Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDL%3C/text%3E%3C/svg%3E)
When running the sample code "Explore NYC Yellow Taxi Data using Spark" in a PySpark notebook the Spark Pool starts successfully but the code just hangs and eventually returns with the following all though it has also returned with different errors.
I'm guessing this has something to do with the fact out storage account is locked down to specific Virtual Networks and Specific IP addresses. I have followed the steps to create a Managed Private Endpoint which points to the storage account and I can see the storage account in Data Browser on the left in Synapse Studio. I have also used the PowerShell command Add-AzStorageAccountNetworkRule to enable AAD pass through as per link: https://azureaggregator.wordpress.com/2021/01/08/storage-configuration-for-external-table-is-not-accessible-while-query-on-serverless-2/ but nothing has worked. Can anyone help on this pleaase?
Error Returned
"Resolving access token for scope "https://storage.azure.com/.default" using identity of type "USER".
Credentials are not provided to access data from the source. Please sign in using identity with required permission granted.
Interactive sign-in timeout: 120 sec.
To change the sign-in tenant, restart the session with tenant ID set to environment variable "AZUREML_DATA_ACCESS_TENANT_ID" before sign in.
To always use device code for interactive sign-in, set environment variable "AZUREML_DATA_ACCESS_USE_DEVICE_CODE" to "true".
To configure timeout, set environment variable "AZUREML_DATA_ACCESS_INTERACT_TIMEOUT" to the number of seconds."
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBM%3C/text%3E%3C/svg%3E)
Hello @David Leach ,
Thanks for the question and using MS Q&A platform.
Please check if your Synapse workspace service principal has RBAC- "Storage blob data contributor" access on the storage account.
You can provide access from the storage account IAM page.
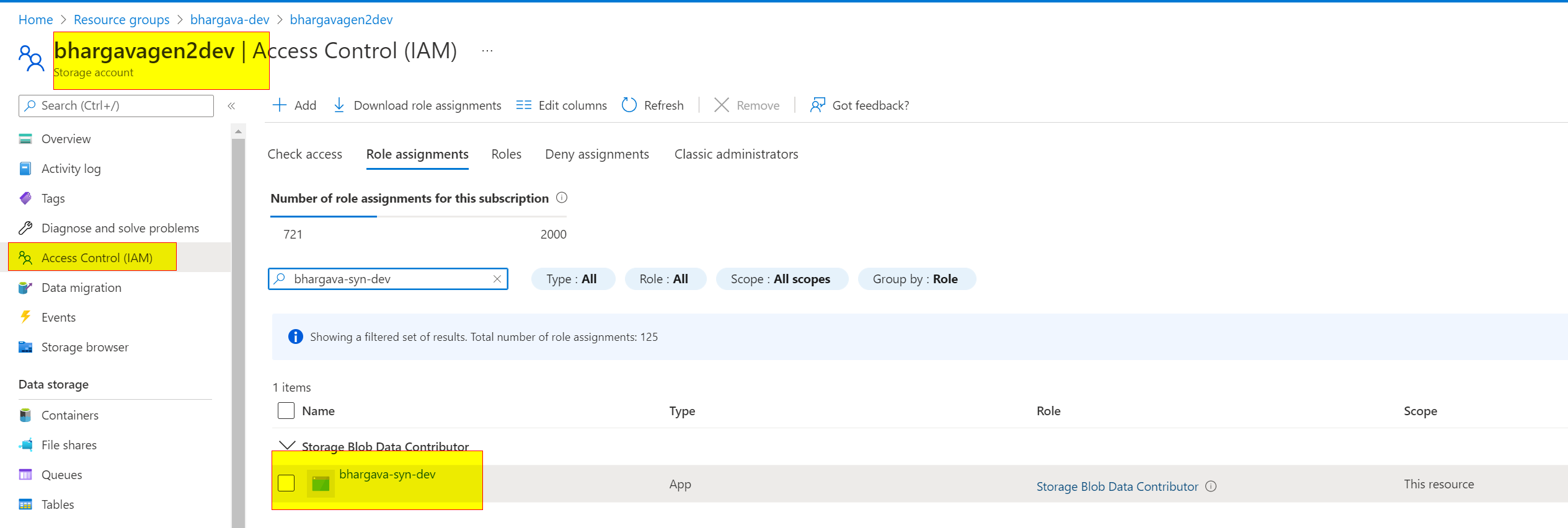
also, can you Grant your Azure Synapse workspace access to your secure storage account as a trusted Azure service?
I hope this helps.
Hello @David Leach ,
I am just checking in to see if you have any further questions here.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @David Leach ,
I am just checking in to see if you have any further questions here.