Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
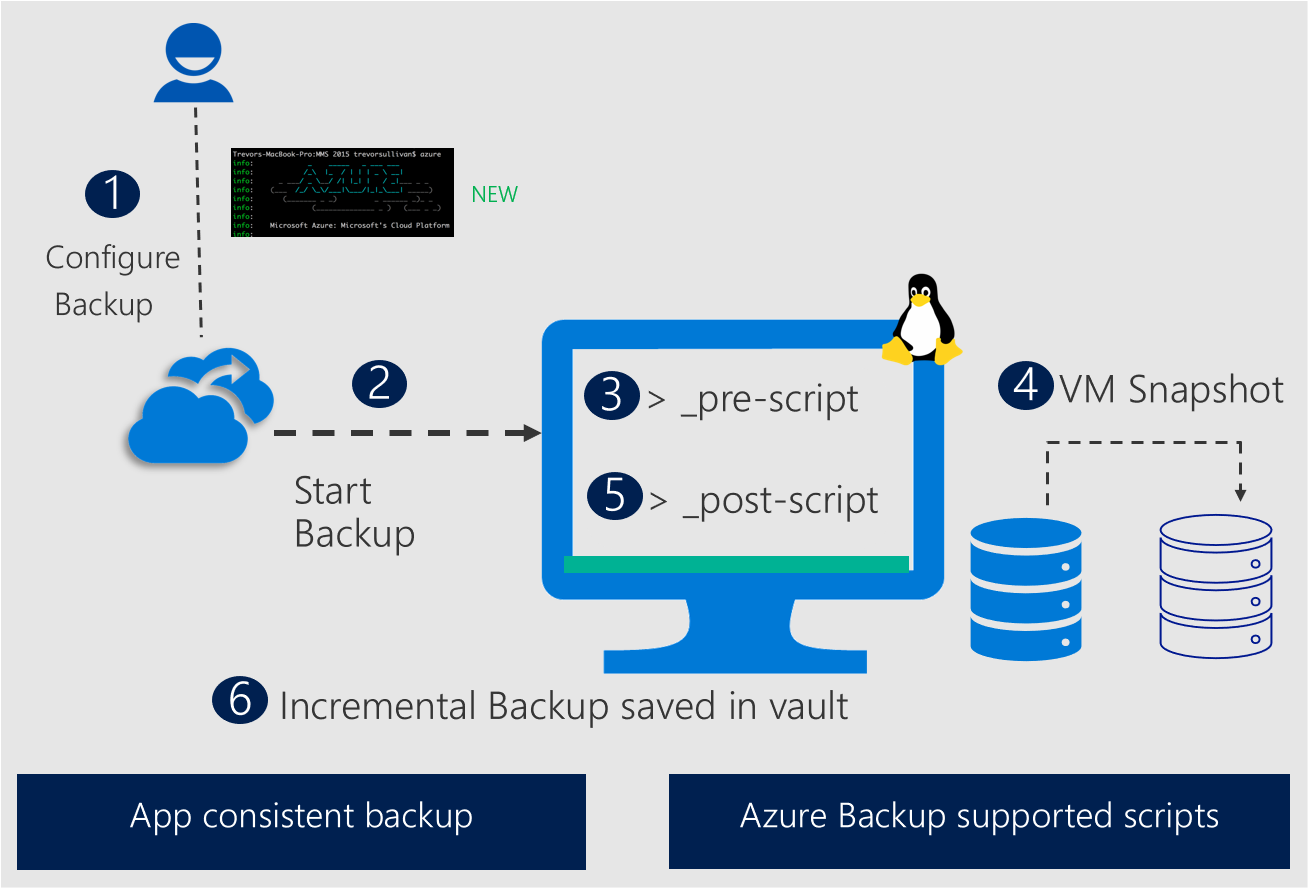
Azure Backup offers a built-in prescript and postscript framework to ensure application consistency for Linux VMs during backup. This framework automatically runs a prescript to quiet applications before disk snapshots and a postscript to restore applications to normal operation after the snapshot.
Managing custom prescripts and postscripts is often complex and time-consuming. To simplify this process, Azure Backup provides ready-to-use prescripts and postscripts for popular databases to enable application-consistent snapshots with minimal effort and maintenance.
The following diagram illustrates how Azure Backup uses enhanced prescripts and postscripts to achieve application-consistent snapshots for Linux databases to ensure reliable backup and recovery.
Key benefits of an enhanced prescript and postscript framework
The new enhanced prescript and postscript framework has the following key benefits:
- These prescripts and postscripts are directly installed in Azure VMs along with the backup extension, which helps to eliminate authoring and download them from an external location.
- The definition and content of prescripts and postscripts are available to view on GitHub. You can submit suggestions and changes via GitHub, which are triaged and added to benefit the broader community.
- New prescripts and postscripts for other databases are available via GitHub, which are triaged and addressed to benefit the broader community.
- The robust framework is efficient to handle scenarios, such as prescript execution failure or crashes. In any event, the postscript automatically runs to roll back all changes done in the prescript.
- The framework also provides a messaging channel for external tools to fetch updates and prepare their own action plan on any message or event.
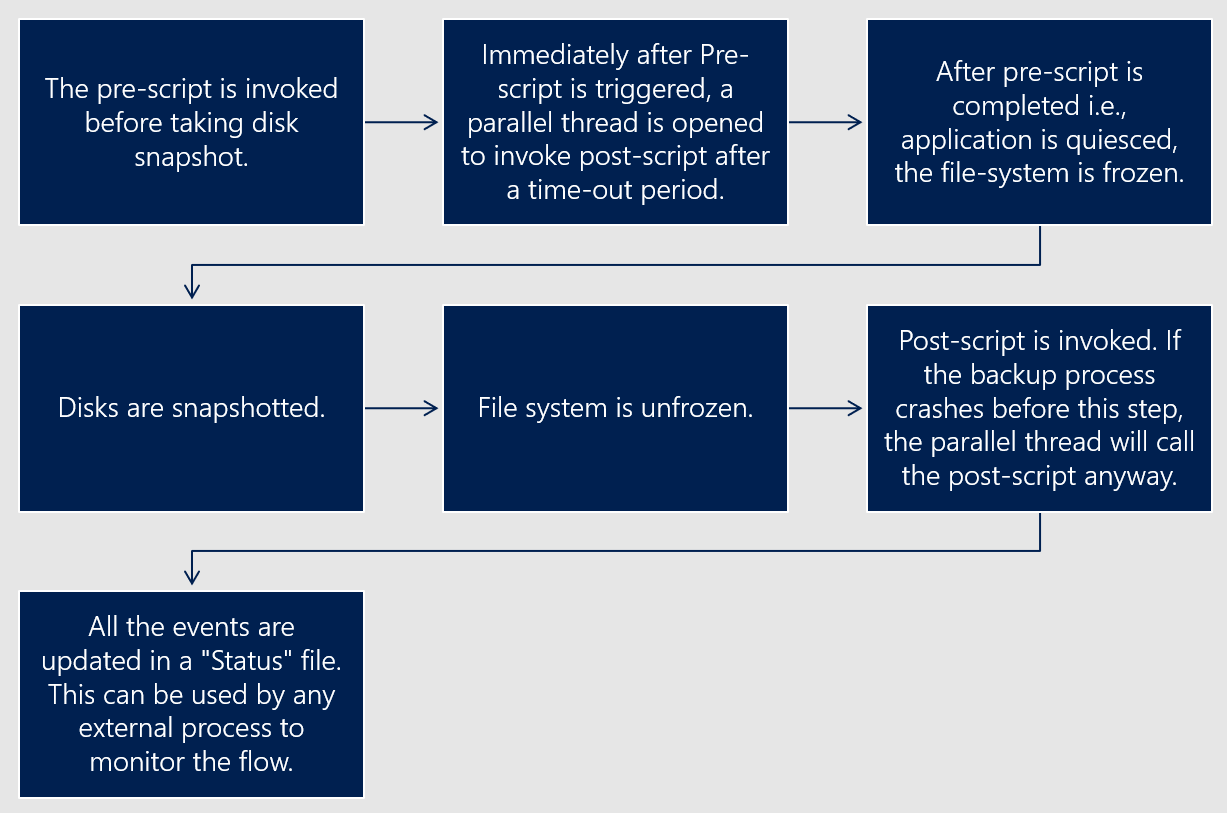
Solution flow of enhanced prescript and postscript framework
The following diagram illustrates the solution flow of the enhanced prescript and postscript framework for database-consistent snapshots.
Support matrix
The following databases are covered under the enhanced framework:
- Oracle (generally available): See Support matrix for Azure VM backups.
- MySQL (preview).
Prerequisites
You need to modify only a configuration file, workload.conf in /etc/azure, to provide connection details. In this way, Azure Backup can connect to the relevant application and run prescripts and postscripts. The configuration file has the following parameters:
[workload]
# valid values are mysql, oracle
workload_name =
command_path =
linux_user =
credString =
ipc_folder =
timeout =
The following table describes the parameters.
| Parameter | Mandatory | Explanation |
|---|---|---|
workload_name |
Yes | Contains the name of the database for which you need application-consistent backup. The current supported values are oracle or mysql. |
command_path/configuration_path |
Contains a path to the workload binary. This field isn't mandatory if the workload binary is set as a path variable. | |
linux_user |
Yes | Contains the username of the Linux user with access to the database user sign-in. If this value isn't set, root is considered as the default user. |
credString |
Stands for credential string to connect to the database. Contains the entire sign-in string. | |
ipc_folder |
Workload can write to only certain file system paths. Provide this folder path so that the prescript can write the states to this folder path. | |
timeout |
Yes | Maximum time limit for which the database is in a quiet state. The default value is 90 seconds. Don't set a value less than 60 seconds. |
Note
The JSON definition is a template that Azure Backup might modify to suit a particular database. To understand the configuration file for each database, refer to each database's manual.
The overall experience to use the enhanced prescript and postscript framework is:
- Prepare the database environment.
- Edit the configuration file.
- Trigger the VM backup.
- Restore VMs or disks or files from the application-consistent recovery point as required.
Build a database backup strategy
Use snapshots instead of streaming
Usually, streaming backups (such as full, differential, or incremental) and logs are used by database admins in their backup strategy. Key points in the design are:
- Performance and cost: A daily full backup plus logs is the fastest during restore but involves significant cost. Including the differential or incremental streaming backup type reduces cost but might affect the restore performance. But snapshots provide the best combination of performance and cost. Because snapshots are inherently incremental, they have the least effect on performance during backup, are restored fast, and also save cost.
- Impact on database or infrastructure: The performance of a streaming backup depends on the underlying storage IOPS and the network bandwidth that's available when the stream is targeted to a remote location. Snapshots don't have this dependency, and the demand on IOPS and network bandwidth is reduced.
- Reusability: The commands for triggering different streaming backup types are different for each database, so scripts can't be easily reused. Also, if you're using different backup types, make sure to evaluate the dependency chain to maintain the life cycle. For snapshots, it's easy to write script because there's no dependency chain.
- Long-term retention: Full backups are always beneficial for long-term retention because you can move and recover them independently. For operational backups with short-term retention, snapshots are favorable.
A daily snapshot plus logs with occasional full backup for long-term retention is the best backup policy for databases.
Log backup strategy
The enhanced prescript and postscript framework is built on Azure VM backup that schedules backup once per day. For this reason, the data loss window with the recovery point objective (RPO) as 24 hours isn't suitable for production databases. This solution is complemented with a log backup strategy where log backups are streamed out explicitly.
Network File System (NFS) on Azure Blob Storage and NFS on AFS (preview) help with easy mounting of volumes directly on database VMs and use database clients to transfer log backups. The data-loss window that's the RPO falls to the frequency of log backups. Also, NFS targets don't need to be highly performant. You might not need to trigger regular streaming (full and incremental) for operational backups after you have database-consistent snapshots.
Note
The enhanced prescript usually takes care to flush all the log transactions in transit to the log backup destination before quieting the database to take a snapshot. As a result, the snapshots are database consistent and reliable during recovery.
Recovery strategy
After the database-consistent snapshots are taken and the log backups are streamed to an NFS volume, the recovery strategy of the database could use the recovery functionality of Azure VM backups. The ability of log backups is also applied to it by using the database client. The following options for recovery strategy are:
- Create new VMs from a database-consistent recovery point. The VM should already have the log mount-point connected. Use database clients to run recovery commands for point-in-time recovery.
- Create disks from a database-consistent recovery point and attach them to another target VM. Then mount the log destination and use database clients to run recovery commands for point-in-time recovery.
- Use a file-recovery option and generate a script. Run the script on the target VM and attach the recovery point as iSCSI disks. Then use database clients to run the database-specific validation functions on the attached disks and validate the backup data. Also, use database clients to export or recover a few tables or files instead of recovering the entire database.
- Use the Cross Region Restore functionality to perform the preceding actions from secondary paired regions during a regional disaster.
Summary
With database-consistent snapshots plus logs backed up by using a custom solution, you can build a database backup solution that's performant and cost-effective. This solution uses the benefits of Azure VM backup and also reuses the capabilities of database clients.