Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
Azure Cache for Redis announced its retirement timeline for all SKUs. We recommend moving your existing Azure Cache for Redis instances to Azure Managed Redis as soon as you can.
For more details about the retirement:
In this article, you learn how to configure passive geo-replication on a pair of Azure Cache for Redis instances using the Azure portal.
Passive geo-replication links together two Premium tier Azure Cache for Redis instances and creates an active-passive data replication relationship. Active-passive means that there's a pair of caches, primary and secondary, that have their data synchronized. But you can only write to one side of the pair, the primary. The other side of the pair, the secondary cache, is read-only.
Compare active-passive to active-active, where you can write to either side of the pair, and it synchronizes with the other side.
With passive geo-replication, the cache instances are typically located in different Azure regions, though that isn't required. One instance acts as the primary, and the other as the secondary. The primary handles read and write requests, and the primary propagates changes to the secondary.
Failover isn't automatic. For more information on how to use failover, see Initiate a failover from geo-primary to geo-secondary.
Note
Passive geo-replication is designed as a disaster-recovery solution.
Scope of availability
| Tier | Basic, Standard | Premium | Enterprise, Enterprise Flash |
|---|---|---|---|
| Available | No | Yes | Yes |
Passive geo-replication is only available in the Premium tier of Azure Cache for Redis. The Enterprise and Enterprise Flash tiers also offer geo-replication, but those tiers use a more advanced version called active geo-replication.
Geo-replication prerequisites
To configure geo-replication between two caches, the following prerequisites must be met:
- Both caches are Premium tier caches.
- Both caches should have only one replica per primary per shard.
- Both caches are in the same Azure subscription.
- The secondary linked cache is either the same cache size or a larger cache size than the primary linked cache. To use geo-failover, both caches must be the same size.
- Both caches are created and in a running state.
- Both caches are running the same version of Redis server.
Note
Data transfer between Azure regions is charged at standard bandwidth rates.
Some features aren't supported with geo-replication:
- Persistence isn't supported with geo-replication.
- Caches with more than one replica can't be geo-replicated.
- Clustering is supported if both caches have clustering enabled and have the same number of shards.
- Caches in the same Virtual Network (VNet) are supported.
- Caches in different VNets are supported with caveats. See Can I use geo-replication with my caches in a VNet? for more information.
After geo-replication is configured, the following restrictions apply to your linked cache pair:
The secondary linked cache is read-only. You can read from it, but you can't write any data to it. If you choose to read from the Geo-Secondary instance when a full data sync is happening between the Geo-Primary and the Geo-Secondary, the Geo-Secondary instance throws errors on any Redis operation against it until the full data sync is complete. The errors state that a full data sync is in progress. Also, the errors are thrown when either Geo-Primary or Geo-Secondary is updated and on some reboot scenarios. Applications reading from Geo-Secondary should be built to fall back to the Geo-Primary whenever the Geo-Secondary is throwing such errors.
Any data that was in the secondary linked cache before the link was added is removed. If the geo-replication is later removed however, the replicated data remains in the secondary linked cache.
You can't scale either cache while the caches are linked.
You can't change the number of shards if the cache has clustering enabled.
You can't enable persistence on either cache.
You can Export from either cache.
You can't Import into the secondary linked cache.
You can't delete either linked cache, or the resource group that contains them, until you unlink the caches. For more information, see Why did the operation fail when I tried to delete my linked cache?
If the caches are in different regions, network egress costs apply to the data moved across regions. For more information, see How much does it cost to replicate my data across Azure regions?
Failover isn't automatic. You must start the failover from the primary to the secondary linked cache. For more information on how to use failover, see Initiate a failover from geo-primary to geo-secondary.
Private links can't be added to caches that are already geo-replicated. To add a private link to a geo-replicated cache: 1. Unlink the geo-replication. 2. Add a Private Link. 3. Last, relink the geo-replication.
Add a geo-replication link
To link two caches together for geo-replication, first select Geo-replication from the Resource menu of the cache that you intend to be the primary linked cache. Next, select Add cache replication link from the working pane.
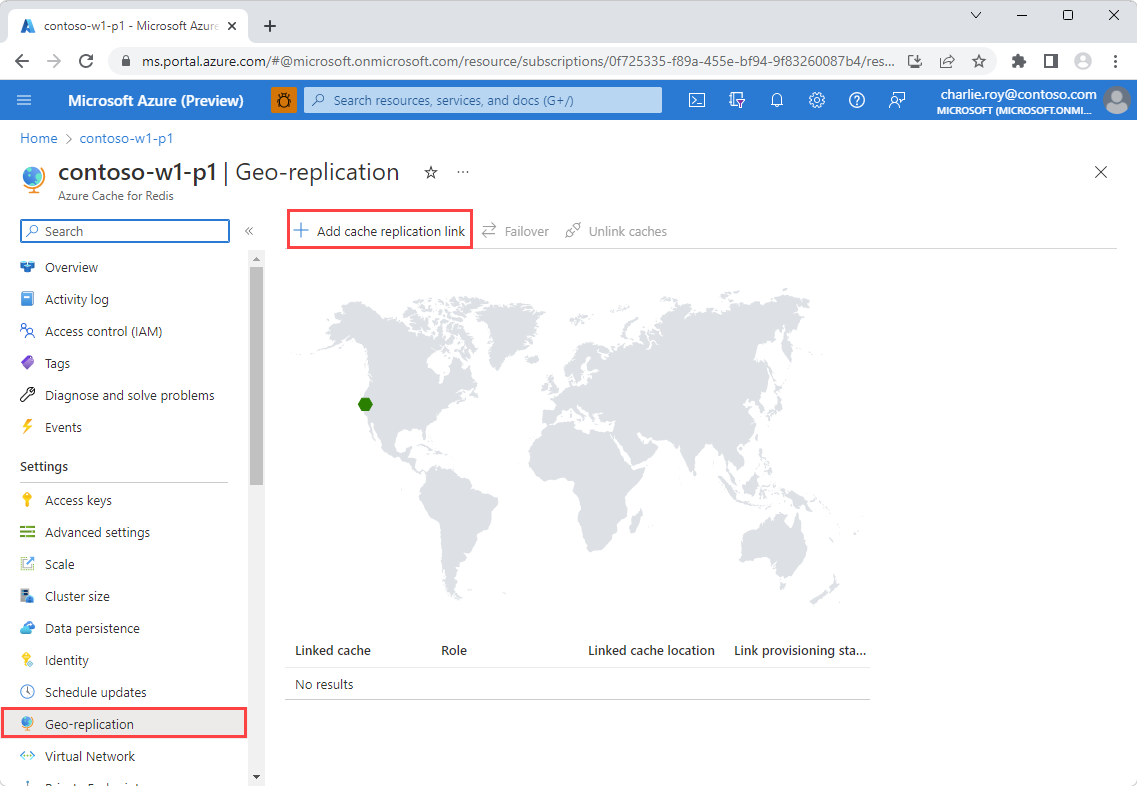
Select the name of your intended secondary cache from the Compatible caches list. If your secondary cache isn't displayed in the list, verify that the Geo-replication prerequisites for the secondary cache are met. To filter the caches by region, select the region in the map to display only those caches in the Compatible caches list.

You can also start the linking process or view details about the secondary cache by using the context menu.
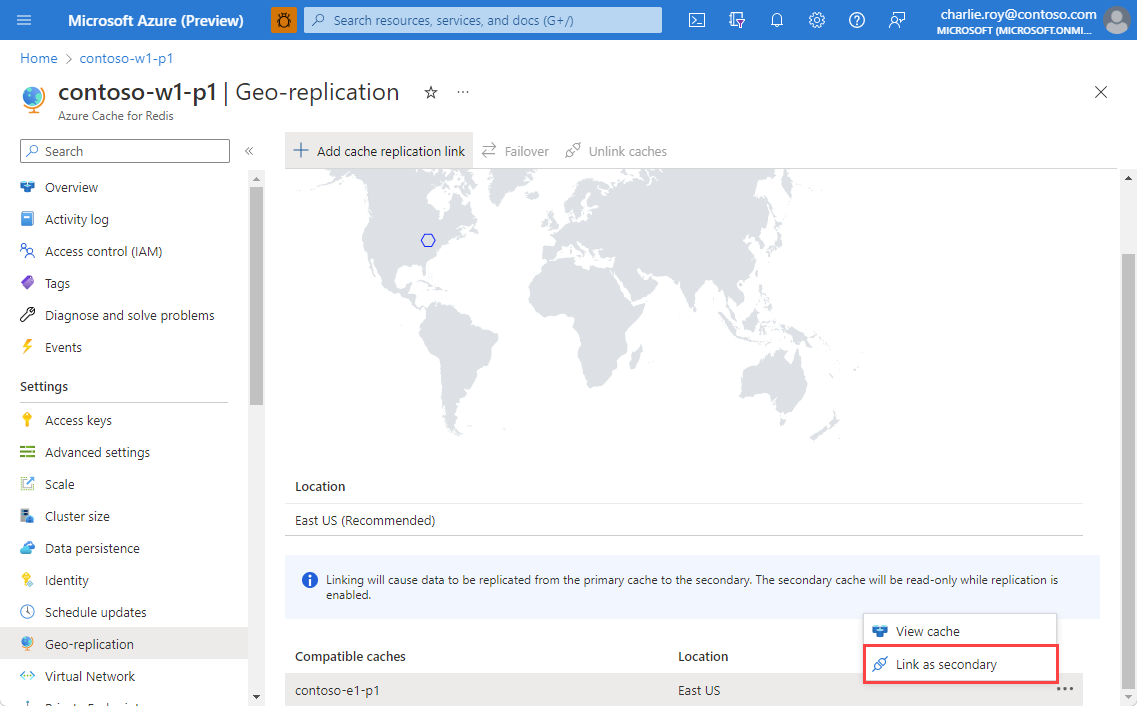
Select Link to link the two caches together and begin the replication process.
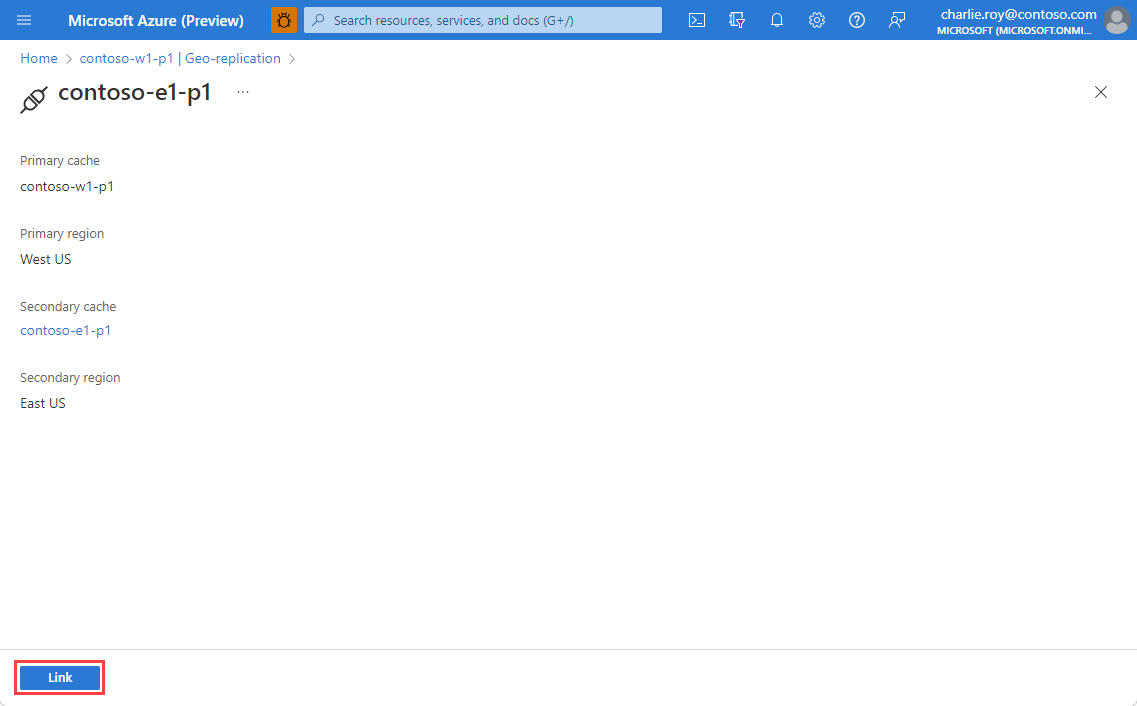
You can view the progress of the replication process using Geo-replication in the Resource menu.
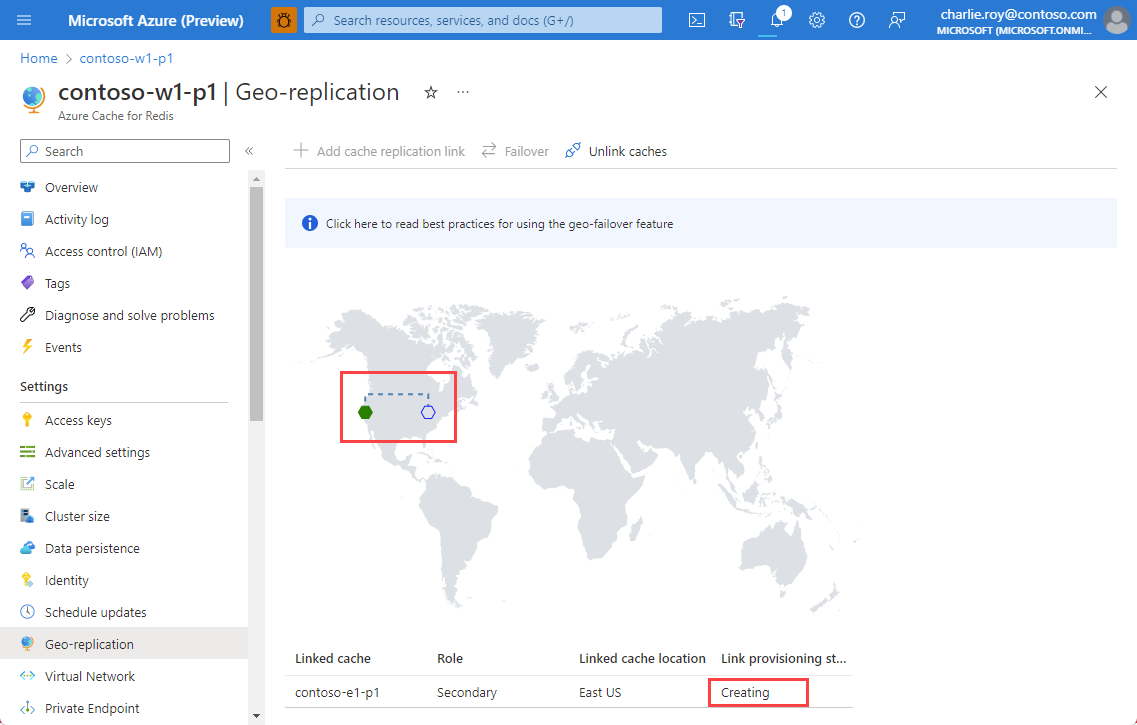
You can also view the linking status using Overview from the Resource menu for both the primary and secondary caches.
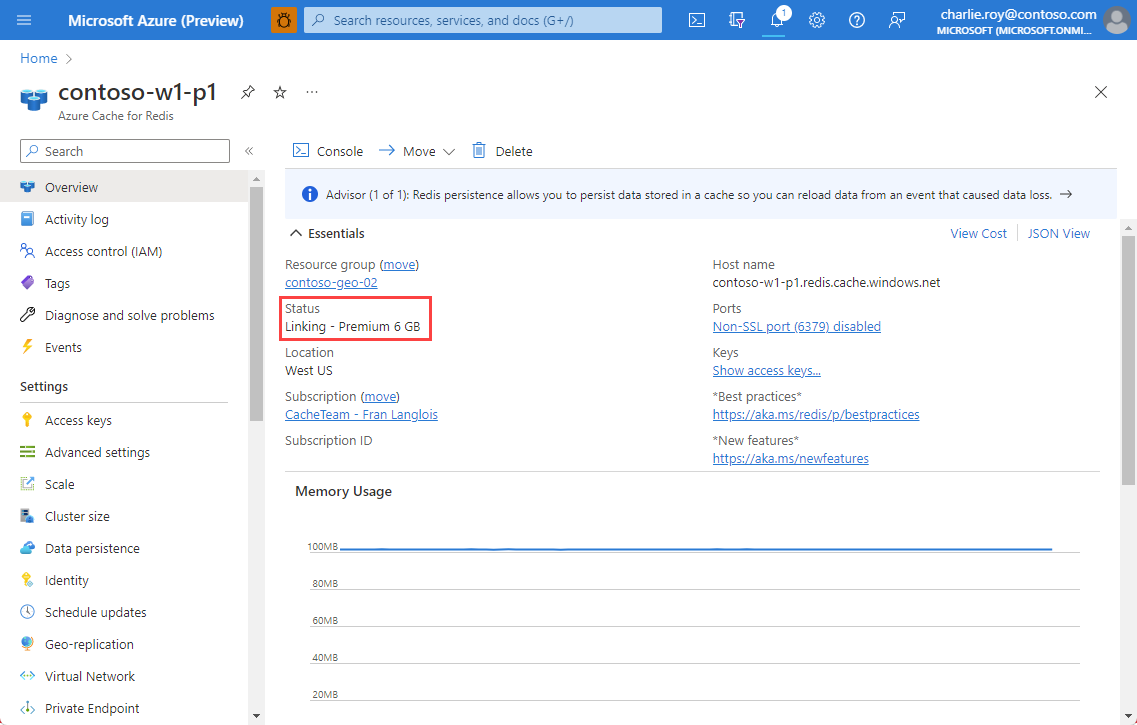
Once the replication process is complete, the Link provisioning status changes to Succeeded.
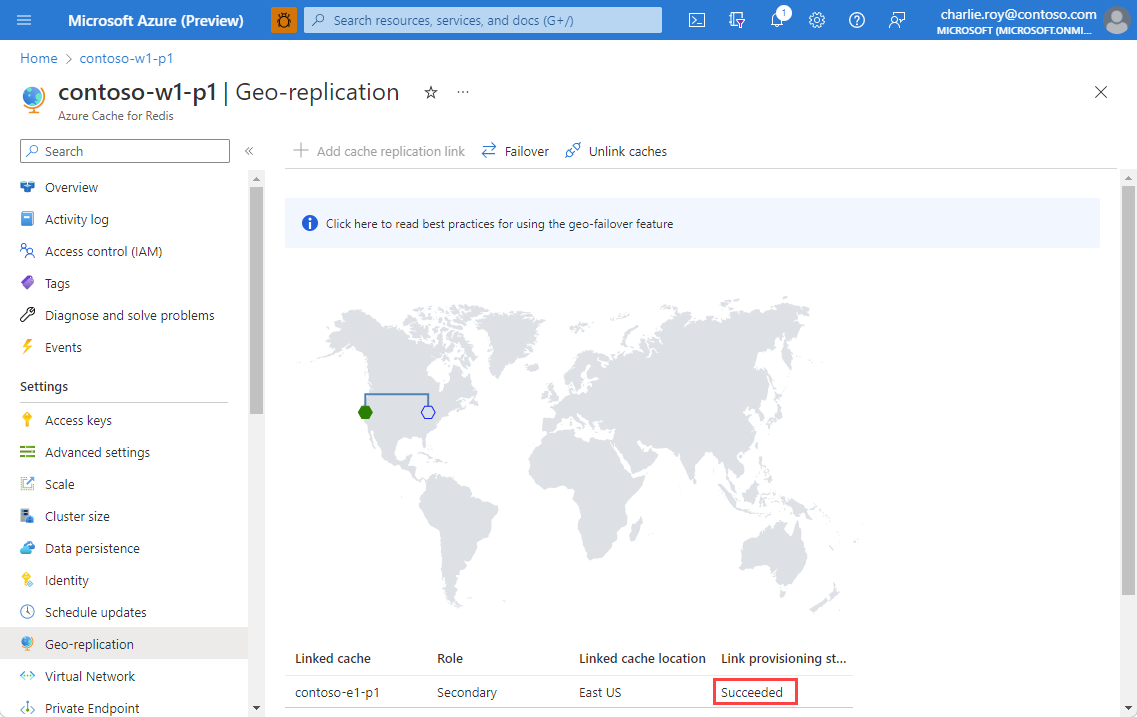
The primary linked cache remains available for use during the linking process. The secondary linked cache isn't available until the linking process completes.
Geo-primary URL
Once the caches are linked, a URL is generated for each cache that always points to the geo-primary cache. If a failover is initiated from the geo-primary to the geo-secondary, the URL remains the same, and the underlying DNS record is updated automatically to point to the new geo-primary.
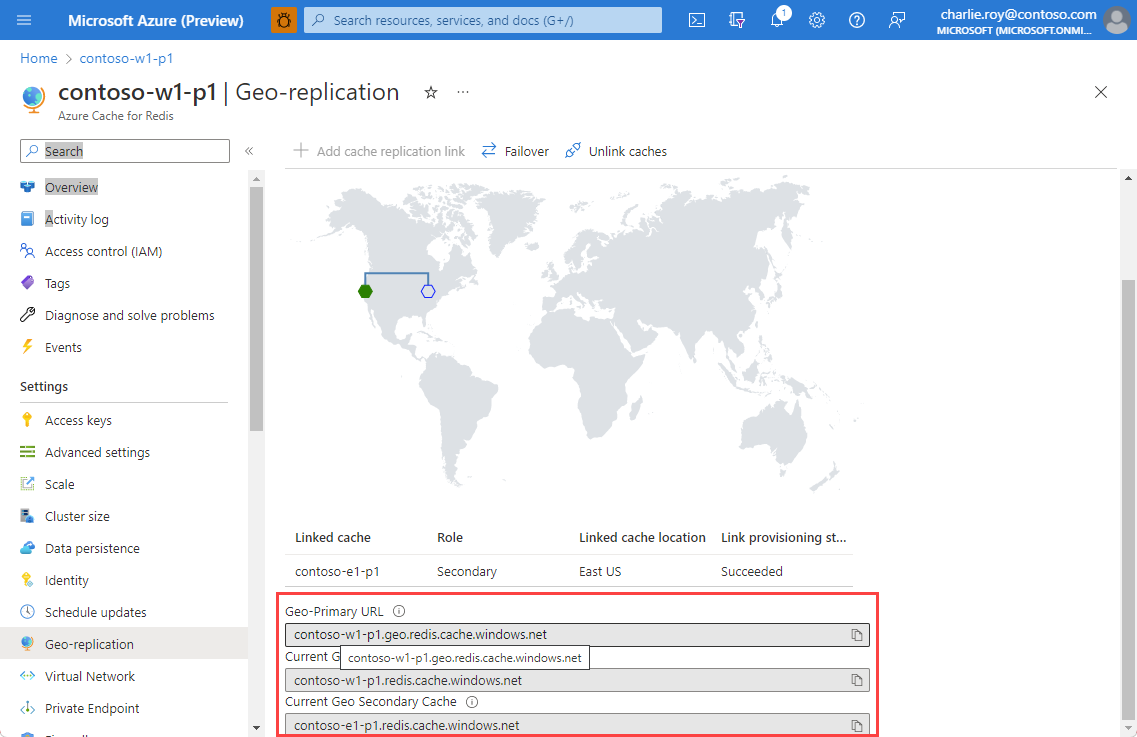
Three URLs are shown:
- Geo-Primary URL is a proxy URL with the format of
<cachename>.geo.redis.cache.windows.net. The URL always points to whichever cache in the geo-replication pair is the current geo-primary. - Current Geo Primary Cache is the direct address of the cache that is currently the geo-primary. The address is
redis.cache.windows.netnotgeo.redis.cache.windows.net. The address listed in the field changes if a failover is initiated. - Current Geo Secondary Cache is the direct address of the cache that is currently the geo-secondary. The address is
redis.cache.windows.netnotgeo.redis.cache.windows.net. The address listed in the field changes if a failover is initiated.
Initiate a failover from geo-primary to geo-secondary
With one select, you can trigger a failover from the geo-primary to the geo-secondary.
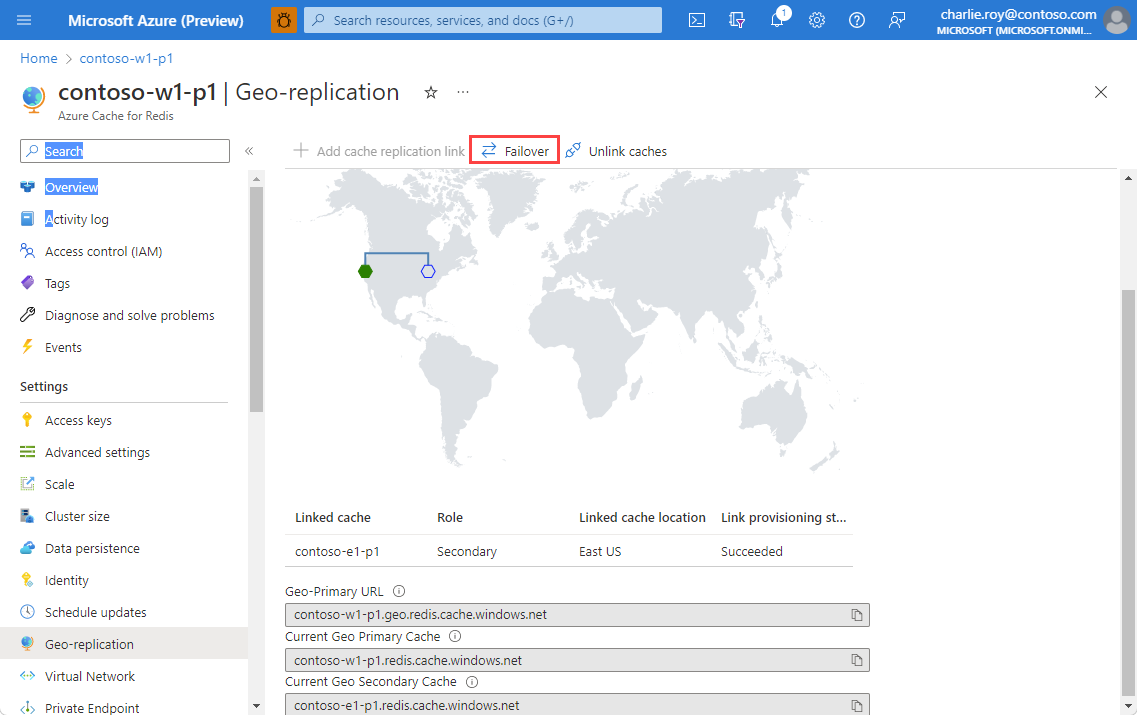
This causes the following steps to be taken:
- The geo-secondary cache is promoted to geo-primary.
- DNS records are updated to redirect the geo-primary URLs to the new geo-primary.
- The old geo-primary cache is demoted to secondary, and attempts to form a link to the new geo-primary cache.
The geo-failover process takes a few minutes to complete.
Settings to check before initiating geo-failover
When the failover is initiated, the geo-primary and geo-secondary caches swap. If the new geo-primary is configured differently from the geo-secondary, it can create problems for your application.
Be sure to check the following items:
- If you’re using a firewall in either cache, make sure that the firewall settings are similar so you have no connection issues.
- Make sure both caches are using the same port and TLS/SSL settings
- The geo-primary and geo-secondary caches have different access keys. If a failover is triggered, make sure your application can update the access key it's using to match the new geo-primary. Or, use Microsoft Entra tokens for cache authentication, which allow you to use the same authentication credential for both the geo-primary and the geo-secondary cache.
Failover with minimal data loss
Geo-failover events can introduce data inconsistencies during the transition, especially if the client maintains a connection to the old geo-primary during the failover process. It's possible to minimize data loss in a planned geo-failover event using the following tips:
- Check the geo-replication data sync offset metric. The metric is emitted by the current geo-primary cache. This metric indicates how much data has yet to be replicated to the geo-primary. If possible, only initiate failover if the metric indicates fewer than 14 bytes remain to be written.
- Run the
CLIENT PAUSEcommand in the current geo-primary before initiating failover. RunningCLIENT PAUSEblocks any new write requests and instead returns timeout failures to the Azure Cache for Redis client. TheCLIENT PAUSEcommand requires providing a timeout period in milliseconds. Make sure a long enough timeout period is provided to allow the failover to occur. Setting the pause value to around 30 minutes (1,800,000 milliseconds) is a good place to start. You can always lower this number as needed.
There's no need to run the CLIENT UNPAUSE command as the new geo-primary does retain the client pause.
Note
Using Microsoft Entra ID based authentication for your cache is recommended in geo-failover scenarios because it removes the difficulty of managing different access keys for the geo-primary and the geo-secondary cache.
Remove a geo-replication link
To remove the link between two caches and stop geo-replication, select Unlink caches from the Geo-replication on the left.
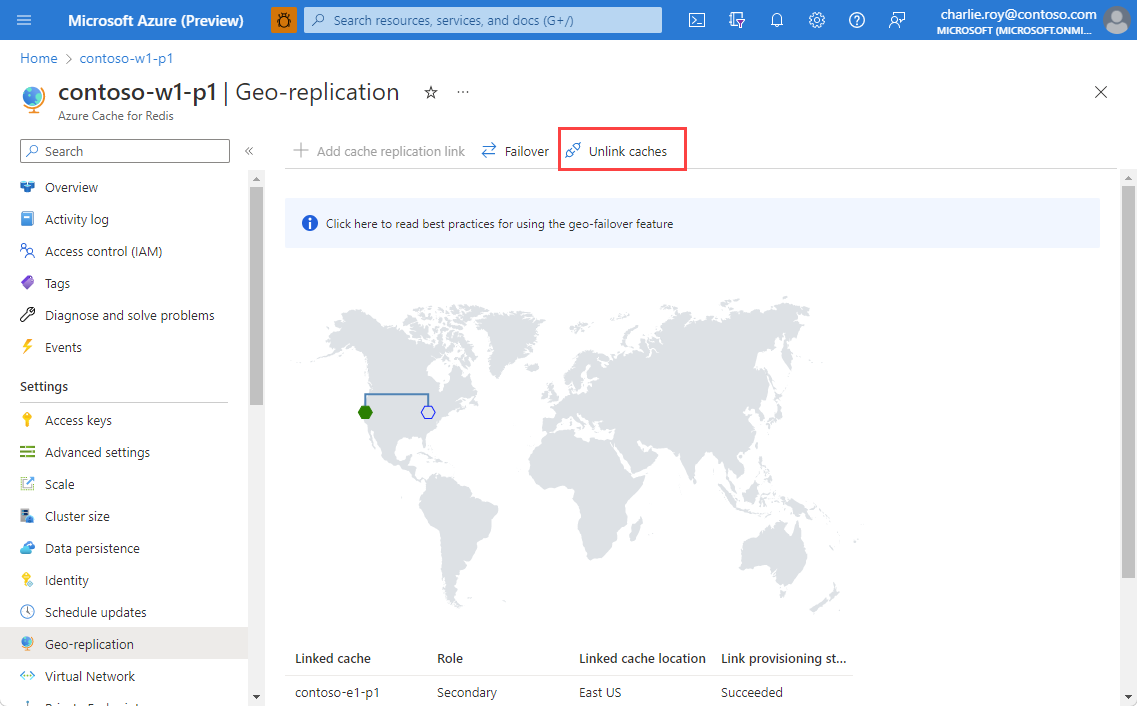
When the unlinking process completes, the secondary cache is available for both reads and writes.
Note
When the geo-replication link is removed, the replicated data from the primary linked cache remains in the secondary cache.
Geo-replication FAQ
- Can I use geo-replication with a Standard or Basic tier cache?
- Is my cache available for use during the linking or unlinking process?
- When can I write to the new geo-primary after initiating failover?
- Can I track the health of the geo-replication link?
- Can I link more than two caches together?
- Can I link two caches from different Azure subscriptions?
- Can I link two caches with different sizes?
- Can I use geo-replication with clustering enabled?
- Can I use geo-replication with my caches in a VNet?
- What is the replication schedule for Redis geo-replication?
- How long does geo-replication replication take?
- Is the replication recovery point guaranteed?
- Can I use PowerShell or Azure CLI to manage geo-replication?
- How much does it cost to replicate my data across Azure regions?
- Why did the operation fail when I tried to delete my linked cache?
- What region should I use for my secondary linked cache?
- Can I configure Firewall with geo-replication?
Can I use geo-replication with a Standard or Basic tier cache?
No, passive geo-replication is only available in the Premium tier. A more advanced version of geo-replication called, active geo-replication, is available in the Enterprise and Enterprise Flash tier.
Is my cache available for use during the linking or unlinking process?
- The primary linked cache remains available until the linking process completes.
- The secondary linked cache isn't available until the linking process completes.
- Both caches remain available until the unlinking process completes.
When can I write to the new geo-primary after initiating failover?
When the failover process is initiated, you see the link provisioning status update to Deleting, which indicates that the previous link is being cleaned up. After this completes, the link provisioning status updates to Creating. This indicates that the new geo-primary is up-and-running and attempting to re-establish a geo-replication link to the old geo-primary cache. At this point, you're able to immediately connect to the new geo-primary cache instance for both reads and writes.
Can I track the health of the geo-replication link?
Yes, there are several metrics available to help track the status of the geo-replication. These metrics are available in the Azure portal.
- Geo Replication Healthy shows the status of the geo-replication link. The link show as unhealthy if either the geo-primary or geo-secondary caches are down. This is typically due to standard patching operations, but it could also indicate a failure situation.
- Geo Replication Connectivity Lag shows the time since the last successful data synchronization between geo-primary and geo-secondary.
- Geo Replication Data Sync Offset shows the amount of data that has yet to be synchronized to the geo-secondary cache.
- Geo Replication Fully Sync Event Started indicates that a full synchronization action has been initiated between the geo-primary and geo-secondary caches. This occurs if standard replication can't keep up with the number of new writes.
- Geo Replication Full Sync Event Finished indicates that a full synchronization action was completed.
There's also a prebuilt workbook called the Geo-Replication Dashboard that includes all of the geo-replication health metrics in one view. Using this view is recommended because it aggregates information that is emitted only from the geo-primary or geo-secondary cache instances.
Can I link more than two caches together?
No, you can only link two caches together when using passive geo-replication. Active geo-replication supports up to five linked caches.
Can I link two caches from different Azure subscriptions?
No, both caches must be in the same Azure subscription.
Can I link two caches with different sizes?
Yes, as long as the secondary linked cache is larger than the primary linked cache. However, you can't use the failover feature if the caches are different sizes.
Can I use geo-replication with clustering enabled?
Yes, as long as both caches have the same number of shards.
Can I use geo-replication with my caches in a VNet?
We recommend using Azure Private Link over VNet injection in most cases. For more information see, Migrate from VNet injection caches to Private Link caches.
While it is still technically possible to use VNet injection when geo-replicating your caches, we recommend Azure Private Link.
Important
Azure Cache for Redis recommends using Azure Private Link, which simplifies the network architecture and secures the connection between endpoints in Azure. You can connect to an Azure Cache instance from your virtual network via a private endpoint, which is assigned a private IP address in a subnet within the virtual network. Azure Private Links is offered on all our tiers, includes Azure Policy support, and simplified NSG rule management. To learn more, see Private Link Documentation. To migrate your VNet injected caches to Private Link, see Migrate from VNet injection caches to Private Link caches.
For more information about support for geo-replication with VNets, see Geo-replication using VNet injection with Premium caches.
What is the replication schedule for Redis geo-replication?
Replication is continuous and asynchronous. It doesn't happen on a specific schedule. All the writes done to the primary are instantaneously and asynchronously replicated on the secondary.
How long does geo-replication replication take?
Replication is incremental, asynchronous, and continuous and the time taken isn't much different from the latency across regions. Under certain circumstances, the secondary cache can be required to do a full sync of the data from the primary. The replication time in this case depends on many factors like: load on the primary cache, available network bandwidth, and inter-region latency. We have found replication time for a full 53-GB geo-replicated pair can be anywhere between 5 to 10 minutes. You can track the amount of data that has yet to be replicated using the Geo Replication Data Sync Offset metric in Azure monitor.
Is the replication recovery point guaranteed?
For caches in a geo-replicated mode, persistence is disabled. If a geo-replicated pair is unlinked, such as a customer-initiated failover, the secondary linked cache keeps its synced data up to that point of time. No recovery point is guaranteed in such situations.
To obtain a recovery point, Export from either cache. You can later Import into the primary linked cache.
Can I use PowerShell or Azure CLI to manage geo-replication?
Yes, geo-replication can be managed using the Azure portal, PowerShell, or Azure CLI. For more information, see the PowerShell docs or Azure CLI docs.
How much does it cost to replicate my data across Azure regions?
When you use geo-replication, data from the primary linked cache is replicated to the secondary linked cache. There's no charge for the data transfer if the two linked caches are in the same region. If the two linked caches are in different regions, the data transfer charge is the network egress cost of data moving across either region. For more information, see Bandwidth Pricing Details.
Why did the operation fail when I tried to delete my linked cache?
Geo-replicated caches and their resource groups can't be deleted while linked until you remove the geo-replication link. If you attempt to delete the resource group that contains one or both of the linked caches, the other resources in the resource group are deleted, but the resource group stays in the deleting state and any linked caches in the resource group remain in the running state. To completely delete the resource group and the linked caches within it, unlink the caches as described in Remove a geo-replication link.
What region should I use for my secondary linked cache?
In general, we recommended for your cache to exist in the same Azure region as the application that accesses it. For applications with separate primary and fallback regions, we recommended your primary and secondary caches exist in those same regions. For more information about paired regions, see Best Practices – Azure Paired regions.
Can I configure a firewall with geo-replication?
Yes, you can configure a firewall with geo-replication. For geo-replication to function alongside a firewall, ensure that the secondary cache's IP address is added to the primary cache's firewall rules. However if public network access is disabled on the cache and only Private Endpoint is enabled, then use of Firewall on the cache isn't supported.
Next steps
Learn more about Azure Cache for Redis features.