Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
A key design area of any mission critical architecture is the application platform. Platform refers to the infrastructure components and Azure services that must be provisioned to support the application. Here are some overarching recommendations.
Design in layers. Choose the right set of services, their configuration, and the application-specific dependencies. This layered approach helps in creating logical and physical segmentation. It's useful in defining roles and functions, and assigning appropriate privileges, and deployment strategies. This approach ultimately increases the reliability of the system.
A mission-critical application must be highly reliable and resistant to datacenter and regional failures. Building zonal and regional redundancy in an active-active configuration is the main strategy. As you choose Azure services for your application's platform, consider their Availability Zones support and deployment and operational patterns to use multiple Azure regions.
Use a scale units-based architecture to handle increased load. Scale units allow you to logically group resources and a unit can be scaled independent of other units or services in the architecture. Use your capacity model and expected performance to define the boundaries of, number of, and the baseline scale of each unit.
In this architecture, the application platform consists of global, deployment stamp, and regional resources. The regional resources are provisioned as part of a deployment stamp. Each stamp equates to a scale unit and, in case it becomes unhealthy, can be entirely replaced.
The resources in each layer have distinct characteristics. For more information, see Architecture pattern of a typical mission-critical workload.
| Characteristics | Considerations |
|---|---|
| Lifetime | What is the expected lifetime of resource, relative to other resources in the solution? Should the resource outlive or share the lifetime with the entire system or region, or should it be temporary? |
| State | What impact will the persisted state at this layer have on reliability or manageability? |
| Reach | Is the resource required to be globally distributed? Can the resource communicate with other resources, globally or in regions? |
| Dependencies | What's the dependency on other resources, globally or in other regions? |
| Scale limits | What is the expected throughput for that resource at that layer? How much scale is provided by the resource to fit that demand? |
| Availability/disaster recovery | What's the impact on availability or disaster at this layer? Would it cause a systemic outage or only localized capacity or availability issue? |
Global resources
Certain resources in this architecture are shared by resources deployed in regions. In this architecture, they are used to distribute traffic across multiple regions, store permanent state for the whole application, and cache global static data.
| Characteristics | Layer Considerations |
|---|---|
| Lifetime | These resources are expected to be long living. Their lifetime spans the life of the system or longer. Often the resources are managed with in-place data and control plane updates, assuming they support zero-downtime update operations. |
| State | Because these resources exist for at least the lifetime of the system, this layer is often responsible for storing global, geo-replicated state. |
| Reach | The resources should be globally distributed. It’s recommended that these resources communicate with regional or other resources with low latency and the desired consistency. |
| Dependencies | The resources should avoid dependencies on regional resources because their unavailability can be a cause of global failure. For example, certificates or secrets kept in a single vault could have global impact if there's a regional failure where the vault is located. |
| Scale limits | Often these resources are singleton instances in the system, and as such they should be able to scale such that they can handle throughput of the system as a whole. |
| Availability/disaster recovery | Because regional and stamp resources can consume global resources or are fronted by them, it's critical that global resources are configured with high availability and disaster recovery for the health of the whole system. |
In this architecture, global layer resources are Azure Front Door, Azure Cosmos DB, Azure Container Registry, and Azure Log Analytics for storing logs and metrics from other global layer resources.
There are other foundational resources in this design, such as Microsoft Entra ID and Azure DNS. They have been omitted in this image for brevity.

Global load balancer
Azure Front Door is used as the only entry point for user traffic. Azure guarantees that Azure Front Door will deliver the requested content without error 99.99% of the time. For more details, see Front Door service limits. If Front Door becomes unavailable, the end user will see the system as being down.
The Front Door instance sends traffic to the configured backend services, such as the compute cluster that hosts the API and the frontend SPA. Backend misconfigurations in Front Door can lead to outages. To avoid outages due to misconfigurations, you should extensively test your Front Door settings.
Another common error can come from misconfigured or missing TLS certificates, which can prevent users from using the front end or Front Door communicating to the backend. Mitigation might require manual intervention. For example, you might choose to roll back to the previous configuration and re-issue the certificate, if possible. Regardless, expect unavailability while changes take effect. Using managed certificates offered by Front door is recommended to reduce the operational overhead, such as handling expiration.
Front Door offers many additional capabilities besides global traffic routing. An important capability is the Web Application Firewall (WAF), because Front Door is able to inspect traffic which is passing through. When configured in the Prevention mode, it will block suspicious traffic before even reaching any of the backends.
For information about Front Door capabilities, see Frequently asked questions for Azure Front Door.
For other considerations about global distribution of traffic, see Mission-critical guidance in Well-architected Framework: Global routing.
Container Registry
Azure Container Registry is used to store Open Container Initiative (OCI) artifacts, specifically helm charts and container images. It doesn't participate in the request flow and is only accessed periodically. Container registry is required to exist before stamp resources are deployed and shouldn't have dependency on regional layer resources.
Enable zone redundancy and geo-replication of registries so that runtime access to images is fast and resilient to failures. In case of unavailability, the instance can then fail over to replica regions and requests are automatically re-routed to another region. Expect transient errors in pulling images until failover is complete.
Failures can also occur if images are deleted inadvertently, new compute nodes won't be able to pull images, but existing nodes can still use cached images. The primary strategy for disaster recovery is redeployment. The artifacts in a container registry can be regenerated from pipelines. Container registry must be able to withstand many concurrent connections to support all of your deployments.
It’s recommended that you use the Premium SKU to enable geo replication. The zone redundancy feature ensures resiliency and high availability within a specific region. In case of a regional outage, replicas in other regions are still available for data plane operations. With this SKU you can restrict access to images through private endpoints.
For more details, see Best practices for Azure Container Registry.
Database
It's recommended that all state is stored globally in a database separated from regional stamps. Build redundancy by deploying the database across regions. For mission-critical workloads, synchronizing data across regions should be the primary concern. Also, in case of a failure, write requests to the database should still be functional.
Data replication in an active-active configuration is strongly recommended. The application should be able to instantly connect with another region. All instances should be able to handle read and write requests.
For more information, see Data platform for mission-critical workloads.
Global monitoring
Azure Log Analytics is used to store diagnostic logs from all global resources. It's recommended that you restrict daily quota on storage especially on environments that are used for load testing. Also, set retention policy. These restrictions will prevent any overspend that is incurred by storing data that isn't needed beyond a limit.
Considerations for foundational services
The system is likely to use other critical platform services that can cause the entire system to be at risk, such as Azure DNS and Microsoft Entra ID. Azure DNS guarantees 100% availability SLA for valid DNS requests. Microsoft Entra guarantees at least 99.99% uptime. Still, you should be aware of the impact in the event of a failure.
Taking hard dependency on foundational services is inevitable because many Azure services depend on them. Expect disruption in the system if they are unavailable. For instance:
- Azure Front Door uses Azure DNS to reach the backend and other global services.
- Azure Container Registry uses Azure DNS to fail over requests to another region.
In both cases, both Azure services will be impacted if Azure DNS is unavailable. Name resolution for user requests from Front Door will fail; Docker images won't be pulled from the registry. Using an external DNS service as backup won't mitigate the risk because many Azure services don't allow such configuration and rely on internal DNS. Expect full outage.
Similarly, Microsoft Entra ID is used for control plane operations such as creating new AKS nodes, pulling images from Container Registry, or accessing Key Vault on pod startup. If Microsoft Entra ID is unavailable, existing components shouldn't be affected, but overall performance may be degraded. New pods or AKS nodes won't be functional. So, in case scale out operations are required during this time, expect decreased user experience.
Regional deployment stamp resources
In this architecture, the deployment stamp deploys the workload and provisions resources that participate in completing business transactions. A stamp typically corresponds to a deployment to an Azure region. Although a region can have more than one stamp.
| Characteristics | Considerations |
|---|---|
| Lifetime | The resources are expected to have a short life span (ephemeral) with the intent that they can get added and removed dynamically while regional resources outside the stamp continue to persist. The ephemeral nature is needed to provide more resiliency, scale, and proximity to users. |
| State | Because stamps are ephemeral and can be destroyed at any time, a stamp should be stateless as much as possible. |
| Reach | Can communicate with regional and global resources. However, communication with other regions or other stamps should be avoided. In this architecture, there isn't a need for these resources to be globally distributed. |
| Dependencies | The stamp resources must be independent. That is, they shouldn't rely on other stamps or components in other regions. They are expected to have regional and global dependencies. The main shared component is the database layer and container registry. This component requires synchronization at runtime. |
| Scale limits | Throughput is established through testing. The throughput of the overall stamp is limited to the least performant resource. Stamp throughput needs to take into account the estimated high-level of demand and any failover as the result of another stamp in the region becoming unavailable. |
| Availability/disaster recovery | Because of the temporary nature of stamps, disaster recovery is done by redeploying the stamp. If resources are in an unhealthy state, the stamp, as a whole, can be destroyed and redeployed. |
In this architecture, stamp resources are Azure Kubernetes Service, Azure Event Hubs, Azure Key Vault, and Azure Blob Storage.
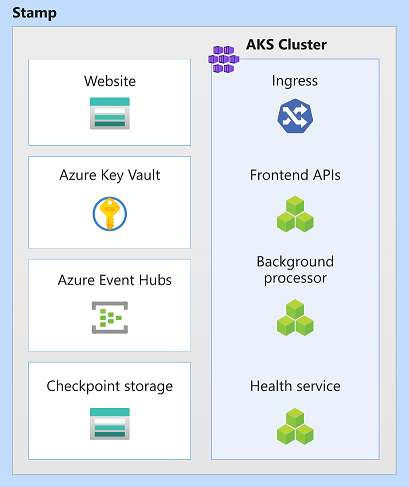
Scale unit
A stamp can also be considered as a scale unit (SU). All components and services within a given stamp are configured and tested to serve requests in a given range. Here's an example of a scale unit used in the implementation.
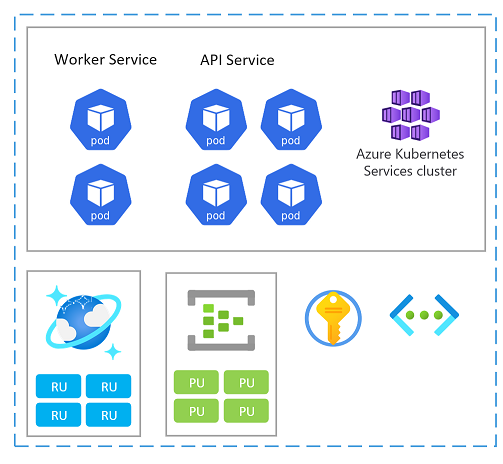
Each scale unit is deployed into an Azure region and is therefore primarily handling traffic from that given area (although it can take over traffic from other regions when needed). This geographic spread will likely result in load patterns and business hours that might vary from region to region and as such, every SU is designed to scale-in/-down when idle.
You can deploy a new stamp to scale. Inside a stamp, individual resources can also be units of scale.
Here are some scaling and availability considerations when choosing Azure services in a unit:
Evaluate capacity relations between all resources in a scale unit. For example, to handle 100 incoming requests, 5 ingress controller pods and 3 catalog service pods and 1000 RUs in Azure Cosmos DB would be needed. So, when autoscaling the ingress pods, expect scaling of the catalog service and Azure Cosmos DB RUs given those ranges.
Load test the services to determine a range within which requests will be served. Based on the results configure minimum and maximum instances and target metrics. When the target is reached, you can choose to automate scaling of the entire unit.
Review the Azure subscription scale limits and quotas to support the capacity and cost model set by the business requirements. Also check the limits of individual services in consideration. Because units are typically deployed together, factor in the subscription resource limits that are required for canary deployments. For more information, see Azure service limits.
Choose services that support availability zones to build redundancy. This might limit your technology choices. See Availability Zones for details.
For other considerations about the size of a unit, and combination of resources, see Mission-critical guidance in Well-architected Framework: Scale-unit architecture.
Compute cluster
To containerize the workload, each stamp needs to run a compute cluster. In this architecture, Azure Kubernetes Service (AKS) is chosen because Kubernetes is the most popular compute platform for modern, containerized applications.
The lifetime of the AKS cluster is bound to the ephemeral nature of the stamp. The cluster is stateless and doesn't have persistent volumes. It uses ephemeral OS disks instead of managed disks because they aren't expected to receive application or system-level maintenance.
To increase reliability, the cluster is configured to use all three availability zones in a given region. Additionally, to enable AKS Uptime SLA with guaranteed 99.95% SLA availability of the AKS control plane, the cluster should use either Standard, or Premium tier. See AKS pricing tiers to learn more.
Other factors such as scale limits, compute capacity, subscription quota can also impact reliability. If there isn't enough capacity or limits are reached, scale out and scale up operations will fail but existing compute is expected to function.
The cluster has autoscaling enabled to let node pools automatically scale out if needed, which improves reliability. When using multiple node pools, all node pools should be autoscaled.
At the pod level, the Horizontal Pod Autoscaler (HPA) scales pods based on configured CPU, memory, or custom metrics. Load test the components of the workload to establish a baseline for the autoscaler and HPA values.
The cluster is also configured for automatic node image upgrades and to scale appropriately during those upgrades. This scaling allows for zero downtime while upgrades are being performed. If the cluster in one stamp fails during an upgrade, other clusters in other stamps shouldn't be affected, but upgrades across stamps should occur at different times to maintain availability. Also, cluster upgrades are automatically rolled across the nodes so that they aren't unavailable at the same time.
Some components such as cert-manager and ingress-nginx require container images from external container registries. If those repositories or images are unavailable, new instances on new nodes (where the image isn't cached) might not be able to start. This risk could be mitigated by importing these images to the environment's Azure Container Registry.
Observability is critical in this architecture because stamps are ephemeral. Diagnostic settings are configured to store all log and metric data in a regional Log Analytics workspace. Also, AKS Container Insights is enabled through an in-cluster OMS Agent. This agent allows the cluster to send monitoring data to the Log Analytics workspace.
For other considerations about the compute cluster, see Mission-critical guidance in Well-architected Framework: Container Orchestration and Kubernetes.
Key Vault
Azure Key Vault is used to store global secrets such as connection strings to the database and stamp secrets such as the Event Hubs connection string.
This architecture uses a Secrets Store CSI driver in the compute cluster to get secrets from Key Vault. Secrets are needed when new pods are spawned. If Key Vault is unavailable, new pods might not get started. As a result, there might be disruption; scale out operations can be impacted, updates can fail, new deployments can't be executed.
Key Vault has a limit on the number of operations. Due to the automatic update of secrets, the limit can be reached if there are many pods. You can choose to decrease the frequency of updates to avoid this situation.
For other considerations on secret management, see Mission-critical guidance in Well-architected Framework: Data integrity protection.
Event Hubs
The only stateful service in the stamp is the message broker, Azure Event Hubs, which stores requests for a short period. The broker serves the need for buffering and reliable messaging. The processed requests are persisted in the global database.
In this architecture, Standard SKU is used and zone redundancy is enabled for high availability.
Event Hubs health is verified by the HealthService component running on the compute cluster. It performs periodic checks against various resources. This is useful in detecting unhealthy conditions. For example, if messages can't be sent to the event hub, the stamp would be unusable for any write operations. HealthService should automatically detect this condition and report unhealthy state to Front Door, which will take the stamp out of rotation.
For scalability, enabling auto-inflate is recommended.
For more information, see Messaging services for mission-critical workloads.
For other considerations about messaging, see Mission-critical guidance in Well-architected Framework: Asynchronous messaging.
Storage accounts
In this architecture two storage accounts are provisioned. Both accounts are deployed in zone-redundant mode (ZRS).
One account is used for Event Hubs checkpointing. If this account isn't responsive, the stamp won't be able to process messages from Event Hubs and might even impact other services in the stamp. This condition is periodically checked by the HealthService, which is one of the application components running in the compute cluster.
The other is used to host the UI single-page application. If serving of the static web site has any issues, Front Door will detect the issue and won't send traffic to this storage account. During this time, Front Door can use cached content.
For more information about recovery, see Disaster recovery and storage account failover.
Regional resources
A system can have resources that are deployed in region but outlive the stamp resources. In this architecture, observability data for stamp resources are stored in regional data stores.
| Characteristics | Consideration |
|---|---|
| Lifetime | The resources share the lifetime of the region and out live the stamp resources. |
| State | State stored in a region cannot live beyond the lifetime of the region. If state needs to be shared across regions, consider using a global data store. |
| Reach | The resources don't need to be globally distributed. Direct communication with other regions should be avoided at all cost. |
| Dependencies | The resources can have dependencies on global resources, but not on stamp resources because stamps are meant to be short lived. |
| Scale limits | Determine the scale limit of regional resources by combining all stamps within the region. |
Monitoring data for stamp resources
Deploying monitoring resources is a typical example for regional resources. In this architecture, each region has an individual Log Analytics workspace configured to store all log and metric data emitted from stamp resources. Because regional resources outlive stamp resources, data is available even when the stamp is deleted.
Azure Log Analytics and Azure Application Insights are used to store logs and metrics from the platform. It's recommended that you restrict daily quota on storage especially on environments that are used for load testing. Also, set retention policy to store all data. These restrictions will prevent any overspend that is incurred by storing data that isn't needed beyond a limit.
Similarly, Application Insights is also deployed as a regional resource to collect all application monitoring data.
For design recommendations about monitoring, see Mission-critical guidance in Well-architected Framework: Health modeling.
Next steps
Deploy the reference implementation to get a full understanding of the resources and their configuration used in this architecture.