Solution ideas
This article describes a solution idea. Your cloud architect can use this guidance to help visualize the major components for a typical implementation of this architecture. Use this article as a starting point to design a well-architected solution that aligns with your workload's specific requirements.
Implement a custom natural language processing (NLP) solution in Azure. Use Spark NLP for tasks like topic and sentiment detection and analysis.
Apache®, Apache Spark, and the flame logo are either registered trademarks or trademarks of the Apache Software Foundation in the United States and/or other countries. No endorsement by The Apache Software Foundation is implied by the use of these marks.
Architecture

Download a Visio file of this architecture.
Workflow
- Azure Event Hubs, Azure Data Factory, or both services receive documents or unstructured text data.
- Event Hubs and Data Factory store the data in file format in Azure Data Lake Storage. We recommend that you set up a directory structure that complies with business requirements.
- The Azure Computer Vision API uses its optical character recognition (OCR) capability to consume the data. The API then writes the data to the bronze layer. This consumption platform uses a lakehouse architecture.
- In the bronze layer, various Spark NLP features preprocess the text. Examples include splitting, correcting spelling, cleaning, and understanding grammar. We recommend running document classification at the bronze layer and then writing the results to the silver layer.
- In the silver layer, advanced Spark NLP features perform document analysis tasks like named entity recognition, summarization, and information retrieval. In some architectures, the outcome is written to the gold layer.
- In the gold layer, Spark NLP runs various linguistic visual analyses on the text data. These analyses provide insight into language dependencies and help with the visualization of NER labels.
- Users query the gold layer text data as a data frame and view the results in Power BI or web apps.
During the processing steps, Azure Databricks, Azure Synapse Analytics, and Azure HDInsight are used with Spark NLP to provide NLP functionality.
Components
- Data Lake Storage is a Hadoop-compatible file system that has an integrated hierarchical namespace and the massive scale and economy of Azure Blob Storage.
- Azure Synapse Analytics is an analytics service for data warehouses and big data systems.
- Azure Databricks is an analytics service for big data that's easy to use, facilitates collaboration, and is based on Apache Spark. Azure Databricks is designed for data science and data engineering.
- Event Hubs ingests data streams that client applications generate. Event Hubs stores the streaming data and preserves the sequence of received events. Consumers can connect to hub endpoints to retrieve messages for processing. Event Hubs integrates with Data Lake Storage, as this solution shows.
- Azure HDInsight is a managed, full-spectrum, open-source analytics service in the cloud for enterprises. You can use open-source frameworks with Azure HDInsight, such as Hadoop, Apache Spark, Apache Hive, LLAP, Apache Kafka, Apache Storm, and R.
- Data Factory automatically moves data between storage accounts of differing security levels to ensure separation of duties.
- Computer Vision uses text recognition APIs to recognize text in images and extract that information. The Read API uses the latest recognition models, and is optimized for large, text-heavy documents and noisy images. The OCR API isn't optimized for large documents but supports more languages than the Read API. This solution uses OCR to produce data in the hOCR format.
Scenario details
Natural language processing (NLP) has many uses: sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications like NLP. Azure Synapse Analytics, Azure HDInsight, and Azure Databricks offer access to Spark and take advantage of its processing power.
For customized NLP workloads, the open-source library Spark NLP serves as an efficient framework for processing a large amount of text. This article presents a solution for large-scale custom NLP in Azure. The solution uses Spark NLP features to process and analyze text. For more information about Spark NLP, see Spark NLP functionality and pipelines, later in this article.
Potential use cases
Document classification: Spark NLP offers several options for text classification:
- Text preprocessing in Spark NLP and machine learning algorithms that are based on Spark ML
- Text preprocessing and word embedding in Spark NLP and machine learning algorithms such as GloVe, BERT, and ELMo
- Text preprocessing and sentence embedding in Spark NLP and machine learning algorithms and models such as the Universal Sentence Encoder
- Text preprocessing and classification in Spark NLP that uses the ClassifierDL annotator and is based on TensorFlow
Name entity extraction (NER): In Spark NLP, with a few lines of code, you can train a NER model that uses BERT, and you can achieve state-of-the-art accuracy. NER is a subtask of information extraction. NER locates named entities in unstructured text and classifies them into predefined categories such as person names, organizations, locations, medical codes, time expressions, quantities, monetary values, and percentages. Spark NLP uses a state-of-the-art NER model with BERT. The model is inspired by a former NER model, bidirectional LSTM-CNN. That former model uses a novel neural network architecture that automatically detects word-level and character-level features. For this purpose, the model uses a hybrid bidirectional LSTM and CNN architecture, so it eliminates the need for most feature engineering.
Sentiment and emotion detection: Spark NLP can automatically detect positive, negative, and neutral aspects of language.
Part of speech (POS): This functionality assigns a grammatical label to each token in input text.
Sentence detection (SD): SD is based on a general-purpose neural network model for sentence boundary detection that identifies sentences within text. Many NLP tasks take a sentence as an input unit. Examples of these tasks include POS tagging, dependency parsing, named entity recognition, and machine translation.
Spark NLP functionality and pipelines
Spark NLP provides Python, Java, and Scala libraries that offer the full functionality of traditional NLP libraries such as spaCy, NLTK, Stanford CoreNLP, and Open NLP. Spark NLP also offers functionality such as spell checking, sentiment analysis, and document classification. Spark NLP improves on previous efforts by providing state-of-the-art accuracy, speed, and scalability.
Spark NLP is by far the fastest open-source NLP library. Recent public benchmarks show Spark NLP as 38 and 80 times faster than spaCy, with comparable accuracy for training custom models. Spark NLP is the only open-source library that can use a distributed Spark cluster. Spark NLP is a native extension of Spark ML that operates directly on data frames. As a result, speedups on a cluster result in another order of magnitude of performance gain. Because every Spark NLP pipeline is a Spark ML pipeline, Spark NLP is well-suited for building unified NLP and machine learning pipelines such as document classification, risk prediction, and recommender pipelines.
Besides excellent performance, Spark NLP also delivers state-of-the-art accuracy for a growing number of NLP tasks. The Spark NLP team regularly reads the latest relevant academic papers and produces the most accurate models.
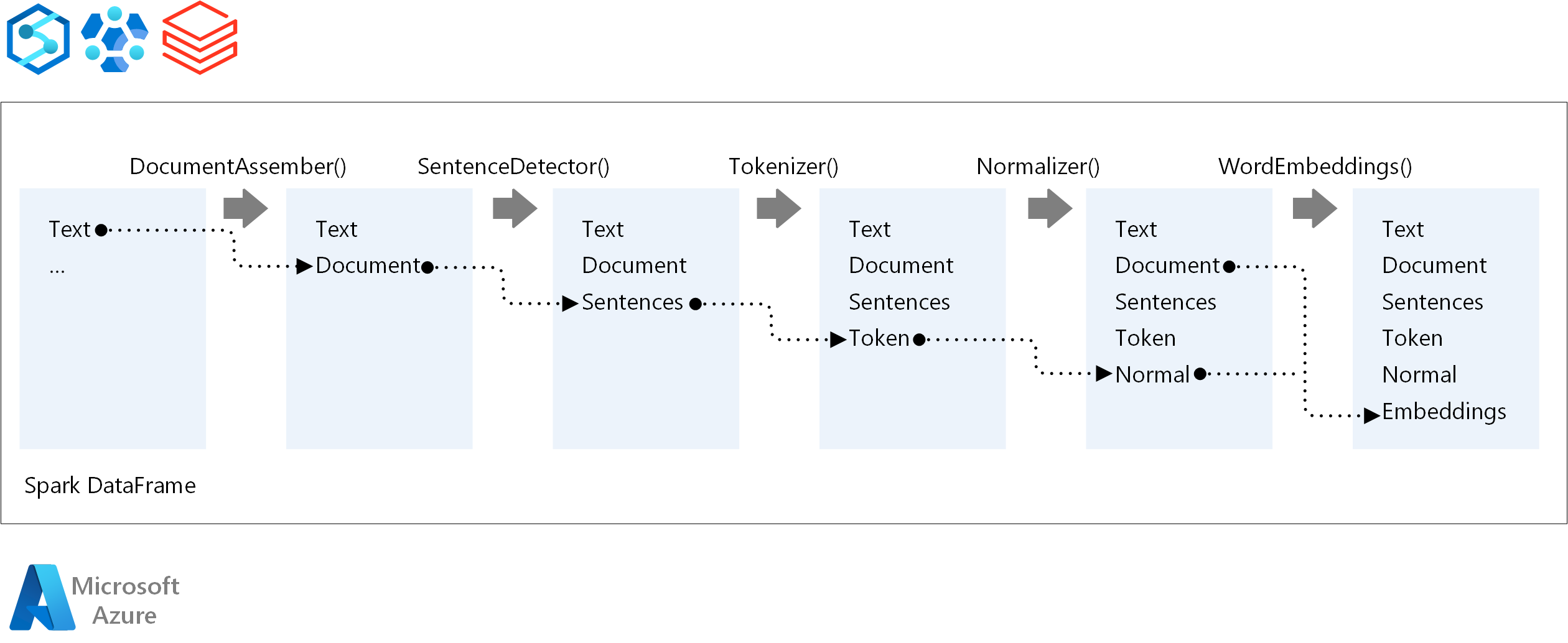
For the execution order of an NLP pipeline, Spark NLP follows the same development concept as traditional Spark machine learning models. But Spark NLP applies NLP techniques. The following diagram shows the core components of a Spark NLP pipeline.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Moritz Steller | Senior Cloud Solution Architect
Next steps
Spark NLP documentation:
Azure components: