Training
Certification
Microsoft Certified: Azure AI Engineer Associate - Certifications
Design and implement an Azure AI solution using Azure AI services, Azure AI Search, and Azure Open AI.
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
The Azure AI Vision Image Analysis service can extract a wide variety of visual features from your images. For example, it can determine whether an image contains adult content, find specific brands or objects, or find human faces.
The latest version of Image Analysis, 4.0, which is now in general availability, has new features like synchronous OCR and people detection. We recommend you use this version going forward.
You can use Image Analysis through a client library SDK or by calling the REST API directly. Follow the quickstart to get started.
Or, you can try out the capabilities of Image Analysis quickly and easily in your browser using Vision Studio.
This documentation contains the following types of articles:
For a more structured approach, follow a Training module for Image Analysis.
Important
Select the Image Analysis API version that best fits your requirements.
| Version | Features available | Recommendation |
|---|---|---|
| version 4.0 | Read text, Captions, Dense captions, Tags, Object detection, Custom image classification / object detection, People, Smart crop | Better models; use version 4.0 if it supports your use case. |
| version 3.2 | Tags, Objects, Descriptions, Brands, Faces, Image type, Color scheme, Landmarks, Celebrities, Adult content, Smart crop | Wider range of features; use version 3.2 if your use case is not yet supported in version 4.0 |
We recommend you use the Image Analysis 4.0 API if it supports your use case. Use version 3.2 if your use case is not yet supported by 4.0.
You'll also need to use version 3.2 if you want to do image captioning and your Vision resource is outside the supported Azure regions. The image captioning feature in Image Analysis 4.0 is only supported in certain Azure regions. Image captioning in version 3.2 is available in all Azure AI Vision regions. See Region availability.
You can analyze images to provide insights about their visual features and characteristics. All of the features in this table are provided by the Analyze Image API. Follow a quickstart to get started.
| Name | Description | Concept page |
|---|---|---|
| Model customization (v4.0 preview only) (deprecated) | You can create and train custom models to do image classification or object detection. Bring your own images, label them with custom tags, and Image Analysis trains a model customized for your use case. | Model customization |
| Read text from images (v4.0 only) | Version 4.0 preview of Image Analysis offers the ability to extract readable text from images. Compared with the async Computer Vision 3.2 Read API, the new version offers the familiar Read OCR engine in a unified performance-enhanced synchronous API that makes it easy to get OCR along with other insights in a single API call. | OCR for images |
| Detect people in images (v4.0 only) | Version 4.0 of Image Analysis offers the ability to detect people appearing in images. The bounding box coordinates of each detected person are returned, along with a confidence score. | People detection |
| Generate image captions | Generate a caption of an image in human-readable language, using complete sentences. Computer Vision's algorithms generate captions based on the objects identified in the image. The version 4.0 image captioning model is a more advanced implementation and works with a wider range of input images. It's only available in the certain geographic regions. See Region availability. Version 4.0 also lets you use dense captioning, which generates detailed captions for individual objects that are found in the image. The API returns the bounding box coordinates (in pixels) of each object found in the image, plus a caption. You can use this functionality to generate descriptions of separate parts of an image. 
|
Generate image captions (v3.2) (v4.0) |
| Detect objects | Object detection is similar to tagging, but the API returns the bounding box coordinates for each tag applied. For example, if an image contains a dog, cat and person, the Detect operation lists those objects together with their coordinates in the image. You can use this functionality to process further relationships between the objects in an image. It also lets you know when there are multiple instances of the same tag in an image. 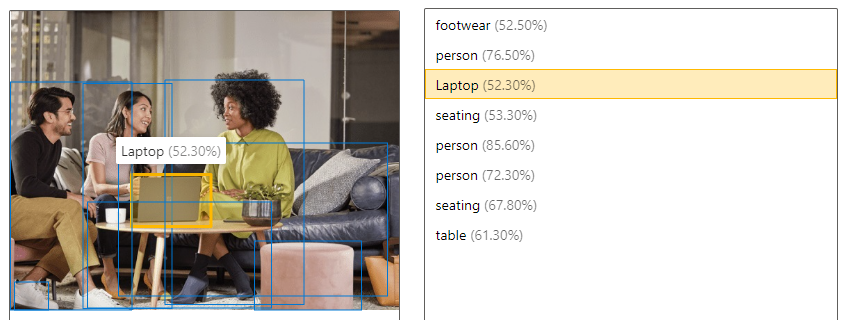
|
Detect objects (v3.2) (v4.0) |
| Tag visual features | Identify and tag visual features in an image, from a set of thousands of recognizable objects, living things, scenery, and actions. When the tags are ambiguous or not common knowledge, the API response provides hints to clarify the context of the tag. Tagging isn't limited to the main subject, such as a person in the foreground, but also includes the setting (indoor or outdoor), furniture, tools, plants, animals, accessories, gadgets, and so on.
|
Tag visual features (v3.2) (v4.0) |
| Get the area of interest / smart crop | Analyze the contents of an image to return the coordinates of the area of interest that matches a specified aspect ratio. Computer Vision returns the bounding box coordinates of the region, so the calling application can modify the original image as desired. The version 4.0 smart cropping model is a more advanced implementation and works with a wider range of input images. It's only available in certain geographic regions. See Region availability. |
Generate a thumbnail (v3.2) (v4.0 preview) |
| Detect brands (v3.2 only) | Identify commercial brands in images or videos from a database of thousands of global logos. You can use this feature, for example, to discover which brands are most popular on social media or most prevalent in media product placement. | Detect brands |
| Categorize an image (v3.2 only) | Identify and categorize an entire image, using a category taxonomy with parent/child hereditary hierarchies. Categories can be used alone, or with our new tagging models. Currently, English is the only supported language for tagging and categorizing images. |
Categorize an image |
| Detect faces (v3.2 only) | Detect faces in an image and provide information about each detected face. Azure AI Vision returns the coordinates, rectangle, gender, and age for each detected face. You can also use the dedicated Face API for these purposes. It provides more detailed analysis, such as facial identification and pose detection. |
Detect faces |
| Detect image types (v3.2 only) | Detect characteristics about an image, such as whether an image is a line drawing or the likelihood of whether an image is clip art. | Detect image types |
| Detect domain-specific content (v3.2 only) | Use domain models to detect and identify domain-specific content in an image, such as celebrities and landmarks. For example, if an image contains people, Azure AI Vision can use a domain model for celebrities to determine if the people detected in the image are known celebrities. | Detect domain-specific content |
| Detect the color scheme (v3.2 only) | Analyze color usage within an image. Azure AI Vision can determine whether an image is black & white or color and, for color images, identify the dominant and accent colors. | Detect the color scheme |
| Moderate content in images (v3.2 only) | You can use Azure AI Vision to detect adult content in an image and return confidence scores for different classifications. The threshold for flagging content can be set on a sliding scale to accommodate your preferences. | Detect adult content |
Important
This feature is now deprecated. On January 10, 2025, the Azure AI Vision Product Recognition and model customization features will be retired: after this date, API calls to these services will fail.
To maintain a smooth operation of your models, transition to Azure AI Custom Vision, which is now generally available. Custom Vision offers similar functionality to these retiring features.
The Product Recognition APIs let you analyze photos of shelves in a retail store. You can detect the presence or absence of products and get their bounding box coordinates. Use it in combination with model customization to train a model to identify your specific products. You can also compare Product Recognition results to your store's planogram document.
The multimodal embeddings APIs enable the vectorization of images and text queries. They convert images to coordinates in a multi-dimensional vector space. Then, incoming text queries can also be converted to vectors, and images can be matched to the text based on semantic closeness. This allows the user to search a set of images using text, without needing to use image tags or other metadata. Semantic closeness often produces better results in search.
The 2024-02-01 API includes a multi-lingual model that supports text search in 102 languages. The original English-only model is still available, but it cannot be combined with the new model in the same search index. If you vectorized text and images using the English-only model, these vectors won’t be compatible with multi-lingual text and image vectors.
These APIs are only available in certain geographic regions. See Region availability.
Image Analysis 4.0 (preview) offers the ability to remove the background of an image. This feature can either output an image of the detected foreground object with a transparent background, or a grayscale alpha matte image showing the opacity of the detected foreground object.
| Original image | With background removed | Alpha matte |
|---|---|---|

|

|

|
Image Analysis works on images that meet the following requirements:
Tip
Input requirements for multimodal embeddings are different and are listed in Multimodal embeddings
Different Image Analysis features are available in different languages. See the Language support page.
To use the Image Analysis APIs, you must create your Azure AI Vision resource in a supported region. The Image Analysis features are available in the following regions:
| Region | Analyze Image (minus 4.0 Captions) |
Analyze Image (including 4.0 Captions) |
Product Recognition | Multimodal embeddings | Background removal |
|---|---|---|---|---|---|
| East US | ✅ | ✅ | ✅ | ✅ | ✅ |
| West US | ✅ | ✅ | ✅ | ✅ | |
| West US 2 | ✅ | ✅ | ✅ | ||
| France Central | ✅ | ✅ | ✅ | ✅ | |
| North Europe | ✅ | ✅ | ✅ | ✅ | |
| West Europe | ✅ | ✅ | ✅ | ✅ | |
| Sweden Central | ✅ | ✅ | |||
| Switzerland North | ✅ | ✅ | |||
| Australia East | ✅ | ✅ | |||
| Southeast Asia | ✅ | ✅ | ✅ | ✅ | |
| East Asia | ✅ | ✅ | |||
| Korea Central | ✅ | ✅ | ✅ | ✅ | |
| Japan East | ✅ | ✅ |
As with all of the Azure AI services, developers using the Azure AI Vision service should be aware of Microsoft's policies on customer data. See the Azure AI services page on the Microsoft Trust Center to learn more.
Get started with Image Analysis by following the quickstart guide in your preferred development language and API version:
Training
Certification
Microsoft Certified: Azure AI Engineer Associate - Certifications
Design and implement an Azure AI solution using Azure AI services, Azure AI Search, and Azure Open AI.