection and will be ideal for most data flow workloads. These tend to be the best balance of performance and cost.
If your data flow has many joins and lookups, you may want to use a memory optimized cluster. Memory optimized clusters can store more data in memory and will minimize any out-of-memory errors you may get. Memory optimized have the highest price-point per core, but also tend to result in more successful pipelines. If you experience any out of memory errors when executing data flows, switch to a memory optimized Azure IR configuration.
Kindly check the following troubleshooting document : DF-Executor-OutOfMemoryError and Cluster type
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you.
button whenever the information provided helps you.
Hi @Srihari Adabala ,
Just checking in to see if the above answer helped. Please do consider clicking Accept Answer and Up-Vote for the same as accepted answers help community as well. If you have any further query do let us know.