Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
5,373 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EGC%3C/text%3E%3C/svg%3E)
Hi ,
I am Trying to load data from Delta table to synapse table (sql dedicated pool) from databricks using synapse connector.
I am having table schema created already in Synapse with specific datatype for Column.
When i am writing after that schema of table is changing like previously it was tinyint now it is int
Note - .mode(overwrite) i am using while writing
How to load data into Synapse table by preserving the original datatype whatever is there before loading.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @gajanan choure ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is why the schema on the Synapase is getting changed , please do let us know if its not accurate.
I have tried the below and I do not see this happening .
This is what I did tried .
%sql
CREATE TABLE student101 (name VARCHAR(64), address VARCHAR(64), student_id tinyint )
USING Delta PARTITIONED BY (student_id);
2.Insert data
%sql
INSERT INTO student101 VALUES
('Amy Smith', '123 Park Ave, San Jose', 11);
CREATE TABLE student101 (name VARCHAR(64), address VARCHAR(64), student_id tinyint )
Please beware that the student_id is tinyint here .
new_df = spark.sql("select * from student101")
new_df.show()sc._jsc.hadoopConfiguration().set(
"fs.azure.account.key.XXXX.blob.core.windows.net",
"YYY")
spark.conf.set(
"fs.azure.account.key.XXX.blob.core.windows.net",
"ZZZ")Get some data from an Azure Synapse table.
new_df.write \
.mode("overwrite")\
.format("com.databricks.spark.sqldw") \
.option("url", "jdbc:sqlserver://analyticsshared.database.windows.net:1433;database=synapse;user=CCCC@X ;password=XXXXX;encrypt=true;trustServerCertificate=false;hostNameInCertificate=*.database.windows.net;loginTimeout=30;") \
.option("tempDir", "wasbs://data@xxxxxxxxxxxxx .blob.core.windows.net/input") \
.option("forwardSparkAzureStorageCredentials", "true") \
.option("dbTable", "student101") \
.save()
Please do let me if you have any queries.
Thanks
Himanshu
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hi Himanshu ,
Thank you for your response.
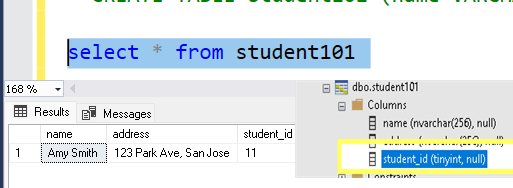
When you created table on Synapse side
Name datatype is varchar(64)
Address datatype is Varchar (64)
But when we overwrite it is changing to nvarchar(256)
For all nvarchar fields as in your pic.
And the constraints are gone means Not null is changing to null (this one I tried)
How do we keep constraints and Original length and datatype preserved in overwrite mode.
Second question- how we implement merge/upsert as only append, overwrite are available.( If you have any code /logic) pls share