Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
APPLIES TO:  Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Data wrangling involves transforming and reformatting data from its original source to make it more suitable and useful for various downstream applications.
Organizations need to have the ability to explore their critical business data for data preparation and wrangling in order to provide accurate analysis of complex data that continues to grow every day. Data preparation is required so that organizations can use the data in various business processes and reduce the time to value.
Data Factory empowers you with code-free data preparation at cloud scale iteratively using Power Query. Data Factory integrates with Power Query Online and makes Power Query M functions available as a pipeline activity.
Data Factory translates M generated by the Power Query Online Mashup Editor into spark code for cloud scale execution by translating M into Azure Data Factory Data Flows. Wrangling data with Power Query and data flows are especially useful for data engineers or 'citizen data integrators'.
Use cases
Fast interactive data exploration and preparation
Multiple data engineers and citizen data integrators can interactively explore and prepare datasets at cloud scale. With the rise of volume, variety and velocity of data in data lakes, users need an effective way to explore and prepare data sets. For example, you may need to create a dataset that 'has all customer demographic info for new customers since 2017'. You aren't mapping to a known target. You're exploring, wrangling, and prepping datasets to meet a requirement before publishing it in the lake. Wrangling is often used for less formal analytics scenarios. The prepped datasets can be used for doing transformations and machine learning operations downstream.
Code-free agile data preparation
Citizen data integrators spend more than 60% of their time looking for and preparing data. They're looking to do it in a code free manner to improve operational productivity. Allowing citizen data integrators to enrich, shape, and publish data using known tools like Power Query Online in a scalable manner drastically improves their productivity. Wrangling in Azure Data Factory enables the familiar Power Query Online mashup editor to allow citizen data integrators to fix errors quickly, standardize data, and produce high-quality data to support business decisions.
Data validation and exploration
Visually scan your data in a code-free manner to remove any outliers, anomalies, and conform it to a shape for fast analytics.
Supported sources
| Connector | Data format | Authentication type |
|---|---|---|
| Azure Blob Storage | CSV, Parquet, Excel | Account Key, Service Principal, MSI |
| Azure Data Lake Storage Gen1 | CSV, Parquet, Excel | Service Principal, MSI |
| Azure Data Lake Storage Gen2 | CSV, Parquet, Excel | Account Key, Service Principal, MSI |
| Azure SQL Database | - | SQL authentication, MSI, Service Principal |
| Azure Synapse Analytics | - | SQL authentication, MSI, Service Principal |
The mashup editor
When you create a Power Query activity, all source datasets become dataset queries and are placed in the ADFResource folder. By default, the UserQuery will point to the first dataset query. All transformations should be done on the UserQuery as changes to dataset queries are not supported nor will they be persisted. Renaming, adding and deleting queries is currently not supported.
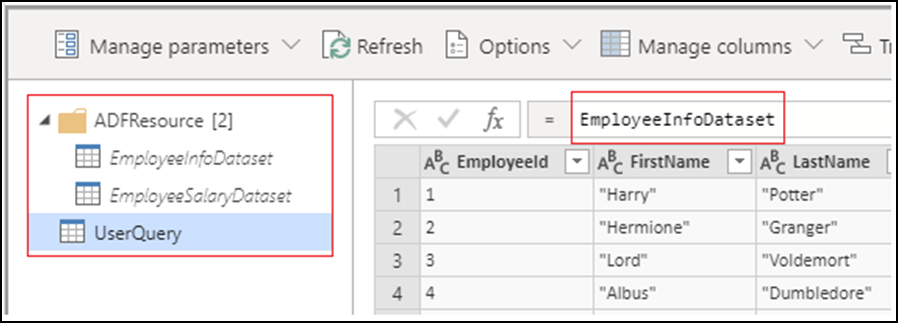
Currently not all Power Query M functions are supported for data wrangling despite being available during authoring. While building your Power Query activities, you'll be prompted with the following error message if a function isn't supported:
The Power Query Spark Runtime does not support the function
For more information on supported transformations, see Power Query data wrangling functions.
Related content
Learn how to create a data wrangling Power Query mash-up.