Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Important
This connector can be used in Real-Time Intelligence in Microsoft Fabric. Use the instructions in this article with the following exceptions:
- If required, create databases using the instructions in Create a KQL database.
- If required, create tables using the instructions in Create an empty table.
- Get query or ingestion URIs using the instructions in Copy URI.
- Run queries in a KQL queryset.
Azure Data Explorer supports data ingestion from Azure Stream Analytics. Azure Stream Analytics is a real-time analytics and complex event-processing engine that's designed to process high volumes of fast streaming data from multiple sources simultaneously.
An Azure Stream Analytics job consists of an input source, a transformation query, and an output connection. You can create, edit, and test Stream Analytics jobs using the Azure portal, Azure Resource Manager (ARM) templates, Azure PowerShell, .NET API, REST API, Visual Studio, and the Stream Analytics no code editor.
In this article, you'll learn how to use a Stream Analytics job to collect data from an event hub and send it to your Azure Data Explorer cluster using the Azure portal or an ARM template.
Prerequisites
Create a cluster and database and a table.
Create an event hub using the following sections of the Azure Stream Analytics tutorial:
Tip
For testing, we recommend that you download the phone call event generator app from the Microsoft Download Center or get the source code from GitHub. When setting up the Azure Stream Analytics job, you'll configure it to pull data from the event hub and pass it to the Azure Data Explorer output connector.
Create an Azure Data Explorer output connection
Use the following steps to create an Azure Data Explorer output for a Stream Analytics job using the Azure portal or using an ARM template. The connection is used by the Stream Analytics job to send data to a specified Azure Data Explorer table. Once created and job is running, data that flows into the job is ingested into the specified target table.
Important
- The Azure Data Explorer output connector only supports Managed Identity authentication. As part of creating the connector, database monitor and database ingestor permissions are granted to the Azure Stream Analytics job managed identity.
- When setting up the Azure Data Explorer output connector, you specify the target cluster, database, and table name. For ingestion to succeed, all of the columns defined in the Azure Stream Analytics query must match the column names and types in the Azure Data Explorer table. Column names are case-sensitive and can be in any order. If there are columns in the Azure Stream Analytics query that don't map to columns in the Azure Data Explorer table, an error is raised.
Note
- All Azure Stream Analytics inputs are supported. The connector transforms the inputs to CSV format and then imports the data into the specified Azure Data Explorer table.
- Azure Data Explorer has an aggregation (batching) policy for data ingestion, designed to optimize the ingestion process. By default, the policy is configured to 5 minutes, 1000 items or 1 GB of data by default, so you may experience a latency. For information about configuring the aggregation options, see batching policy.
Before you begin, make sure you have an existing Stream Analytics job or create a new one, and then use the following steps to create your Azure Data Explorer connection.
Sign in to the Azure portal.
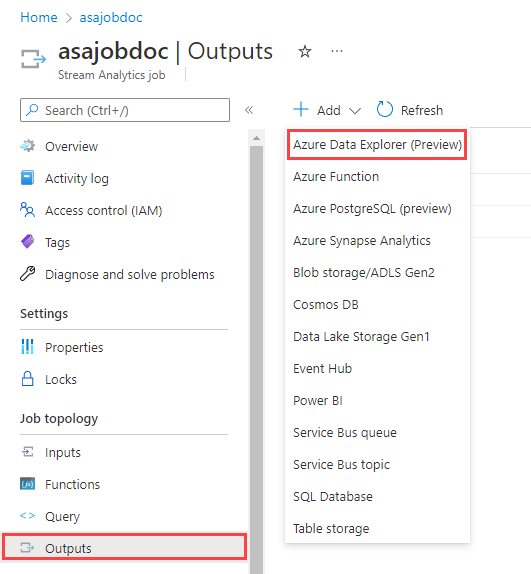
From the Azure portal, open All resources, and select your Stream Analytics job.
Under Job topology, select the Outputs.
Select Add > Azure Data Explorer.
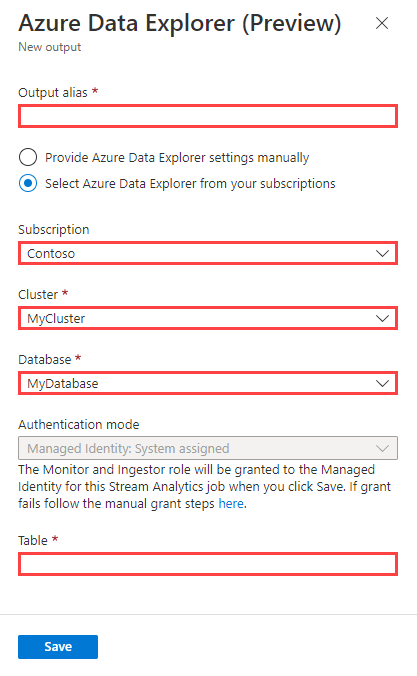
Fill the output form using the following information and then select Save.
Note
You can use the following options to specify your cluster and database:
- Subscription: Select Select Azure Data Explorer from your subscriptions, select your subscription, and then choose your cluster and database.
- Manually: Select Provide Azure Data Explorer settings manually, specify the cluster URI and database.
Property name Description Output alias A friendly name used in queries to direct the query output to this database. Subscription Select the Azure subscription where your cluster resides. Cluster The unique name that identifies your cluster. The domain name [region].kusto.windows.net is appended to the cluster name you provide. The name can contain only lowercase letters and numbers. It must contain from 4 to 22 characters. Cluster URI The data ingestion URI of your Azure Data Explorer cluster. Database The name of the database where you're sending your output. The database name must be unique within the cluster. Authentication A Microsoft Entra managed identity that allows your cluster to easily access other Microsoft Entra protected resources. The identity is managed by the Azure platform and doesn't require you to provision or rotate any secrets. Managed identity configuration enables you to use customer-managed keys for your cluster. Table The name of the table where you're sending your output. The column names and data types in the Azure Stream Analytics output must match the schema of the Azure Data Explorer table.