Azure Functions Python developer guide
This guide is an introduction to developing Azure Functions by using Python. The article assumes that you've already read the Azure Functions developers guide.
Important
This article supports both the v1 and v2 programming model for Python in Azure Functions. The Python v1 model uses a functions.json file to define functions, and the new v2 model lets you instead use a decorator-based approach. This new approach results in a simpler file structure, and it's more code-centric. Choose the v2 selector at the top of the article to learn about this new programming model.
As a Python developer, you might also be interested in one of the following articles:
| Getting started | Concepts | Scenarios and samples |
|---|---|---|
| Getting started | Concepts | Samples |
|---|---|---|
Development options
Both Python Functions programming models support local development in one of the following environments:
Python v2 programming model:
Note that the Python v2 programming model is only supported in the 4.x functions runtime. For more information, see Azure Functions runtime versions overview.
Python v1 programming model:
You can also create Python v1 functions in the Azure portal.
Tip
Although you can develop your Python-based Azure functions locally on Windows, Python is supported only on a Linux-based hosting plan when it's running in Azure. For more information, see the list of supported operating system/runtime combinations.
Programming model
Azure Functions expects a function to be a stateless method in your Python script that processes input and produces output. By default, the runtime expects the method to be implemented as a global method called main() in the __init__.py file. You can also specify an alternative entry point.
You bind data to the function from triggers and bindings via method attributes that use the name property that's defined in the function.json file. For example, the following function.json file describes a simple function that's triggered by an HTTP request named req:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Based on this definition, the __init__.py file that contains the function code might look like the following example:
def main(req):
user = req.params.get('user')
return f'Hello, {user}!'
You can also explicitly declare the attribute types and return type in the function by using Python type annotations. Doing so helps you to use the IntelliSense and autocomplete features that are provided by many Python code editors.
import azure.functions
def main(req: azure.functions.HttpRequest) -> str:
user = req.params.get('user')
return f'Hello, {user}!'
Use the Python annotations that are included in the azure.functions.* package to bind the input and outputs to your methods.
Azure Functions expects a function to be a stateless method in your Python script that processes input and produces output. By default, the runtime expects the method to be implemented as a global method in the function_app.py file.
Triggers and bindings can be declared and used in a function in a decorator based approach. They're defined in the same file, function_app.py, as the functions. As an example, the following function_app.py file represents a function trigger by an HTTP request.
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req):
user = req.params.get("user")
return f"Hello, {user}!"
You can also explicitly declare the attribute types and return type in the function by using Python type annotations. Doing so helps you use the IntelliSense and autocomplete features that are provided by many Python code editors.
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> str:
user = req.params.get("user")
return f"Hello, {user}!"
To learn about known limitations with the v2 model and their workarounds, see Troubleshoot Python errors in Azure Functions.
Alternative entry point
You can change the default behavior of a function by optionally specifying the scriptFile and entryPoint properties in the function.json file. For example, the following function.json tells the runtime to use the customentry() method in the main.py file as the entry point for your Azure function.
{
"scriptFile": "main.py",
"entryPoint": "customentry",
"bindings": [
...
]
}
The entry point is only in the function_app.py file. However, you can reference functions within the project in function_app.py by using blueprints or by importing.
Folder structure
The recommended folder structure for a Python functions project looks like the following example:
<project_root>/
| - .venv/
| - .vscode/
| - my_first_function/
| | - __init__.py
| | - function.json
| | - example.py
| - my_second_function/
| | - __init__.py
| | - function.json
| - shared_code/
| | - __init__.py
| | - my_first_helper_function.py
| | - my_second_helper_function.py
| - tests/
| | - test_my_second_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
The main project folder, <project_root>, can contain the following files:
- local.settings.json: Used to store app settings and connection strings when running locally. This file doesn't get published to Azure. To learn more, see local.settings.file.
- requirements.txt: Contains the list of Python packages the system installs when publishing to Azure.
- host.json: Contains configuration options that affect all functions in a function app instance. This file does get published to Azure. Not all options are supported when running locally. To learn more, see host.json.
- .vscode/: (Optional) Contains the stored Visual Studio Code configuration. To learn more, see Visual Studio Code settings.
- .venv/: (Optional) Contains a Python virtual environment used by local development.
- Dockerfile: (Optional) Used when publishing your project in a custom container.
- tests/: (Optional) Contains the test cases of your function app.
- .funcignore: (Optional) Declares files that shouldn't get published to Azure. Usually, this file contains .vscode/ to ignore your editor setting, .venv/ to ignore the local Python virtual environment, tests/ to ignore test cases, and local.settings.json to prevent local app settings from being published.
Each function has its own code file and binding configuration file, function.json.
The recommended folder structure for a Python functions project looks like the following example:
<project_root>/
| - .venv/
| - .vscode/
| - function_app.py
| - additional_functions.py
| - tests/
| | - test_my_function.py
| - .funcignore
| - host.json
| - local.settings.json
| - requirements.txt
| - Dockerfile
The main project folder, <project_root>, can contain the following files:
- .venv/: (Optional) Contains a Python virtual environment that's used by local development.
- .vscode/: (Optional) Contains the stored Visual Studio Code configuration. To learn more, see Visual Studio Code settings.
- function_app.py: The default location for all functions and their related triggers and bindings.
- additional_functions.py: (Optional) Any other Python files that contain functions (usually for logical grouping) that are referenced in function_app.py through blueprints.
- tests/: (Optional) Contains the test cases of your function app.
- .funcignore: (Optional) Declares files that shouldn't get published to Azure. Usually, this file contains .vscode/ to ignore your editor setting, .venv/ to ignore local Python virtual environment, tests/ to ignore test cases, and local.settings.json to prevent local app settings being published.
- host.json: Contains configuration options that affect all functions in a function app instance. This file does get published to Azure. Not all options are supported when running locally. To learn more, see host.json.
- local.settings.json: Used to store app settings and connection strings when it's running locally. This file doesn't get published to Azure. To learn more, see local.settings.file.
- requirements.txt: Contains the list of Python packages the system installs when it publishes to Azure.
- Dockerfile: (Optional) Used when publishing your project in a custom container.
When you deploy your project to a function app in Azure, the entire contents of the main project folder, <project_root>, should be included in the package, but not the folder itself, which means that host.json should be in the package root. We recommend that you maintain your tests in a folder along with other functions (in this example, tests/). For more information, see Unit testing.
Connect to a database
Azure Functions integrates well with Azure Cosmos DB for many use cases, including IoT, ecommerce, gaming, etc.
For example, for event sourcing, the two services are integrated to power event-driven architectures using Azure Cosmos DB's change feed functionality. The change feed provides downstream microservices the ability to reliably and incrementally read inserts and updates (for example, order events). This functionality can be leveraged to provide a persistent event store as a message broker for state-changing events and drive order processing workflow between many microservices (which can be implemented as serverless Azure Functions).
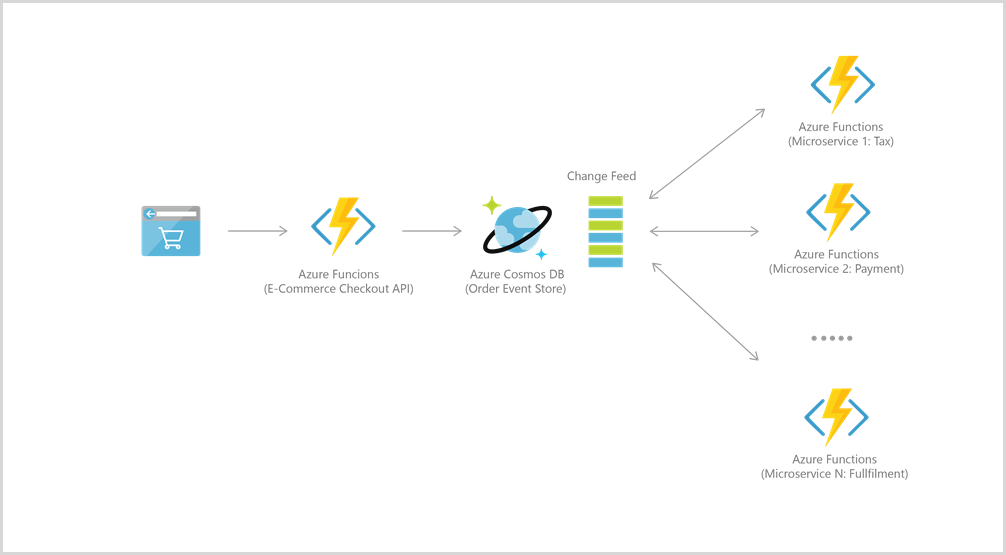
To connect to Cosmos DB, first create an account, database, and container. Then you may connect Functions to Cosmos DB using trigger and bindings, like this example.
To implement more complex app logic, you may also use the Python library for Cosmos DB. An aynchronous I/O implementation looks like this:
pip install azure-cosmos
pip install aiohttp
from azure.cosmos.aio import CosmosClient
from azure.cosmos import exceptions
from azure.cosmos.partition_key import PartitionKey
import asyncio
# Replace these values with your Cosmos DB connection information
endpoint = "https://azure-cosmos-nosql.documents.azure.com:443/"
key = "master_key"
database_id = "cosmicwerx"
container_id = "cosmicontainer"
partition_key = "/partition_key"
# Set the total throughput (RU/s) for the database and container
database_throughput = 1000
# Singleton CosmosClient instance
client = CosmosClient(endpoint, credential=key)
# Helper function to get or create database and container
async def get_or_create_container(client, database_id, container_id, partition_key):
database = await client.create_database_if_not_exists(id=database_id)
print(f'Database "{database_id}" created or retrieved successfully.')
container = await database.create_container_if_not_exists(id=container_id, partition_key=PartitionKey(path=partition_key))
print(f'Container with id "{container_id}" created')
return container
async def create_products():
container = await get_or_create_container(client, database_id, container_id, partition_key)
for i in range(10):
await container.upsert_item({
'id': f'item{i}',
'productName': 'Widget',
'productModel': f'Model {i}'
})
async def get_products():
items = []
container = await get_or_create_container(client, database_id, container_id, partition_key)
async for item in container.read_all_items():
items.append(item)
return items
async def query_products(product_name):
container = await get_or_create_container(client, database_id, container_id, partition_key)
query = f"SELECT * FROM c WHERE c.productName = '{product_name}'"
items = []
async for item in container.query_items(query=query, enable_cross_partition_query=True):
items.append(item)
return items
async def main():
await create_products()
all_products = await get_products()
print('All Products:', all_products)
queried_products = await query_products('Widget')
print('Queried Products:', queried_products)
if __name__ == "__main__":
asyncio.run(main())
Blueprints
The Python v2 programming model introduces the concept of blueprints. A blueprint is a new class that's instantiated to register functions outside of the core function application. The functions registered in blueprint instances aren't indexed directly by the function runtime. To get these blueprint functions indexed, the function app needs to register the functions from blueprint instances.
Using blueprints provides the following benefits:
- Lets you break up the function app into modular components, which enables you to define functions in multiple Python files and divide them into different components per file.
- Provides extensible public function app interfaces to build and reuse your own APIs.
The following example shows how to use blueprints:
First, in an http_blueprint.py file, an HTTP-triggered function is first defined and added to a blueprint object.
import logging
import azure.functions as func
bp = func.Blueprint()
@bp.route(route="default_template")
def default_template(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(
f"Hello, {name}. This HTTP-triggered function "
f"executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. "
"Pass a name in the query string or in the request body for a"
" personalized response.",
status_code=200
)
Next, in the function_app.py file, the blueprint object is imported and its functions are registered to the function app.
import azure.functions as func
from http_blueprint import bp
app = func.FunctionApp()
app.register_functions(bp)
Note
Durable Functions also supports blueprints. To create blueprints for Durable Functions apps, register your orchestration, activity, and entity triggers and client bindings using the azure-functions-durable Blueprint class, as
shown here. The resulting blueprint can then be registered as normal. See our sample for an example.
Import behavior
You can import modules in your function code by using both absolute and relative references. Based on the previously described folder structure, the following imports work from within the function file <project_root>\my_first_function\__init__.py:
from shared_code import my_first_helper_function #(absolute)
import shared_code.my_second_helper_function #(absolute)
from . import example #(relative)
Note
When you're using absolute import syntax, the shared_code/ folder needs to contain an __init__.py file to mark it as a Python package.
The following __app__ import and beyond top-level relative import are deprecated, because they're not supported by the static type checker and not supported by Python test frameworks:
from __app__.shared_code import my_first_helper_function #(deprecated __app__ import)
from ..shared_code import my_first_helper_function #(deprecated beyond top-level relative import)
Triggers and inputs
Inputs are divided into two categories in Azure Functions: trigger input and other input. Although they're different in the function.json file, their usage is identical in Python code. Connection strings or secrets for trigger and input sources map to values in the local.settings.json file when they're running locally, and they map to the application settings when they're running in Azure.
For example, the following code demonstrates the difference between the two inputs:
// function.json
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous",
"route": "items/{id}"
},
{
"name": "obj",
"direction": "in",
"type": "blob",
"path": "samples/{id}",
"connection": "STORAGE_CONNECTION_STRING"
}
]
}
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>"
}
}
# __init__.py
import azure.functions as func
import logging
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
When the function is invoked, the HTTP request is passed to the function as req. An entry will be retrieved from the Azure Blob Storage account based on the ID in the route URL and made available as obj in the function body. Here, the specified storage account is the connection string that's found in the CONNECTION_STRING app setting.
Inputs are divided into two categories in Azure Functions: trigger input and other input. Although they're defined using different decorators, their usage is similar in Python code. Connection strings or secrets for trigger and input sources map to values in the local.settings.json file when they're running locally, and they map to the application settings when they're running in Azure.
As an example, the following code demonstrates how to define a Blob Storage input binding:
// local.settings.json
{
"IsEncrypted": false,
"Values": {
"FUNCTIONS_WORKER_RUNTIME": "python",
"STORAGE_CONNECTION_STRING": "<AZURE_STORAGE_CONNECTION_STRING>",
"AzureWebJobsStorage": "<azure-storage-connection-string>",
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
}
}
# function_app.py
import azure.functions as func
import logging
app = func.FunctionApp()
@app.route(route="req")
@app.read_blob(arg_name="obj", path="samples/{id}",
connection="STORAGE_CONNECTION_STRING")
def main(req: func.HttpRequest, obj: func.InputStream):
logging.info(f'Python HTTP-triggered function processed: {obj.read()}')
When the function is invoked, the HTTP request is passed to the function as req. An entry will be retrieved from the Azure Blob Storage account based on the ID in the route URL and made available as obj in the function body. Here, the specified storage account is the connection string that's found in the STORAGE_CONNECTION_STRING app setting.
For data intensive binding operations, you may want to use a separate storage account. For more information, see Storage account guidance.
Outputs
Output can be expressed both in return value and output parameters. If there's only one output, we recommend using the return value. For multiple outputs, you'll have to use output parameters.
To use the return value of a function as the value of an output binding, the name property of the binding should be set to $return in the function.json file.
To produce multiple outputs, use the set() method provided by the azure.functions.Out interface to assign a value to the binding. For example, the following function can push a message to a queue and also return an HTTP response.
{
"scriptFile": "__init__.py",
"bindings": [
{
"name": "req",
"direction": "in",
"type": "httpTrigger",
"authLevel": "anonymous"
},
{
"name": "msg",
"direction": "out",
"type": "queue",
"queueName": "outqueue",
"connection": "STORAGE_CONNECTION_STRING"
},
{
"name": "$return",
"direction": "out",
"type": "http"
}
]
}
import azure.functions as func
def main(req: func.HttpRequest,
msg: func.Out[func.QueueMessage]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Output can be expressed both in return value and output parameters. If there's only one output, we recommend using the return value. For multiple outputs, you'll have to use output parameters.
To produce multiple outputs, use the set() method provided by the azure.functions.Out interface to assign a value to the binding. For example, the following function can push a message to a queue and also return an HTTP response.
# function_app.py
import azure.functions as func
app = func.FunctionApp()
@app.write_blob(arg_name="msg", path="output-container/{name}",
connection="CONNECTION_STRING")
def test_function(req: func.HttpRequest,
msg: func.Out[str]) -> str:
message = req.params.get('body')
msg.set(message)
return message
Logging
Access to the Azure Functions runtime logger is available via a root logging handler in your function app. This logger is tied to Application Insights and allows you to flag warnings and errors that occur during the function execution.
The following example logs an info message when the function is invoked via an HTTP trigger.
import logging
def main(req):
logging.info('Python HTTP trigger function processed a request.')
More logging methods are available that let you write to the console at different trace levels:
| Method | Description |
|---|---|
critical(_message_) |
Writes a message with level CRITICAL on the root logger. |
error(_message_) |
Writes a message with level ERROR on the root logger. |
warning(_message_) |
Writes a message with level WARNING on the root logger. |
info(_message_) |
Writes a message with level INFO on the root logger. |
debug(_message_) |
Writes a message with level DEBUG on the root logger. |
To learn more about logging, see Monitor Azure Functions.
Logging from created threads
To see logs coming from your created threads, include the context argument in the function's signature. This argument contains an attribute thread_local_storage which stores a local invocation_id. This can be set to the function's current invocation_id to ensure the context is changed.
import azure.functions as func
import logging
import threading
def main(req, context):
logging.info('Python HTTP trigger function processed a request.')
t = threading.Thread(target=log_function, args=(context,))
t.start()
def log_function(context):
context.thread_local_storage.invocation_id = context.invocation_id
logging.info('Logging from thread.')
Log custom telemetry
By default, the Functions runtime collects logs and other telemetry data that are generated by your functions. This telemetry ends up as traces in Application Insights. Request and dependency telemetry for certain Azure services are also collected by default by triggers and bindings.
To collect custom request and custom dependency telemetry outside of bindings, you can use the OpenCensus Python Extensions. This extension sends custom telemetry data to your Application Insights instance. You can find a list of supported extensions at the OpenCensus repository.
Note
To use the OpenCensus Python extensions, you need to enable Python worker extensions in your function app by setting PYTHON_ENABLE_WORKER_EXTENSIONS to 1. You also need to switch to using the Application Insights connection string by adding the APPLICATIONINSIGHTS_CONNECTION_STRING setting to your application settings, if it's not already there.
// requirements.txt
...
opencensus-extension-azure-functions
opencensus-ext-requests
import json
import logging
import requests
from opencensus.extension.azure.functions import OpenCensusExtension
from opencensus.trace import config_integration
config_integration.trace_integrations(['requests'])
OpenCensusExtension.configure()
def main(req, context):
logging.info('Executing HttpTrigger with OpenCensus extension')
# You must use context.tracer to create spans
with context.tracer.span("parent"):
response = requests.get(url='http://example.com')
return json.dumps({
'method': req.method,
'response': response.status_code,
'ctx_func_name': context.function_name,
'ctx_func_dir': context.function_directory,
'ctx_invocation_id': context.invocation_id,
'ctx_trace_context_Traceparent': context.trace_context.Traceparent,
'ctx_trace_context_Tracestate': context.trace_context.Tracestate,
'ctx_retry_context_RetryCount': context.retry_context.retry_count,
'ctx_retry_context_MaxRetryCount': context.retry_context.max_retry_count,
})
HTTP trigger
The HTTP trigger is defined in the function.json file. The name of the binding must match the named parameter in the function.
In the previous examples, a binding name req is used. This parameter is an HttpRequest object, and an HttpResponse object is returned.
From the HttpRequest object, you can get request headers, query parameters, route parameters, and the message body.
The following example is from the HTTP trigger template for Python.
def main(req: func.HttpRequest) -> func.HttpResponse:
headers = {"my-http-header": "some-value"}
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello {name}!", headers=headers)
else:
return func.HttpResponse(
"Please pass a name on the query string or in the request body",
headers=headers, status_code=400
)
In this function, you obtain the value of the name query parameter from the params parameter of the HttpRequest object. You read the JSON-encoded message body by using the get_json method.
Likewise, you can set the status_code and headers for the response message in the returned HttpResponse object.
The HTTP trigger is defined as a method that takes a named binding parameter, which is an HttpRequest object, and returns an HttpResponse object. You apply the function_name decorator to the method to define the function name, while the HTTP endpoint is set by applying the route decorator.
This example is from the HTTP trigger template for the Python v2 programming model, where the binding parameter name is req. It's the sample code that's provided when you create a function by using Azure Functions Core Tools or Visual Studio Code.
@app.function_name(name="HttpTrigger1")
@app.route(route="hello")
def test_function(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Python HTTP trigger function processed a request.')
name = req.params.get('name')
if not name:
try:
req_body = req.get_json()
except ValueError:
pass
else:
name = req_body.get('name')
if name:
return func.HttpResponse(f"Hello, {name}. This HTTP-triggered function executed successfully.")
else:
return func.HttpResponse(
"This HTTP-triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response.",
status_code=200
)
From the HttpRequest object, you can get request headers, query parameters, route parameters, and the message body. In this function, you obtain the value of the name query parameter from the params parameter of the HttpRequest object. You read the JSON-encoded message body by using the get_json method.
Likewise, you can set the status_code and headers for the response message in the returned HttpResponse object.
To pass in a name in this example, paste the URL that's provided when you're running the function, and then append it with "?name={name}".
Web frameworks
You can use Web Server Gateway Interface (WSGI)-compatible and Asynchronous Server Gateway Interface (ASGI)-compatible frameworks, such as Flask and FastAPI, with your HTTP-triggered Python functions. This section shows how to modify your functions to support these frameworks.
First, the function.json file must be updated to include a route in the HTTP trigger, as shown in the following example:
{
"scriptFile": "__init__.py",
"bindings": [
{
"authLevel": "anonymous",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
],
"route": "{*route}"
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
The host.json file must also be updated to include an HTTP routePrefix, as shown in the following example:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[3.*, 4.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
Update the Python code file init.py, depending on the interface that's used by your framework. The following example shows either an ASGI handler approach or a WSGI wrapper approach for Flask:
You can use Asynchronous Server Gateway Interface (ASGI)-compatible and Web Server Gateway Interface (WSGI)-compatible frameworks, such as Flask and FastAPI, with your HTTP-triggered Python functions. You must first update the host.json file to include an HTTP routePrefix, as shown in the following example:
{
"version": "2.0",
"logging":
{
"applicationInsights":
{
"samplingSettings":
{
"isEnabled": true,
"excludedTypes": "Request"
}
}
},
"extensionBundle":
{
"id": "Microsoft.Azure.Functions.ExtensionBundle",
"version": "[2.*, 3.0.0)"
},
"extensions":
{
"http":
{
"routePrefix": ""
}
}
}
The framework code looks like the following example:
AsgiFunctionApp is the top-level function app class for constructing ASGI HTTP functions.
# function_app.py
import azure.functions as func
from fastapi import FastAPI, Request, Response
fast_app = FastAPI()
@fast_app.get("/return_http_no_body")
async def return_http_no_body():
return Response(content="", media_type="text/plain")
app = func.AsgiFunctionApp(app=fast_app,
http_auth_level=func.AuthLevel.ANONYMOUS)
Scaling and performance
For scaling and performance best practices for Python function apps, see the Python scaling and performance article.
Context
To get the invocation context of a function when it's running, include the context argument in its signature.
For example:
import azure.functions
def main(req: azure.functions.HttpRequest,
context: azure.functions.Context) -> str:
return f'{context.invocation_id}'
The Context class has the following string attributes:
| Attribute | Description |
|---|---|
function_directory |
The directory in which the function is running. |
function_name |
The name of the function. |
invocation_id |
The ID of the current function invocation. |
thread_local_storage |
The thread local storage of the function. Contains a local invocation_id for logging from created threads. |
trace_context |
The context for distributed tracing. For more information, see Trace Context. |
retry_context |
The context for retries to the function. For more information, see retry-policies. |
Global variables
It isn't guaranteed that the state of your app will be preserved for future executions. However, the Azure Functions runtime often reuses the same process for multiple executions of the same app. To cache the results of an expensive computation, declare it as a global variable.
CACHED_DATA = None
def main(req):
global CACHED_DATA
if CACHED_DATA is None:
CACHED_DATA = load_json()
# ... use CACHED_DATA in code
Environment variables
In Azure Functions, application settings, such as service connection strings, are exposed as environment variables when they're running. There are two main ways to access these settings in your code.
| Method | Description |
|---|---|
os.environ["myAppSetting"] |
Tries to get the application setting by key name, and raises an error when it's unsuccessful. |
os.getenv("myAppSetting") |
Tries to get the application setting by key name, and returns null when it's unsuccessful. |
Both of these ways require you to declare import os.
The following example uses os.environ["myAppSetting"] to get the application setting, with the key named myAppSetting:
import logging
import os
import azure.functions as func
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
For local development, application settings are maintained in the local.settings.json file.
In Azure Functions, application settings, such as service connection strings, are exposed as environment variables when they're running. There are two main ways to access these settings in your code.
| Method | Description |
|---|---|
os.environ["myAppSetting"] |
Tries to get the application setting by key name, and raises an error when it's unsuccessful. |
os.getenv("myAppSetting") |
Tries to get the application setting by key name, and returns null when it's unsuccessful. |
Both of these ways require you to declare import os.
The following example uses os.environ["myAppSetting"] to get the application setting, with the key named myAppSetting:
import logging
import os
import azure.functions as func
app = func.FunctionApp()
@app.function_name(name="HttpTrigger1")
@app.route(route="req")
def main(req: func.HttpRequest) -> func.HttpResponse:
# Get the setting named 'myAppSetting'
my_app_setting_value = os.environ["myAppSetting"]
logging.info(f'My app setting value:{my_app_setting_value}')
For local development, application settings are maintained in the local.settings.json file.
When you're using the new programming model, enable the following app setting in the local.settings.json file, as shown here:
"AzureWebJobsFeatureFlags": "EnableWorkerIndexing"
When you're deploying the function, this setting isn't created automatically. You must explicitly create this setting in your function app in Azure for it to run by using the v2 model.
Python version
Azure Functions supports the following Python versions:
| Functions version | Python* versions |
|---|---|
| 4.x | 3.11 3.10 3.9 3.8 3.7 |
| 3.x | 3.9 3.8 3.7 |
* Official Python distributions
To request a specific Python version when you create your function app in Azure, use the --runtime-version option of the az functionapp create command. The Functions runtime version is set by the --functions-version option. The Python version is set when the function app is created, and it can't be changed for apps running in a Consumption plan.
The runtime uses the available Python version when you run it locally.
Changing Python version
To set a Python function app to a specific language version, you need to specify the language and the version of the language in the LinuxFxVersion field in the site configuration. For example, to change the Python app to use Python 3.8, set linuxFxVersion to python|3.8.
To learn how to view and change the linuxFxVersion site setting, see How to target Azure Functions runtime versions.
For more general information, see the Azure Functions runtime support policy and Supported languages in Azure Functions.
Package management
When you're developing locally by using Core Tools or Visual Studio Code, add the names and versions of the required packages to the requirements.txt file, and then install them by using pip.
For example, you can use the following requirements.txt file and pip command to install the requests package from PyPI.
requests==2.19.1
pip install -r requirements.txt
When running your functions in an App Service plan, dependencies that you define in requirements.txt are given precedence over built-in Python modules, such as logging. This precedence can cause conflicts when built-in modules have the same names as directories in your code. When running in a Consumption plan or an Elastic Premium plan, conflicts are less likely because your dependencies aren't prioritized by default.
To prevent issues running in an App Service plan, don't name your directories the same as any Python native modules and don't include Python native libraries in your project's requirements.txt file.
Publishing to Azure
When you're ready to publish, make sure that all your publicly available dependencies are listed in the requirements.txt file. You can locate this file at the root of your project directory.
You can find the project files and folders that are excluded from publishing, including the virtual environment folder, in the root directory of your project.
There are three build actions supported for publishing your Python project to Azure: remote build, local build, and builds using custom dependencies.
You can also use Azure Pipelines to build your dependencies and publish by using continuous delivery (CD). To learn more, see Continuous delivery with Azure Pipelines.
Remote build
When you use remote build, dependencies that are restored on the server and native dependencies match the production environment. This results in a smaller deployment package to upload. Use remote build when you're developing Python apps on Windows. If your project has custom dependencies, you can use remote build with extra index URL.
Dependencies are obtained remotely based on the contents of the requirements.txt file. Remote build is the recommended build method. By default, Core Tools requests a remote build when you use the following func azure functionapp publish command to publish your Python project to Azure.
func azure functionapp publish <APP_NAME>
Remember to replace <APP_NAME> with the name of your function app in Azure.
The Azure Functions Extension for Visual Studio Code also requests a remote build by default.
Local build
Dependencies are obtained locally based on the contents of the requirements.txt file. You can prevent doing a remote build by using the following func azure functionapp publish command to publish with a local build:
func azure functionapp publish <APP_NAME> --build local
Remember to replace <APP_NAME> with the name of your function app in Azure.
When you use the --build local option, project dependencies are read from the requirements.txt file, and those dependent packages are downloaded and installed locally. Project files and dependencies are deployed from your local computer to Azure. This results in a larger deployment package being uploaded to Azure. If for some reason you can't get the requirements.txt file by using Core Tools, you must use the custom dependencies option for publishing.
We don't recommend using local builds when you're developing locally on Windows.
Custom dependencies
When your project has dependencies that aren't found in the Python Package Index, there are two ways to build the project. The first way, the build method, depends on how you build the project.
Remote build with extra index URL
When your packages are available from an accessible custom package index, use a remote build. Before you publish, be sure to create an app setting named PIP_EXTRA_INDEX_URL. The value for this setting is the URL of your custom package index. Using this setting tells the remote build to run pip install by using the --extra-index-url option. To learn more, see the Python pip install documentation.
You can also use basic authentication credentials with your extra package index URLs. To learn more, see Basic authentication credentials in the Python documentation.
Install local packages
If your project uses packages that aren't publicly available to our tools, you can make them available to your app by putting them in the __app__/.python_packages directory. Before you publish, run the following command to install the dependencies locally:
pip install --target="<PROJECT_DIR>/.python_packages/lib/site-packages" -r requirements.txt
When you're using custom dependencies, you should use the --no-build publishing option, because you've already installed the dependencies into the project folder.
func azure functionapp publish <APP_NAME> --no-build
Remember to replace <APP_NAME> with the name of your function app in Azure.
Unit testing
Functions that are written in Python can be tested like other Python code by using standard testing frameworks. For most bindings, it's possible to create a mock input object by creating an instance of an appropriate class from the azure.functions package. Since the azure.functions package isn't immediately available, be sure to install it via your requirements.txt file as described in the package management section above.
With my_second_function as an example, the following is a mock test of an HTTP-triggered function:
First, create a <project_root>/my_second_function/function.json file, and then define this function as an HTTP trigger.
{
"scriptFile": "__init__.py",
"entryPoint": "main",
"bindings": [
{
"authLevel": "function",
"type": "httpTrigger",
"direction": "in",
"name": "req",
"methods": [
"get",
"post"
]
},
{
"type": "http",
"direction": "out",
"name": "$return"
}
]
}
Next, you can implement my_second_function and shared_code.my_second_helper_function.
# <project_root>/my_second_function/__init__.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
# Define an HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
You can start writing test cases for your HTTP trigger.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from my_second_function import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
resp = main(req)
# Check the output.
self.assertEqual(resp.get_body(), b'21 * 2 = 42',)
Inside your .venv Python virtual environment folder, install your favorite Python test framework, such as pip install pytest. Then run pytest tests to check the test result.
First, create the <project_root>/function_app.py file and implement the my_second_function function as the HTTP trigger and shared_code.my_second_helper_function.
# <project_root>/function_app.py
import azure.functions as func
import logging
# Use absolute import to resolve shared_code modules
from shared_code import my_second_helper_function
app = func.FunctionApp()
# Define the HTTP trigger that accepts the ?value=<int> query parameter
# Double the value and return the result in HttpResponse
@app.function_name(name="my_second_function")
@app.route(route="hello")
def main(req: func.HttpRequest) -> func.HttpResponse:
logging.info('Executing my_second_function.')
initial_value: int = int(req.params.get('value'))
doubled_value: int = my_second_helper_function.double(initial_value)
return func.HttpResponse(
body=f"{initial_value} * 2 = {doubled_value}",
status_code=200
)
# <project_root>/shared_code/__init__.py
# Empty __init__.py file marks shared_code folder as a Python package
# <project_root>/shared_code/my_second_helper_function.py
def double(value: int) -> int:
return value * 2
You can start writing test cases for your HTTP trigger.
# <project_root>/tests/test_my_second_function.py
import unittest
import azure.functions as func
from function_app import main
class TestFunction(unittest.TestCase):
def test_my_second_function(self):
# Construct a mock HTTP request.
req = func.HttpRequest(method='GET',
body=None,
url='/api/my_second_function',
params={'value': '21'})
# Call the function.
func_call = main.build().get_user_function()
resp = func_call(req)
# Check the output.
self.assertEqual(
resp.get_body(),
b'21 * 2 = 42',
)
Inside your .venv Python virtual environment folder, install your favorite Python test framework, such as pip install pytest. Then run pytest tests to check the test result.
Temporary files
The tempfile.gettempdir() method returns a temporary folder, which on Linux is /tmp. Your application can use this directory to store temporary files that are generated and used by your functions when they're running.
Important
Files written to the temporary directory aren't guaranteed to persist across invocations. During scale out, temporary files aren't shared between instances.
The following example creates a named temporary file in the temporary directory (/tmp):
import logging
import azure.functions as func
import tempfile
from os import listdir
#---
tempFilePath = tempfile.gettempdir()
fp = tempfile.NamedTemporaryFile()
fp.write(b'Hello world!')
filesDirListInTemp = listdir(tempFilePath)
We recommend that you maintain your tests in a folder that's separate from the project folder. This action keeps you from deploying test code with your app.
Preinstalled libraries
A few libraries come with the Python functions runtime.
The Python standard library
The Python standard library contains a list of built-in Python modules that are shipped with each Python distribution. Most of these libraries help you access system functionality, such as file input/output (I/O). On Windows systems, these libraries are installed with Python. On Unix-based systems, they're provided by package collections.
To view the library for your Python version, go to:
- Python 3.8 standard library
- Python 3.9 standard library
- Python 3.10 standard library
- Python 3.11 standard library
Azure Functions Python worker dependencies
The Azure Functions Python worker requires a specific set of libraries. You can also use these libraries in your functions, but they aren't a part of the Python standard. If your functions rely on any of these libraries, they might be unavailable to your code when it's running outside of Azure Functions. You'll find a detailed list of dependencies in the "install_requires" section of the setup.py file.
Note
If your function app's requirements.txt file contains an azure-functions-worker entry, remove it. The functions worker is automatically managed by the Azure Functions platform, and we regularly update it with new features and bug fixes. Manually installing an old version of worker in the requirements.txt file might cause unexpected issues.
Note
If your package contains certain libraries that might collide with worker's dependencies (for example, protobuf, tensorflow, or grpcio), configure PYTHON_ISOLATE_WORKER_DEPENDENCIES to 1 in app settings to prevent your application from referring to worker's dependencies.
The Azure Functions Python library
Every Python worker update includes a new version of the Azure Functions Python library (azure.functions). This approach makes it easier to continuously update your Python function apps, because each update is backwards-compatible. For a list of releases of this library, go to azure-functions PyPi.
The runtime library version is fixed by Azure, and it can't be overridden by requirements.txt. The azure-functions entry in requirements.txt is only for linting and customer awareness.
Use the following code to track the actual version of the Python functions library in your runtime:
getattr(azure.functions, '__version__', '< 1.2.1')
Runtime system libraries
For a list of preinstalled system libraries in Python worker Docker images, see the following:
| Functions runtime | Debian version | Python versions |
|---|---|---|
| Version 3.x | Buster | Python 3.7 Python 3.8 Python 3.9 |
Python worker extensions
The Python worker process that runs in Azure Functions lets you integrate third-party libraries into your function app. These extension libraries act as middleware that can inject specific operations during the lifecycle of your function's execution.
Extensions are imported in your function code much like a standard Python library module. Extensions are run based on the following scopes:
| Scope | Description |
|---|---|
| Application-level | When imported into any function trigger, the extension applies to every function execution in the app. |
| Function-level | Execution is limited to only the specific function trigger into which it's imported. |
Review the information for each extension to learn more about the scope in which the extension runs.
Extensions implement a Python worker extension interface. This action lets the Python worker process call into the extension code during the function's execution lifecycle. To learn more, see Create extensions.
Using extensions
You can use a Python worker extension library in your Python functions by doing the following:
- Add the extension package in the requirements.txt file for your project.
- Install the library into your app.
- Add the following application settings:
- Locally: Enter
"PYTHON_ENABLE_WORKER_EXTENSIONS": "1"in theValuessection of your local.settings.json file. - Azure: Enter
PYTHON_ENABLE_WORKER_EXTENSIONS=1in your app settings.
- Locally: Enter
- Import the extension module into your function trigger.
- Configure the extension instance, if needed. Configuration requirements should be called out in the extension's documentation.
Important
Third-party Python worker extension libraries aren't supported or warrantied by Microsoft. You must make sure that any extensions that you use in your function app is trustworthy, and you bear the full risk of using a malicious or poorly written extension.
Third-parties should provide specific documentation on how to install and consume their extensions in your function app. For a basic example of how to consume an extension, see Consuming your extension.
Here are examples of using extensions in a function app, by scope:
# <project_root>/requirements.txt
application-level-extension==1.0.0
# <project_root>/Trigger/__init__.py
from application_level_extension import AppExtension
AppExtension.configure(key=value)
def main(req, context):
# Use context.app_ext_attributes here
Creating extensions
Extensions are created by third-party library developers who have created functionality that can be integrated into Azure Functions. An extension developer designs, implements, and releases Python packages that contain custom logic designed specifically to be run in the context of function execution. These extensions can be published either to the PyPI registry or to GitHub repositories.
To learn how to create, package, publish, and consume a Python worker extension package, see Develop Python worker extensions for Azure Functions.
Application-level extensions
An extension that's inherited from AppExtensionBase runs in an application scope.
AppExtensionBase exposes the following abstract class methods for you to implement:
| Method | Description |
|---|---|
init |
Called after the extension is imported. |
configure |
Called from function code when it's needed to configure the extension. |
post_function_load_app_level |
Called right after the function is loaded. The function name and function directory are passed to the extension. Keep in mind that the function directory is read-only, and any attempt to write to a local file in this directory fails. |
pre_invocation_app_level |
Called right before the function is triggered. The function context and function invocation arguments are passed to the extension. You can usually pass other attributes in the context object for the function code to consume. |
post_invocation_app_level |
Called right after the function execution finishes. The function context, function invocation arguments, and invocation return object are passed to the extension. This implementation is a good place to validate whether execution of the lifecycle hooks succeeded. |
Function-level extensions
An extension that inherits from FuncExtensionBase runs in a specific function trigger.
FuncExtensionBase exposes the following abstract class methods for implementations:
| Method | Description |
|---|---|
__init__ |
The constructor of the extension. It's called when an extension instance is initialized in a specific function. When you're implementing this abstract method, you might want to accept a filename parameter and pass it to the parent's method super().__init__(filename) for proper extension registration. |
post_function_load |
Called right after the function is loaded. The function name and function directory are passed to the extension. Keep in mind that the function directory is read-only, and any attempt to write to a local file in this directory fails. |
pre_invocation |
Called right before the function is triggered. The function context and function invocation arguments are passed to the extension. You can usually pass other attributes in the context object for the function code to consume. |
post_invocation |
Called right after the function execution finishes. The function context, function invocation arguments, and invocation return object are passed to the extension. This implementation is a good place to validate whether execution of the lifecycle hooks succeeded. |
Cross-origin resource sharing
Azure Functions supports cross-origin resource sharing (CORS). CORS is configured in the portal and through the Azure CLI. The CORS allowed origins list applies at the function app level. With CORS enabled, responses include the Access-Control-Allow-Origin header. For more information, see Cross-origin resource sharing.
Cross-origin resource sharing (CORS) is fully supported for Python function apps.
Async
By default, a host instance for Python can process only one function invocation at a time. This is because Python is a single-threaded runtime. For a function app that processes a large number of I/O events or is being I/O bound, you can significantly improve performance by running functions asynchronously. For more information, see Improve throughout performance of Python apps in Azure Functions.
Shared memory (preview)
To improve throughput, Azure Functions lets your out-of-process Python language worker share memory with the Functions host process. When your function app is hitting bottlenecks, you can enable shared memory by adding an application setting named FUNCTIONS_WORKER_SHARED_MEMORY_DATA_TRANSFER_ENABLED with a value of 1. With shared memory enabled, you can then use the DOCKER_SHM_SIZE setting to set the shared memory to something like 268435456, which is equivalent to 256 MB.
For example, you might enable shared memory to reduce bottlenecks when you're using Blob Storage bindings to transfer payloads larger than 1 MB.
This functionality is available only for function apps that are running in Premium and Dedicated (Azure App Service) plans. To learn more, see Shared memory.
Known issues and FAQ
Here are two troubleshooting guides for common issues:
Here are two troubleshooting guides for known issues with the v2 programming model:
All known issues and feature requests are tracked in a GitHub issues list. If you run into a problem and can't find the issue in GitHub, open a new issue, and include a detailed description of the problem.
Next steps
For more information, see the following resources:
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for