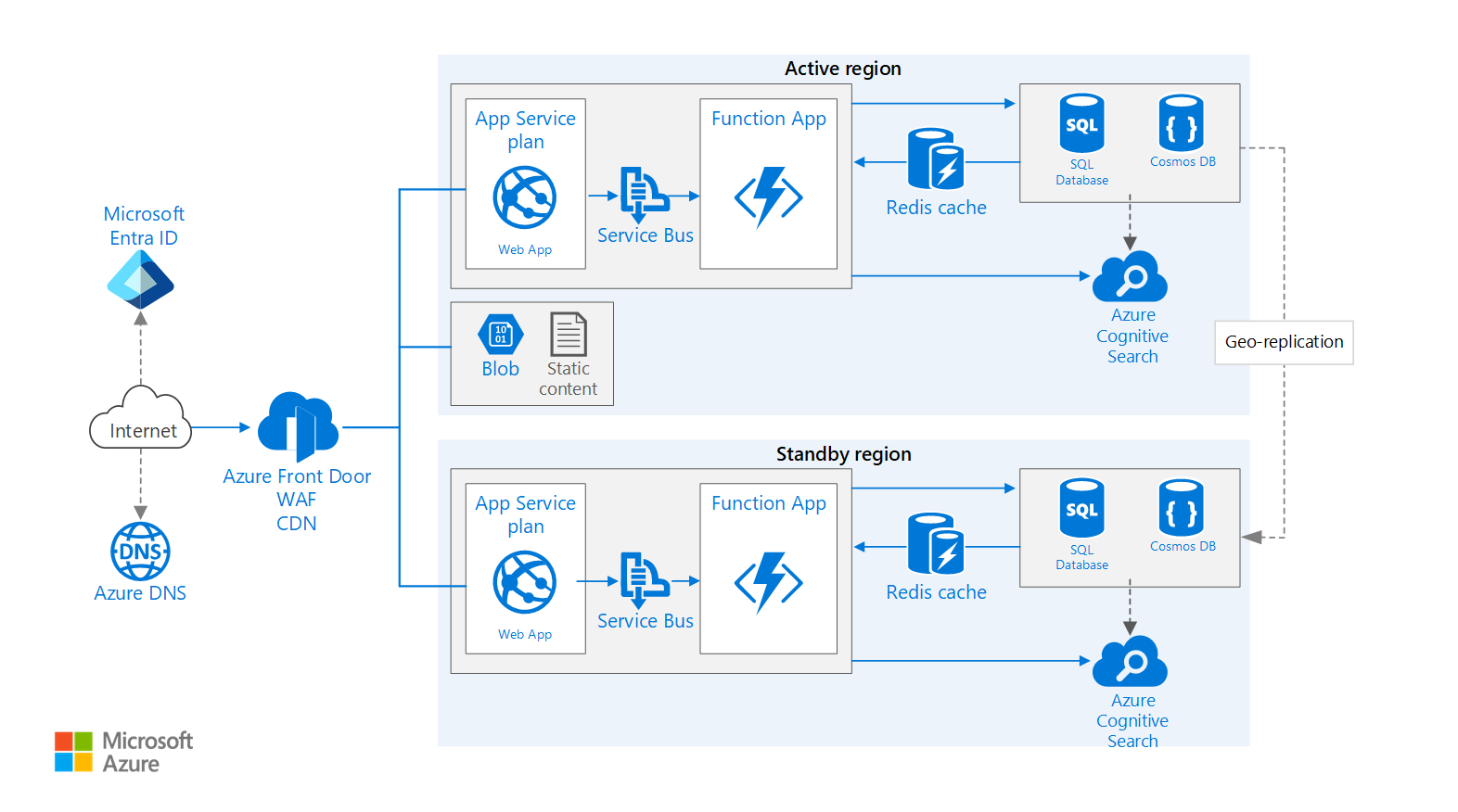
This example architecture is based on the Basic web application example architecture and extends it to show:
- Proven practices for improving scalability and performance in an Azure App Service web application
- How to run an Azure App Service application in multiple regions to achieve high availability
Architecture
Download a Visio file of this architecture.
Workflow
This workflow addresses the multi-region aspects of the architecture and builds upon the Basic web application.
- Primary and secondary regions. This architecture uses two regions to achieve higher availability. The application is deployed to each region. During normal operations, network traffic is routed to the primary region. If the primary region becomes unavailable, traffic is routed to the secondary region.
- Front Door. Azure Front Door is the recommended load balancer for multi-region implementations. It integrates with web application firewall (WAF) to protect against common exploits and uses Front Door's native content caching functionality. In this architecture, Front Door is configured for priority routing, which sends all traffic to the primary region unless it becomes unavailable. If the primary region becomes unavailable, Front Door routes all traffic to the secondary region.
- Geo-replication of Storage Accounts, SQL Database and/or Azure Cosmos DB.
Note
For a detailed overview of using Azure Front Door for multi-region architectures, including in a network-secured configuration, please see Network secure ingress implementation.
Components
Key technologies used to implement this architecture:
- Microsoft Entra ID is a cloud-based identity and access management service that lets employees access cloud apps developed for your organization.
- Azure DNS is a hosting service for DNS domains, providing name resolution using Microsoft Azure infrastructure. By hosting your domains in Azure, you can manage your DNS records using the same credentials, APIs, tools, and billing as your other Azure services. To use a custom domain name (such as
contoso.com), create DNS records that map the custom domain name to the IP address. For more information, see Configure a custom domain name in Azure App Service. - Azure Content Delivery Network is a global solution for delivering high-bandwidth content by caching it at strategically placed physical nodes across the world.
- Azure Front Door is a layer 7 load balancer. In this architecture, it routes HTTP requests to the web front end. Front Door also provides a web application firewall (WAF) that protects the application from common exploits and vulnerabilities. Front Door is also used for a Content Delivery Network (CDN) solution in this design.
- Azure AppService is a fully managed platform for creating and deploying cloud applications. It lets you define a set of compute resources for a web app to run, deploy web apps, and configure deployment slots.
- Azure Function Apps can be used to run background tasks. Functions are invoked by a trigger, such as a timer event or a message being placed on queue. For long-running stateful tasks, use Durable Functions.
- Azure Storage is a cloud storage solution for modern data storage scenarios, offering highly available, massively scalable, durable, and secure storage for a variety of data objects in the cloud.
- Azure Redis Cache is a high-performance caching service that provides an in-memory data store for faster retrieval of data, based on the open-source implementation Redis cache.
- Azure SQL Database is a relational database-as-a-service in the cloud. SQL Database shares its code base with the Microsoft SQL Server database engine.
- Azure Cosmos DB is a globally distributed, fully managed, low latency, multi-model, multi query-API database for managing data at large scale.
- Azure Cognitive Search can be used to add search functionality such as search suggestions, fuzzy search, and language-specific search. Azure Search is typically used in conjunction with another data store, especially if the primary data store requires strict consistency. In this approach, store authoritative data in the other data store and the search index in Azure Search. Azure Search can also be used to consolidate a single search index from multiple data stores.
Scenario details
There are several general approaches to achieve high availability across regions:
Active/Passive with hot standby: traffic goes to one region, while the other waits on hot standby. Hot standby means the App Service in the secondary region is allocated and is always running.
Active/Passive with cold standby: traffic goes to one region, while the other waits on cold standby. Cold standby means the App Service in the secondary region isn't allocated until needed for failover. This approach costs less to run, but will generally take longer to come online during a failure.
Active/Active: both regions are active, and requests are load balanced between them. If one region becomes unavailable, it's taken out of rotation.
This reference focuses on active/passive with hot standby.
Potential use cases
These use cases can benefit from a multi-region deployment:
Design a business continuity and disaster recovery plan for LoB applications.
Deploy mission-critical applications that run on Windows or Linux.
Improve the user experience by keeping applications available.
Recommendations
Your requirements might differ from the architecture described here. Use the recommendations in this section as a starting point.
Regional pairing
Each Azure region is paired with another region within the same geography. In general, choose regions from the same regional pair (for example, East US 2 and Central US). Benefits of doing so include:
- If there's a broad outage, recovery of at least one region out of every pair is prioritized.
- Planned Azure system updates are rolled out to paired regions sequentially to minimize possible downtime.
- In most cases, regional pairs reside within the same geography to meet data residency requirements.
However, make sure that both regions support all of the Azure services needed for your application. See Services by region. For more information about regional pairs, see Business continuity and disaster recovery (BCDR): Azure Paired Regions.
Resource groups
Consider placing the primary region, secondary region, and Front Door into separate resource groups. This allocation lets you manage the resources deployed to each region as a single collection.
App Service apps
We recommend creating the web application and the web API as separate App Service apps. This design lets you run them in separate App Service plans so they can be scaled independently. If you don't need that level of scalability initially, you can deploy the apps into the same plan and move them into separate plans later if necessary.
Note
For the Basic, Standard, Premium, and Isolated plans, you are billed for the VM instances in the plan, not per app. See App Service Pricing
Front Door configuration
Routing. Front Door supports several routing mechanisms. For the scenario described in this article, use priority routing. With this setting, Front Door sends all requests to the primary region unless the endpoint for that region becomes unreachable. At that point, it automatically fails over to the secondary region. Set the origin pool with different priority values, 1 for the active region and 2 or higher for the standby or passive region.
Health probe. Front Door uses an HTTPS probe to monitor the availability of each back end. The probe gives Front Door a pass/fail test for failing over to the secondary region. It works by sending a request to a specified URL path. If it gets a non-200 response within a timeout period, the probe fails. You can configure the health probe frequency, number of samples required for evaluation, and the number of successful samples required for the origin to be marked as healthy. If Front Door marks the origin as degraded, it fails over to the other origin. For details, see Health Probes.
As a best practice, create a health probe path in your application origin that reports the overall health of the application. This health probe should check critical dependencies such as the App Service apps, storage queue, and SQL Database. Otherwise, the probe might report a healthy origin when critical parts of the application are actually failing. On the other hand, don't use the health probe to check lower priority services. For example, if an email service goes down the application can switch to a second provider or just send emails later. For further discussion of this design pattern, see Health Endpoint Monitoring Pattern.
Securing origins from the internet is a critical part of implementing a publicly accessible app. Refer to the Network secure ingress implementation to learn about Microsoft's recommended design and implementation patterns for securing your app's ingress communications with Front Door.
CDN. Use Front Door's native CDN functionality to cache static content. The main benefit of a CDN is to reduce latency for users, because content is cached at an edge server that is geographically close to the user. CDN can also reduce load on the application, because that traffic is not being handled by the application. Front Door additionally offers dynamic site acceleration allowing you to deliver a better overall user experience for your web app than would be available with only static content caching.
Note
Front Door CDN is not designed to serve content that requires authentication.
SQL Database
Use Active geo-replication and auto-failover groups to make your databases resilient. Active geo-replication allows you to replicate your databases from the primary region into one or more (up to four) other regions. Auto-failover groups build on top of active geo-replication by allowing you to fail over to a secondary database without any code changes to your apps. Failovers can be performed manually or automatically, according to policy definitions that you create. In order to use auto-failover groups, you'll need to configure your connections strings with the failover connection string automatically created for the failover group, rather than the connection strings of the individual databases.
Azure Cosmos DB
Azure Cosmos DB supports geo-replication across regions in active-active pattern with multiple write regions. Alternatively, you can designate one region as the writable region and the others as read-only replicas. If there's a regional outage, you can fail over by selecting another region to be the write region. The client SDK automatically sends write requests to the current write region, so you don't need to update the client configuration after a failover. For more information, see Global data distribution with Azure Cosmos DB.
Storage
For Azure Storage, use read-access geo-redundant storage (RA-GRS). With RA-GRS storage, the data is replicated to a secondary region. You have read-only access to the data in the secondary region through a separate endpoint. User-initiated failover to the secondary region is supported for geo-replicated storage accounts. Initiating a storage account failover automatically updates DNS records to make the secondary storage account the new primary storage account. Failovers should only be undertaken when you deem it's necessary. This requirement is defined by your organization's disaster recovery plan, and you should consider the implications as described in the Considerations section below.
If there's a regional outage or disaster, the Azure Storage team might decide to perform a geo-failover to the secondary region. For these types of failovers, there's no customer action required. Fail back to the primary region is also managed by the Azure storage team in these cases.
In some cases object replication for block blobs will be a sufficient replication solution for your workload. This replication feature allows you to copy individual block blobs from the primary storage account into a storage account in your secondary region. Benefits of this approach are a granular control over what data is being replicated. You can define a replication policy for more granular control of the types of block blobs that are replicated. Examples of policy definitions include, but aren't limited to:
- Only block blobs added subsequent to creating the policy are replicated
- Only block blobs added after a given date and time are replicated
- Only block blobs matching a given prefix are replicated.
Queue storage is referenced as an alternative messaging option to Azure Service Bus for this scenario. However, if you use queue storage for your messaging solution, the guidance provided above relative to geo-replication applies here, as queue storage resides on storage accounts. It's important to understand, however, that messages aren't replicated to the secondary region and their state is inextricable from the region.
Azure Service Bus
In order to benefit from the highest resilience offered for Azure Service Bus, use the premium tier for your namespaces. The premium tier makes use of availability zones, which makes your namespaces resilient to data center outages. If there's a widespread disaster affecting multiple data centers, the Geo-disaster recovery feature included with the premium tier can help you recover. The Geo-Disaster recovery feature ensures that the entire configuration of a namespace (queues, topics, subscriptions, and filters) is continuously replicated from a primary namespace to a secondary namespace when paired. It allows you to initiate a once-only failover move from the primary to the secondary at any time. The failover move will repoint the chosen alias name for the namespace to the secondary namespace and then break the pairing. The failover is nearly instantaneous once initiated.
Azure Cognitive Search
In Cognitive Search, availability is achieved through multiple replicas, whereas business continuity and disaster recovery (BCDR) is achieved through multiple search services.
In Cognitive Search, replicas are copies of your index. Having multiple replicas allows Azure Cognitive Search to do machine reboots and maintenance against one replica, while query execution continues on other replicas. For more information about adding replicas, see Add or reduce replicas and partitions.
You can utilize Availability Zones with Azure Cognitive Search by adding two or more replicas to your search service. Each replica will be placed in a different Availability Zone within the region.
For BCDR considerations, refer to the Multiple services in separate geographic regions documentation.
Azure Cache for Redis
While all tiers of Azure Cache for Redis offer Standard replication for high availability, the Premium or Enterprise tier are recommended to provide a higher level of resilience and recoverability. Review the High availability and disaster recovery for a complete list of resiliency and recoverability features and options for these tiers. Your business requirements will determine which tier is the best fit for your infrastructure.
Considerations
These considerations implement the pillars of the Azure Well-Architected Framework, which is a set of guiding tenets that can be used to improve the quality of a workload. For more information, see Microsoft Azure Well-Architected Framework.
Reliability
Reliability ensures your application can meet the commitments you make to your customers. For more information, see Overview of the reliability pillar. Consider these points when designing for high availability across regions.
Azure Front Door
Azure Front Door automatically fails over if the primary region becomes unavailable. When Front Door fails over, there's a period of time (usually about 20-60 seconds) when clients can't reach the application. The duration is affected by the following factors:
- Frequency of health probes. The more frequent the health probes are sent, the faster Front Door can detect downtime or the origin coming back healthy.
- Sample size configuration. This configuration controls how many samples are required for the health probe to detect that the primary origin has become unreachable. If this value is too low, you could get false positives from intermittent issues.
Front Door is a possible failure point in the system. If the service fails, clients can't access your application during the downtime. Review the Front Door service level agreement (SLA) and determine whether using Front Door alone meets your business requirements for high availability. If not, consider adding another traffic management solution as a fallback. If the Front Door service fails, change your canonical name (CNAME) records in DNS to point to the other traffic management service. This step must be performed manually, and your application will be unavailable until the DNS changes are propagated.
Azure Front Door Standard and Premium tier combine the capabilities of Azure Front Door (classic), Azure CDN Standard from Microsoft (classic), and Azure WAF into a single platform. Using the Azure Front Door Standard or Premium reduces the points of failure and enables enhanced control, monitoring, and security. For more information, see Overview of Azure Front Door tier.
SQL Database
The recovery point objective (RPO) and estimated recovery time objective (RTO) for SQL Database are documented in Overview of business continuity with Azure SQL Database.
Be mindful that active geo-replication effectively doubles the cost of each replicated database. Sandbox, test, and development databases are typically not recommended for replication.
Azure Cosmos DB
RPO and recovery time objective (RTO) for Azure Cosmos DB are configurable via the consistency levels used, which provide trade-offs between availability, data durability, and throughput. Azure Cosmos DB provides a minimum RTO of 0 for a relaxed consistency level with multi-master or an RPO of 0 for strong consistency with single-master. To learn more about Azure Cosmos DB consistency levels, see Consistency levels and data durability in Azure Cosmos DB.
Storage
RA-GRS storage provides durable storage, but it's important to consider the following factors when contemplating performing a failover:
Anticipate data loss: Data replication to the secondary region is performed asynchronously. Therefore, if a geo-failover is performed, some data loss should be anticipated if changes to the primary account haven't fully synchronized to the secondary account. You can check the Last Sync Time property of the secondary storage account to see the last time that data from the primary region was written successfully to the secondary region.
Plan your recovery time objective (RTO) accordingly: Failover to the secondary region typically takes about one hour, so your DR plan should take this information into account when calculating your RTO parameters.
Plan your fail back carefully: It's important to understand that when a storage account fails over, the data in the original primary account is lost. Attempting a fail back to the primary region without careful planning is risky. After failover completes, the new primary - in the failover region - will be configured for locally redundant storage (LRS). You must manually reconfigure it as geo-replicated storage to initiate replication to the primary region and then give sufficient time to let the accounts sync.
Transient failures, such as a network outage, won't trigger a storage failover. Design your application to be resilient to transient failures. Mitigation options include:
- Read from the secondary region.
- Temporarily switch to another storage account for new write operations (for example, to queue messages).
- Copy data from the secondary region to another storage account.
- Provide reduced functionality until the system fails back.
For more information, see What to do if an Azure Storage outage occurs.
Refer to the prerequisites and caveats for object replication documentation for considerations when using object replication for block blobs.
Azure Service Bus
It's important to understand that the Geo-disaster recovery feature included in the premium Azure Service Bus tier enables instant continuity of operations with the same configuration. However, it doesn't replicate the messages held in queues or topic subscriptions or dead-letter queues. As such, a mitigation strategy is required to ensure a smooth failover to the secondary region. For a detailed description of other considerations and mitigation strategies, refer to the important points to consider and disaster recovery considerations documentation.
Security
Security provides assurances against deliberate attacks and the abuse of your valuable data and systems. For more information, see Overview of the security pillar.
Restrict incoming traffic Configure the application to accept traffic only from Front Door. This ensures that all traffic goes through the WAF before reaching the app. For more information, see How do I lock down the access to my backend to only Azure Front Door?
Cross-Origin Resource Sharing (CORS) If you create a website and web API as separate apps, the website cannot make client-side AJAX calls to the API unless you enable CORS.
Note
Browser security prevents a web page from making AJAX requests to another domain. This restriction is called the same-origin policy, and prevents a malicious site from reading sensitive data from another site. CORS is a W3C standard that allows a server to relax the same-origin policy and allow some cross-origin requests while rejecting others.
App Services has built-in support for CORS, without needing to write any application code. See Consume an API app from JavaScript using CORS. Add the website to the list of allowed origins for the API.
SQL Database encryption Use Transparent Data Encryption if you need to encrypt data at rest in the database. This feature performs real-time encryption and decryption of an entire database (including backups and transaction log files) and requires no changes to the application. Encryption does add some latency, so it's a good practice to separate the data that must be secure into its own database and enable encryption only for that database.
Identity When you define identities for the components in this architecture, use system managed identities where possible to reduce your need to manage credentials and the risks inherent to managing credentials. Where it's not possible to use system managed identities, ensure that every user managed identity exists in only one region and is never shared across region boundaries.
Service firewalls When configuring the service firewalls for the components, ensure both that only the region-local services have access to the services and that the services only allow outbound connections, which is explicitly required for replication and application functionality. Consider using Azure Private Link for further enhanced control and segmentation. For more information on securing web applications, see Baseline highly available zone-redundant web application.
Cost optimization
Cost optimization is about looking at ways to reduce unnecessary expenses and improve operational efficiencies. For more information, see Overview of the cost optimization pillar.
Caching Use caching to reduce the load on servers that serve content that doesn't change frequently. Every render cycle of a page can impact cost because it consumes compute, memory, and bandwidth. Those costs can be reduced significantly by using caching, especially for static content services, such as JavaScript single-page apps and media streaming content.
If your app has static content, use CDN to decrease the load on the front end servers. For data that doesn't change frequently, use Azure Cache for Redis.
State Stateless apps that are configured for autoscaling are more cost effective than stateful apps. For an ASP.NET application that uses session state, store it in-memory with Azure Cache for Redis. For more information, see ASP.NET Session State Provider for Azure Cache for Redis. Another option is to use Azure Cosmos DB as a backend state store through a session state provider. See Use Azure Cosmos DB as an ASP.NET session state and caching provider.
Functions Consider placing a function app into a dedicated App Service plan so that background tasks don't run on the same instances that handle HTTP requests. If background tasks run intermittently, consider using a consumption plan, which is billed based on the number of executions and resources used, rather than hourly.
For more information, see the cost section in the Microsoft Azure Well-Architected Framework.
Use the pricing calculator to estimate costs. These recommendations in this section may help you to reduce cost.
Azure Front Door
Azure Front Door billing has three pricing tiers: outbound data transfers, inbound data transfers, and routing rules. For more info See Azure Front Door Pricing. The pricing chart doesn't include the cost of accessing data from the origin services and transferring to Front Door. Those costs are billed based on data transfer charges, described in Bandwidth Pricing Details.
Azure Cosmos DB
There are two factors that determine Azure Cosmos DB pricing:
The provisioned throughput or Request Units per second (RU/s).
There are two types of throughput that can be provisioned in Azure Cosmos DB, standard and autoscale. Standard throughput allocates the resources required to guarantee the RU/s that you specify. For autoscale, you provision the maximum throughput, and Azure Cosmos DB instantly scales up or down depending on the load, with a minimum of 10% of the maximum autoscale throughput. Standard throughput is billed for the throughput provisioned hourly. Autoscale throughput is billed for the maximum throughput consumed hourly.
Consumed storage. You're billed a flat rate for the total amount of storage (GBs) consumed for data and the indexes for a given hour.
For more information, see the cost section in Microsoft Azure Well-Architected Framework.
Performance efficiency
A major benefit of Azure App Service is the ability to scale your application based on load. Here are some considerations to keep in mind when planning to scale your application.
App Service app
If your solution includes several App Service apps, consider deploying them to separate App Service plans. This approach enables you to scale them independently because they run on separate instances.
SQL Database
Increase scalability of a SQL database by sharding the database. Sharding refers to partitioning the database horizontally. Sharding allows you to scale out the database horizontally using Elastic Database tools. Potential benefits of sharding include:
- Better transaction throughput.
- Queries can run faster over a subset of the data.
Azure Front Door
Front Door can perform SSL offload and also reduces the total number of TCP connections with the backend web app. This improves scalability because the web app manages a smaller volume of SSL handshakes and TCP connections. These performance gains apply even if you forward the requests to the web app as HTTPS, due to the high level of connection reuse.
Azure Search
Azure Search removes the overhead of performing complex data searches from the primary data store, and it can scale to handle load. See Scale resource levels for query and indexing workloads in Azure Search.
Operational excellence
Operational excellence refers to the operations processes that deploy an application and keep it running in production and is an extension of the Well-Architected Framework Reliability guidance. This guidance provides a detailed overview of architecting resiliency into your application framework to ensure your workloads are available and can recover from failures at any scale. A core tenet of this approach is to design your application infrastructure to be highly available, optimally across multiple geographic regions as this design illustrates.
Contributors
This article is maintained by Microsoft. It was originally written by the following contributors.
Principal author:
- Arvind Boggaram Pandurangaiah Setty | Senior Consultant
To see non-public LinkedIn profiles, sign in to LinkedIn.
Next steps
Deep dive on Azure Front Door - traffic routing methods
Create health probes that report the overall health of the application based on endpoint monitoring patterns
Ensure business continuity and disaster recovery using Azure Paired Regions
Related resources
Multi-region N-tier application is a similar scenario. It shows an N-tier application running in multiple Azure regions