Hyperscale distributed functions architecture
Applies to: ![]() Azure SQL Database
Azure SQL Database
The Hyperscale service tier utilizes an architecture with highly scalable and separate storage and compute tiers. This article describes the components that enable customers to quickly scale Hyperscale databases while benefiting from nearly instantaneous backups and highly scalable transaction logging.
Tip
Simplified pricing for SQL Database Hyperscale arrived in December 2023. Review the Hyperscale pricing blog for details.
Hyperscale architecture overview
Traditional database engines centralize data management functions in a single process: even so-called distributed databases in production today have multiple copies of a monolithic data engine.
Hyperscale databases follow a different approach. Hyperscale separates the query processing engine, where the semantics of various data engines diverge, from the components that provide long-term storage and durability for the data. In this way, storage capacity can be smoothly scaled out as far as needed. The initially supported storage limit is 100 TB.
All network communication among Hyperscale components uses Azure network infrastructure with built-in redundancy.
High-availability secondary replicas and named replicas are optional compute nodes that can be added on demand. Both share the same storage components, so no data copy is required to spin up a new replica. A geo-secondary replica can be added on demand in the same or a different Azure region. For data protection and redundancy, geo-secondary replicas have storage components that are separate from those used by the primary replica.
The following diagram illustrates the functional Hyperscale architecture:
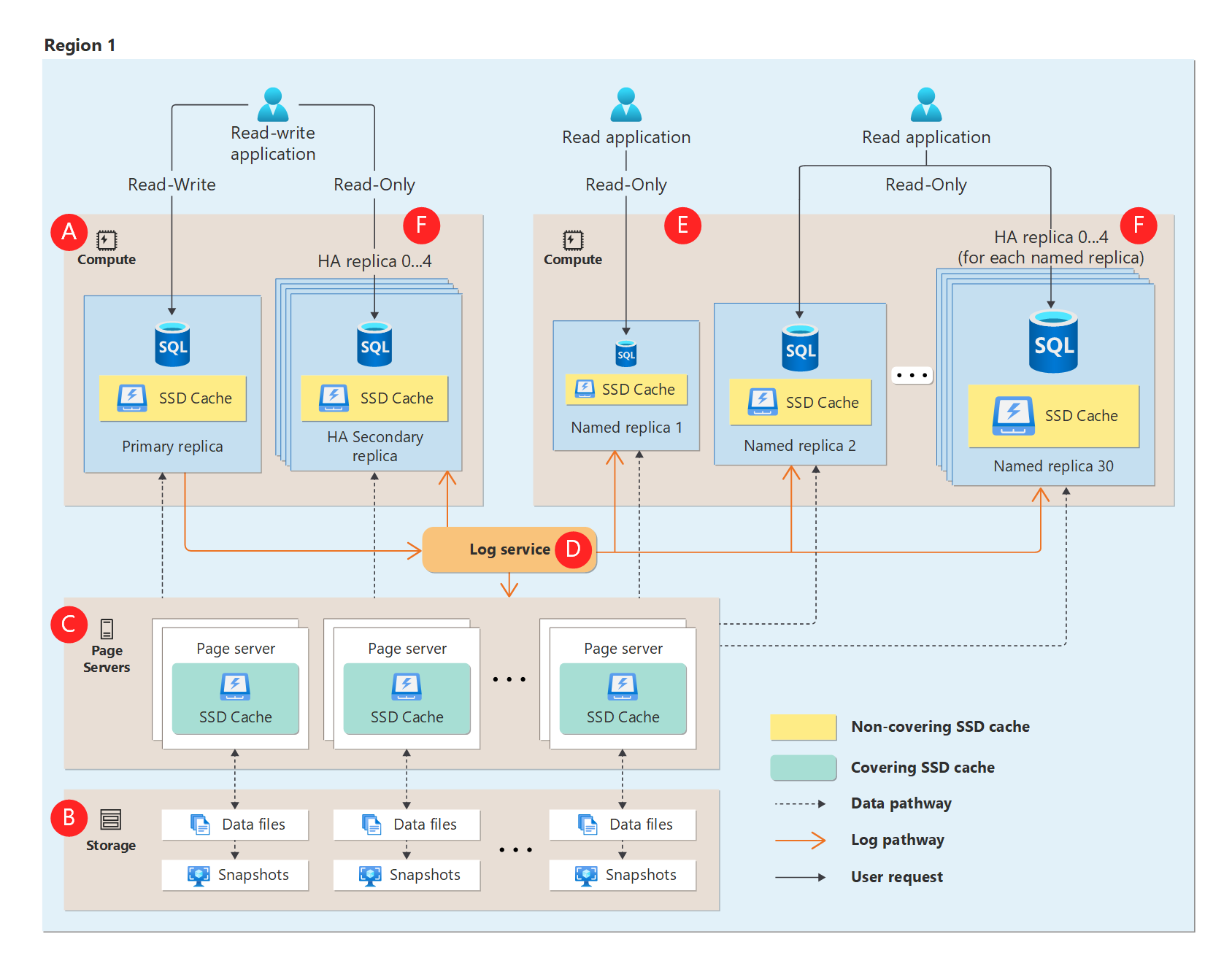
A Hyperscale database contains the following types of components: compute nodes, page servers, the log service, and Azure storage.
Compute
The compute node is where the relational engine lives. The compute node is where language, query, and transaction processing occur. All user interactions with a Hyperscale database happen through compute nodes. Compute nodes can either be configured to use serverless or provisioned compute.
Compute nodes have local SSD-based caches called Resilient Buffer Pool Extension (RBPEX Data Cache). RBPEX Data Cache is an intelligent low-latency data cache that minimizes the need to fetch data from remote page servers.
Hyperscale databases have one primary compute node where the read-write workload and transactions are processed. Up to four high-availability secondary compute nodes can be added on demand. They act as hot standby nodes for failover purposes and can serve as read-only compute nodes to offload read workloads when desired. Named replicas are secondary compute nodes designed to enable various additional OLTP read-scale out scenarios and to better support Hybrid Transactional and Analytical Processing (HTAP) workloads. A geo secondary compute node can be added for disaster recovery purposes and to serve as a read-only compute node to offload read workloads in a different Azure region.
In serverless, the primary replica and any high availability replicas or named replicas each independently autoscale based on their usage. The compute autoscaling range for the primary replica and any named replicas are configured independently. The autoscaling range of any high-availability replicas is inherited from the autoscaling configuration specified by their associated primary replica or named replica.
The database engine running on Hyperscale compute nodes is the same as in other Azure SQL Database service tiers. When users interact with the database engine on Hyperscale compute nodes, the supported surface area and engine behavior are the same as in other service tiers, except for known limitations.
Page server
Page servers are systems representing a scaled-out storage engine. Each page server is responsible for a subset of the pages in the database. Each page server also has a replica that is kept for redundancy and availability.
The job of a page server is to serve database pages out to the compute nodes on demand, and to keep the pages updated as transactions update data. Page servers are kept up to date by replaying transaction log records from the log service.
Page servers also maintain covering SSD-based caches to enhance performance. Long-term storage of data pages is kept in Azure Storage for durability.
Log service
The log service accepts transaction log records that correspond to data changes from the primary compute replica. Page servers then receive the log records from the log service and apply the changes to their respective slices of data. Additionally, compute secondary replicas receive log records from the log service and replay only the changes to pages already in their buffer pool or local RBPEX cache. All data changes from the primary compute replica are propagated through the log service to all the secondary compute replicas and page servers.
Finally, transaction log records are pushed out to long-term storage in Azure Storage, which is a virtually infinite storage repository. This mechanism removes the need for frequent log truncation. The common reasons for log growth such as missed log backups or slow data replication to secondary replicas do not apply to Hyperscale. The log service has local memory and SSD caches to speed up access to log records.
Azure storage
Azure Storage contains all data files in a database. Page servers keep data files in Azure Storage up to date. This storage is also used for backup purposes and can be replicated between regions based on choice of storage redundancy.
Backups are implemented using storage snapshots of data files. Restore operations using snapshots are fast regardless of data size. A database can be restored to any point in time within its backup retention period.
Hyperscale supports configurable storage redundancy. When creating a Hyperscale database, you can choose from the following types of Azure standard storage:
- Locally redundant storage (LRS)
- Zone-redundant storage (ZRS)
- Read-access geo-redundant storage (RA-GRS)
- Read-access geo-zone-redundant storage (RA-GZRS)
Zone-redundant storage options are available in Azure regions with availability zones.
The selected storage redundancy option is used for the lifetime of the database, for both data storage redundancy and backup storage redundancy.
Related content
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for