Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The Choreography pattern decentralizes workflow logic and distributes responsibilities to other components within a system. Instead of depending on a central orchestrator, services decide when and how to process a business operation.
Context and problem
You typically divide a cloud-based application into several small services that work together to process an end-to-end business transaction. A single operation within a transaction can result in multiple point-to-point calls among all services. Ideally, those services are loosely coupled. It's challenging to design a distributed, efficient, and scalable workflow because it involves complex interservice communication.
A common pattern for communication is to use a centralized service or an orchestrator. Incoming requests flow through the orchestrator as it delegates operations to the respective services. Each service completes their responsibility and isn't aware of the overall workflow.

You typically implement the orchestrator pattern as custom software that has domain knowledge about the responsibilities of the services within the system. One benefit of this approach is that the orchestrator can consolidate the status of a transaction based on the results of individual operations that the downstream services conduct.
This approach also creates some obstacles. Adding or removing services might break existing logic because you need to rewire portions of the communication path. This dependency makes orchestrator implementation complex and hard to maintain. The orchestrator might negatively affect the workload's reliability. Under load, it can introduce performance bottlenecks and be the single point of failure (SPoF). It can also cause cascading failures in the downstream services.
Solution
Delegate the transaction-handling logic among the services. Let each service participate in the communication workflow for a business operation and decide when and how to process it.
The Choreography pattern minimizes the dependency on custom software that centralizes the communication workflow. The components implement common logic as they choreograph the workflow among themselves without directly communicating with each other.
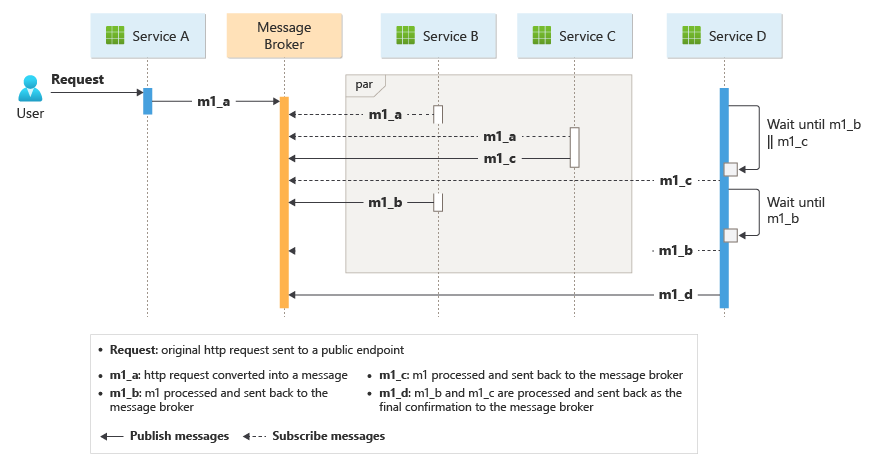
A common way to implement choreography is to use a message broker that buffers requests until downstream components claim and process them. The following image shows request handling through a publisher-subscriber model.

Client requests queue as messages in a message broker.
The services or the subscriber polls the broker to determine whether it can process that message based on its implemented business logic. The broker can also push messages to subscribers interested in that message.
Each subscribed service does its operation as the message indicates and responds to the broker with an operation success or failure message.
If the operation is successful, the service can push a message back to the same queue or a different message queue so that another service can continue the workflow if needed. If the operation fails, the message broker works with other services to compensate that operation or the entire transaction.
Problems and considerations
Consider the following points as you decide how to implement this pattern:
Handling failures can be challenging. Components in an application might manage atomic tasks and depend on other parts of the system. Failure in one component can affect other components, which might cause delays in completing the overall request.
To handle failures gracefully, you implement failure-handling logic, which introduces complexity. Failure-handling logic, such as compensating transactions, is also prone to failures.
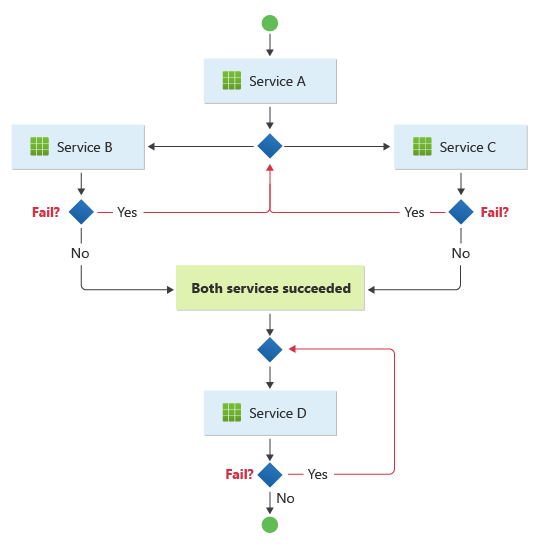
This pattern suits a workflow that processes independent business operations in parallel. The workflow can become complicated when choreography needs to occur in a sequence. For example, Service D can start its operation only after Service B and Service C complete their operations successfully.
This pattern presents challenges if the number of services grows rapidly. Many independent moving parts complicates the workflow between services. You must consistently use distributed tracing and correlation identifiers to maintain observability.
In an orchestrator‑led design, the central component can delegate resiliency responsibilities, such as retry handling for transient, nontransient, and timeout failures, to a dedicated resiliency handler.
When you remove the orchestrator in a choreography‑based design, downstream components don't assume resiliency responsibilities. They remain centralized in the resiliency handler. But downstream components must communicate with that handler directly, which increases point‑to‑point communication.
Event schema evolution can cause breaking changes in consumers over time. In this pattern, multiple independent services consume the same events. If a producer changes the data structure of an event, it can break downstream consumers that depend on the old schema. Use a schema registry to manage event contracts and use backward-compatible evolution as services evolve independently.
Event ordering isn't guaranteed under retries or scale-out. Design for idempotency and re-emit messages in sequence to handle duplicate or out-of-order events.
Decentralized event topologies can create emergent behavior at scale. When many services react to each other's events, the system can unintentionally produce feedback loops or event storms. A minor event might trigger a cascade of downstream reactions. To prevent circular event chains, use guardrails like event filtering, consumer concurrency limits, throttling, and explicit rules.


When to use this pattern
Use this pattern when:
The downstream components handle atomic operations independently. Think of this pattern as a fire and forget mechanism, in which a component does a task that doesn't need active management. When the task is complete, the component sends a notification to the other components.
You expect to frequently update and replace the components. This pattern lets you modify the application with less effort and minimal disruption to existing services.
You use serverless architectures for simple workflows. The components can be short-lived and event-driven. When an event occurs, the service creates components that do a task, and the service removes components after they complete that task.
Communication between bounded contexts requires loose coupling across domain boundaries. For communication inside a single bounded context, apply an orchestrator pattern instead.
The central orchestrator introduces a performance bottleneck.
This pattern might not be suitable when:
The application is complex and requires a central component to handle shared logic to keep the downstream components lightweight.
Point-to-point communication between the components is inevitable.
You need to use business logic to consolidate all operations that downstream components handle.
Workload design
Evaluate how to use the Choreography pattern in a workload's design to address the goals and principles covered in the Azure Well-Architected Framework pillars. The following table provides guidance about how this pattern supports the goals of each pillar.
| Pillar | How this pattern supports pillar goals |
|---|---|
| Operational Excellence helps deliver workload quality through standardized processes and team cohesion. | The distributed components in this pattern are autonomous and designed to be replaceable, so you can modify the workload with less overall change to the system. - OE:04 Tools and processes |
| Performance Efficiency helps your workload efficiently meet demands through optimizations in scaling, data, and code. | This pattern provides an alternative when performance bottlenecks occur in a centralized orchestration topology. - PE:02 Capacity planning - PE:05 Scaling and partitioning |
If this pattern introduces trade-offs within a pillar, consider them against the goals of the other pillars.
Example
This example shows the Choreography pattern by creating an event-driven, cloud-native workload that runs functions alongside microservices. When a client requests to ship a package, the workload assigns a drone. After the package is ready for pickup by the scheduled drone, the delivery process starts. While the package is in transit, the workload handles the delivery until it receives the shipped status.

The ingestion service receives client requests and converts them into messages that include the delivery details. Business transactions start after services consume those new messages.
A single client business transaction requires three distinct business operations:
Create or update a package.
Assign a drone to deliver the package.
Handle the delivery, including checking and sending a notification when the package ships.
Package, drone scheduler, and delivery microservices perform the business processing. The services use messaging instead of a central orchestrator to communicate with each other. Each service must implement a protocol in advance that coordinates the business workflow in a decentralized way.
Design
Services process business transactions in a sequence through multiple hops. Each hop shares a single message bus among all the business services.
When a client sends a delivery request through an HTTP endpoint, the ingestion service receives it, converts it into a message, and then publishes the message to the shared message bus. The subscribed business services consume new messages added to the bus. When a business service receives the message, it completes the operation successfully, or the request fails or times out. If the request succeeds, the service responds to the bus with the Ok status code, raises a new operation message, and sends it to the message bus. If the request fails or times out, the service reports failure by sending the reason code to the message bus and then adds the message to a dead-letter queue (DLQ). The service also moves messages that it can't receive or process within a specific amount of time to the DLQ.
This design uses multiple message buses to process the entire business transaction. Azure Service Bus and Azure Event Grid provide the messaging service platform for this design. The workload runs on Azure Container Apps, which hosts Azure Functions for ingestion. Container Apps handles event-driven processing that runs the business logic.
This design also ensures that the choreography occurs in a sequence. A single Service Bus namespace contains a topic that has two subscriptions and a session-aware queue. The ingestion service publishes messages to the topic. The package service and drone scheduler service subscribe to the topic and publish messages that notify the queue of successful requests. Include a common session identifier that associates a GUID with the delivery identifier so that services can handle unbounded sequences of related messages in order. The delivery service waits for two related messages for each transaction. The first message indicates that the package is ready to be shipped, and the second message signals that a drone is scheduled.
In this design, Service Bus handles high-value messages that must not be lost or duplicated during the entire delivery process. When the package ships, a change of state publishes to Event Grid. The event sender has no expectation about how the change of state is handled. Downstream organization services that this design doesn't include can listen for this event type and run specific business logic, such as sending an order-status email to the user.
If you deploy this pattern in another compute service, such as AKS, you can implement the Publisher-Subscriber pattern application boilerplate with two containers in the same pod. One container runs the ambassador that interacts with the message bus that you choose while the other container runs the business logic. This approach improves performance and scalability. The ambassador and the business service share the same network, which reduces latency and increases throughput.
To avoid cascading retry operations that might lead to multiple attempts, business services should immediately flag unacceptable messages. Enrich these messages by using common reason codes or a defined application code so that the services can move them to a DLQ. Consider implementing the Saga pattern to manage consistency problems from downstream services. For example, another service handles dead-letter messages for remediation purposes only by running a compensation, retry, or pivot transaction.
The business services are idempotent to ensure that retry operations don't create duplicate resources. For example, the package service uses upsert operations to add data to the data store.
Next steps
Centralize event schema management by using schema registry in Azure Event Hubs to maintain compatibility as your services evolve.
Review asynchronous messaging options in Azure to learn about the different infrastructure choices available for implementing a decentralized workflow.
Evaluate the technical capabilities of different platforms to choose the right Azure messaging service for your specific choreography requirements.
Related resources
Consider these patterns in your design for choreography:
Modularize the business service by using the Ambassador pattern.
Implement the Queue-Based Load Leveling pattern to handle spikes in the workload.
Use asynchronous distributed messaging through the Publisher-Subscriber pattern.
Use compensating transactions to undo a series of successful operations if one or more related operations fail.