Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
When running applications in Azure Kubernetes Service (AKS), you might need to actively increase or decrease the amount of compute resources in your cluster. As you change the number of application instances you have, you might need to change the number of underlying Kubernetes nodes. You might also need to provision a large number of other application instances.
This article introduces core AKS application scaling concepts, including manually scaling pods or nodes, using the Horizontal pod autoscaler, using the Cluster autoscaler, and integrating with Azure Container Instances (ACI).
Manually scale pods or nodes
You can manually scale replicas, or pods, and nodes to test how your application responds to a change in available resources and state. Manually scaling resources lets you define a set amount of resources to use, such as the number of nodes, to maintain a fixed cost. To manually scale, you define a replica or node count. The Kubernetes API then schedules the creation of more pods or the draining of nodes based on that replica or node count.
When you scale down nodes, the Kubernetes API calls the relevant Azure Compute API tied to the compute type used by your cluster. For example, for clusters built on Virtual Machine Scale Sets, the Virtual Machine Scale Sets API determines which nodes to remove. To learn more about how nodes are selected for removal on scale down, see the Virtual Machine Scale Sets FAQ.
To get started with manually scaling nodes, see manually scale nodes in an AKS cluster. To manually scale the number of pods, see kubectl scale command.
Horizontal pod autoscaler
Kubernetes uses the horizontal pod autoscaler (HPA) to monitor the resource demand and automatically scale the number of pods. By default, the HPA checks the Metrics API every 15 seconds for any required changes in replica count, while the Metrics API retrieves data from the Kubelet every 60 seconds. As a result, HPA is updated every 60 seconds. When changes are required, the number of replicas is scaled accordingly. HPA works with AKS clusters that have deployed Metrics Server for Kubernetes version 1.8 and higher.
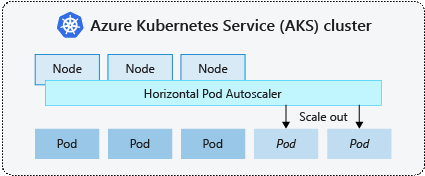
When you configure the HPA for a given deployment, you define the minimum and maximum number of replicas that can run. You also define the metric to monitor and base scaling decisions on, such as CPU usage.
To get started with the horizontal pod autoscaler in AKS, see Autoscale pods in AKS.
Cooldown of scaling events
As the HPA is effectively updated every 60 seconds, previous scale events might not have successfully completed before another check is made. This behavior could cause the HPA to change the number of replicas before the previous scale event could receive application workload and the resource demands to adjust accordingly.
To minimize race events, a delay value is set. This value defines how long the HPA must wait after a scale event before another scale event can be triggered. This behavior allows the new replica count to take effect and the Metrics API to reflect the distributed workload. There's no delay for scale-up events as of Kubernetes 1.12. However, the default delay on scale down events is 5 minutes.
Cluster autoscaler
To respond to changing pod demands, the Kubernetes cluster autoscaler adjusts the number of nodes based on the requested compute resources in the node pool. By default, the cluster autoscaler checks the Metrics API server every 10 seconds for any required changes in node count. If the cluster autoscaler determines that a change is required, the number of nodes in your AKS cluster is increased or decreased accordingly. The cluster autoscaler works with Kubernetes RBAC-enabled AKS clusters that run Kubernetes 1.10.x or higher.
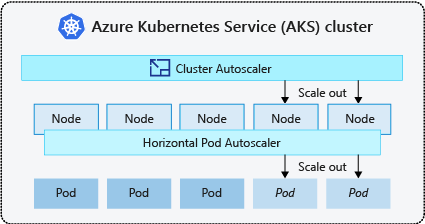
The cluster autoscaler is typically used alongside the horizontal pod autoscaler. When combined, the horizontal pod autoscaler increases or decreases the number of pods based on application demand, and the cluster autoscaler adjusts the number of nodes to run more pods.
To get started with the cluster autoscaler in AKS, see Cluster autoscaler on AKS.
Scale out events
If a node doesn't have sufficient compute resources to run a requested pod, that pod can't progress through the scheduling process. The pod can't start unless more compute resources are made available within the node pool.
When the cluster autoscaler notices pods that can't be scheduled because of node pool resource constraints, the number of nodes within the node pool is increased to provide extra compute resources. When the nodes are successfully deployed and available for use within the node pool, the pods are then scheduled to run on them.
If your application needs to scale rapidly, some pods might remain in a state of waiting to be scheduled until more nodes deployed by the cluster autoscaler can accept the scheduled pods. For applications that have high burst demands, you can scale with virtual nodes and Azure Container Instances.
Scale in events
The cluster autoscaler also monitors the pod scheduling status for nodes that haven't recently received new scheduling requests. This scenario indicates the node pool has more compute resources than required, and the number of nodes can be decreased. By default, nodes that pass a threshold of no longer being needed for 10 minutes are scheduled for deletion. When this situation occurs, pods are scheduled to run on other nodes within the node pool, and the cluster autoscaler decreases the number of nodes.
Your applications might experience some disruption as pods are scheduled on different nodes when the cluster autoscaler decreases the number of nodes. To minimize disruption, avoid applications that use a single pod instance.
Kubernetes Event-driven Autoscaling (KEDA)
Kubernetes Event-driven Autoscaling (KEDA) is an open source component for event-driven autoscaling of workloads. It scales workloads dynamically based on the number of events received. KEDA extends Kubernetes with a custom resource definition (CRD), referred to as a ScaledObject, to describe how applications should be scaled in response to specific traffic.
KEDA scaling is useful in scenarios where workloads receive bursts of traffic or handle high volumes of data. KEDA differs from the Horizontal Pod Autoscaler as KEDA is event-driven and scales based on the number of events, while HPA is metrics-driven based on the resource utilization (for example, CPU and memory).
To get started with the KEDA add-on in AKS, see KEDA overview.
Node Autoprovisioning
Node autoprovisioning (preview) (NAP), uses the open source Karpenter project that automatically deploys, configures, and manages Karpenter on your AKS cluster. NAP dynamically provisions nodes based on pending pod resource requirements; it'll automatically select the optimal virtual machine (VM) SKU and quantity to meet real-time demand.
NAP takes a predefined list of VM SKUs as the starting point to decide which SKU is best suited for pending workloads. For more precise control, users can define the upper limits of resources used by a node pool and preferences of where workloads should be scheduled if there are multiple node pools.
Control Plane Scaling and Safeguards
Kubernetes has a multi-dimensional scale envelope with each resource type representing a dimension. Not all resources are alike. For example, watches are commonly set on secrets, which result in list calls to the kube-apiserver that add cost and a disproportionately higher load on the control plane compared to resources without watches.
The control plane manages all the resource scaling in the cluster, so the more you scale the cluster within a given dimension, the less you can scale within other dimensions. For example, running hundreds of thousands of pods in an AKS cluster impacts how much pod churn rate (pod mutations per second) the control plane can support. Refer to best practices.
AKS automatically scales control plane components based on key signals such as the total number of cores in the cluster and CPU or memory pressure on the control plane components.
To verify whether the control plane has scaled up, check the ConfigMap named 'large-cluster-control-plane-scaling-status'
kubectl describe configmap large-cluster-control-plane-scaling-status -n kube-system
Control Plane Safeguards
If scaling the API server automatically does not stabilize it under high load scenarios, AKS deploys a managed API server guard. This guard acts as a last-resort mechanism to protect the API server by throttling non-system client requests and preventing the control plane from becoming completely unresponsive. System-critical calls to API server from components such as kubelet will continue to function normally.
To verify whether the managed API server guard has been applied, check for the presence of "aks-managed-apiserver-guard" FlowSchema and PriorityLevelConfiguration.
kubectl get flowschemas
kubectl get prioritylevelconfigurations
Refer to API server and Etcd Troubleshooting guide if the "aks-managed-apiserver-guard" FlowSchema and PriorityLevelConfiguration have been applied on the cluster for quick mitigation.
Burst to Azure Container Instances (ACI)
To rapidly scale your AKS cluster, you can integrate with Azure Container Instances (ACI). Kubernetes has built-in components to scale the replica and node count. However, if your application needs to rapidly scale, the horizontal pod autoscaler might schedule more pods than what the existing compute resources in the node pool can support. If configured, this scenario would then trigger the cluster autoscaler to deploy more nodes in the node pool, but it might take a few minutes for those nodes to successfully provision and allow the Kubernetes scheduler to run pods on them.
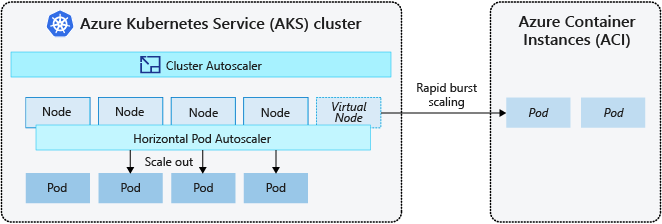
ACI lets you quickly deploy container instances without extra infrastructure overhead. When you connect with AKS, ACI becomes a secured, logical extension of your AKS cluster. The virtual nodes component, which is based on virtual Kubelet, is installed in your AKS cluster that presents ACI as a virtual Kubernetes node. Kubernetes can then schedule pods that run as ACI instances through virtual nodes, not as pods on VM nodes directly in your AKS cluster.
Your application requires no modifications to use virtual nodes. Your deployments can scale across AKS and ACI and with no delay as the cluster autoscaler deploys new nodes in your AKS cluster.
Virtual nodes are deployed to another subnet in the same virtual network as your AKS cluster. This virtual network configuration secures the traffic between ACI and AKS. Like an AKS cluster, an ACI instance is a secure, logical compute resource isolated from other users.
Next steps
To get started with scaling applications, see the following resources:
- Manually scale pods or nodes
- Use the horizontal pod autoscaler
- Use the cluster autoscaler
- Use the Kubernetes Event-driven Autoscaling (KEDA) add-on
For more information on core Kubernetes and AKS concepts, see the following articles: