Azure Synapse Analytics
An Azure analytics service that brings together data integration, enterprise data warehousing, and big data analytics. Previously known as Azure SQL Data Warehouse.
4,696 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EEA%3C/text%3E%3C/svg%3E)
Hello,
I want to create (via code in Azure Synapse notebook) a folder hierarchy based on columns year, month, day of my dataframe, as is depicted in the screenshot.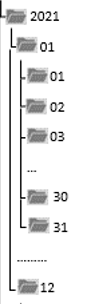
I read that the Pyspark method PartitionBy() is not recommended for use with multiple columns so it's not the best practise to create such a taxonomy. Why is that?
Thanks in advance!
Hello @HimanshuSinha-msft ,
Let's say that I will proceed using the method PartitionBy() to create the folder hierarchy, this method creates the file '_SUCCESS' as well as the folder '_temporary' in the first level of my taxonomy (where all the 'Year=' folders are stored) and I don't want them there. Is it ok if I delete both of them or will I have any issues after their deletion?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @eugenia apostolopoulou ,
Delettion should be fine .
Thanks
Himanshu
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @eugenia apostolopoulou ,
Thanks for the question and using MS Q&A platform.
As we understand the ask here is how to partiion in spark , please do let us know if its not accurate.
I read that the Pyspark method PartitionBy() is not recommended
It will be great if you can point me to the document here . I know that partitioning too less or too much can effect the performance .
On looking that the folder structure . I think you can go with the below code .
jdbc_df1 = jdbc_df.withColumn("NewDate",to_date("DateOpened"))
jdbc_df1.show()
jdbc_df1.write.option("header",True) \
.partitionBy("NewDate") \
.mode("overwrite") \
.csv("/tmp/SomeFolder")

Please do let me if you have any queries.
Thanks
Himanshu
or upvote button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how