Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Workspace admins and sufficiently privileged users can configure and manage SQL warehouses. This article outlines how to create, edit, and monitor existing SQL warehouses.
You can also create SQL warehouses using the SQL warehouse API, or Terraform.
Databricks recommends using serverless SQL warehouses when available.
Note
Most users cannot create SQL warehouses, but can restart any SQL warehouse they can connect to. See Connect to a SQL warehouse.
Requirements
SQL warehouses have the following requirements:
- To create a SQL warehouse you must be a workspace admin or a user with unrestricted cluster creation permissions.
- Before you can create a serverless SQL warehouse in a region that supports the feature, there might be required steps. See Set up serverless SQL warehouses.
- For classic or pro SQL warehouses, your Azure account must have adequate vCPU quota. The default vCPU quota is usually adequate to create a serverless SQL warehouse but might not be enough to scale the SQL warehouse or to create additional warehouses. See Required Azure vCPU quota for classic and pro SQL warehouses. You can request additional vCPU quota. Your Azure account may have limitations on how much vCPU quota you can request. Contact your Azure account team for more information.
Create a SQL warehouse
To create a SQL warehouse using the web UI:
- Click SQL Warehouses in the sidebar.
- Click Create SQL warehouse.
- Enter a Name for the warehouse.
- (Optional) Configure warehouse settings. See Configure SQL warehouse settings.
- (Optional) Configure advanced options. See Advanced options.
- Click Create.
- (Optional) Configure access to the SQL warehouse. See Manage a SQL warehouse.
Your created warehouse starts automatically.
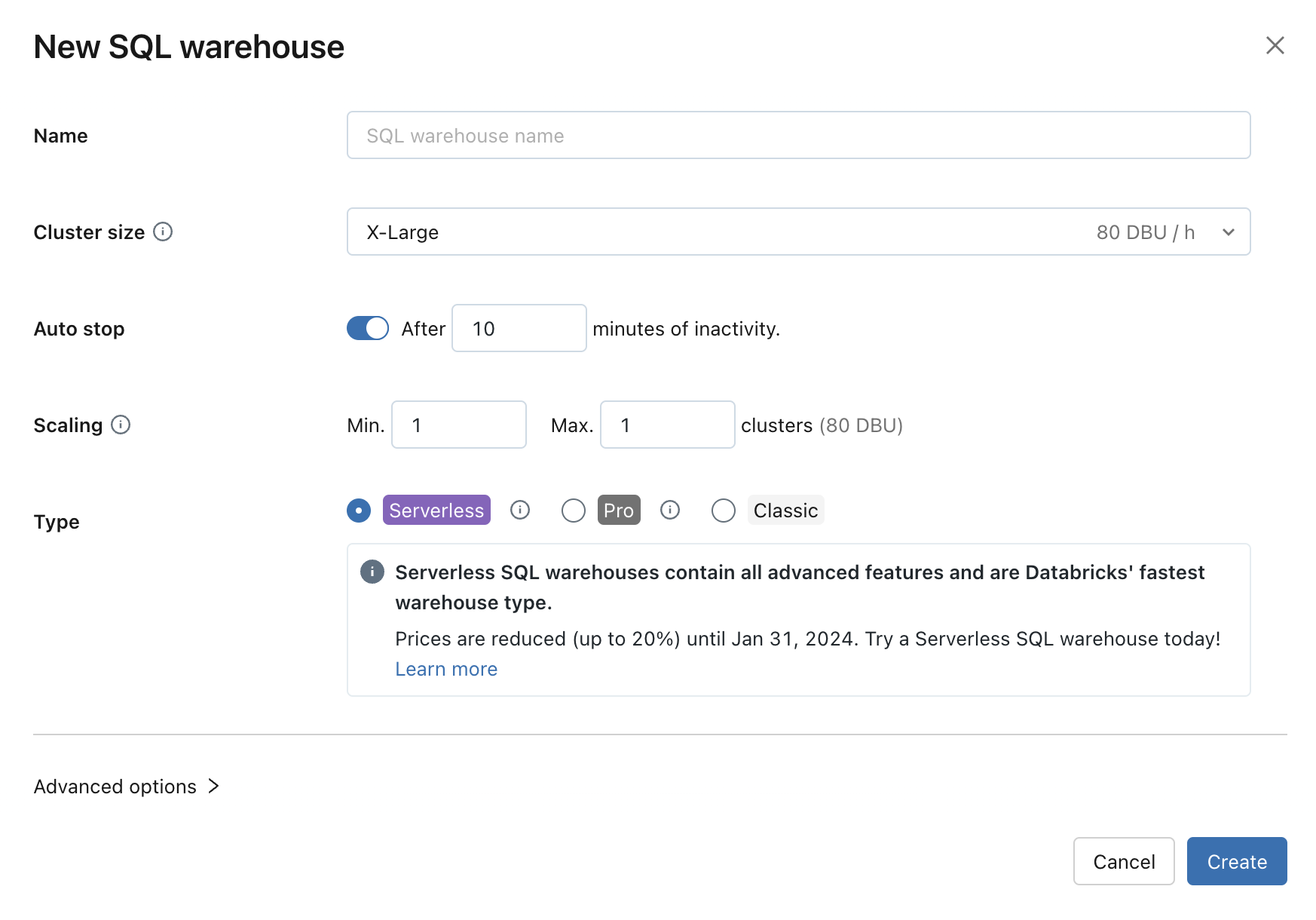
Configure SQL warehouse settings
You can modify the following settings while creating or editing a SQL warehouse:
Cluster Size represents the size of the driver node and number of worker nodes associated with the cluster. The default is X-Large. To reduce query latency, increase the size.
Auto Stop determines whether the warehouse stops if it's idle for the specified number of minutes. Idle SQL warehouses continue to accumulate DBU and cloud instance charges until they are stopped.
- Pro and classic SQL warehouses: The default is 45 minutes, which is recommended for typical use. The minimum is 10 minutes.
- Serverless SQL warehouses: The default is 10 minutes, which is recommended for typical use. The minimum is 5 minutes when you use the UI. Note that you can create a serverless SQL warehouse using the SQL warehouses API, in which case you can set the Auto Stop value as low as 1 minute.
Scaling sets the minimum and maximum number of clusters that will be used for a query. The default is a minimum and a maximum of one cluster. You can increase the maximum clusters if you want to handle more concurrent users for a given query. Azure Databricks recommends a cluster for every 10 concurrent queries.
To maintain optimal performance, Azure Databricks periodically recycles clusters that have been running for more than 24 hours. During recycling, Azure Databricks brings up a new cluster and begins transitioning new queries to it while decommissioning the old cluster. Existing queries continue to run on the old cluster until they are completed.
During this transition period, you may temporarily see a cluster count that exceeds the configured maximum. For example, if your maximum cluster count is set to 1, you might see 2 active clusters during recycling. Azure Databricks waits for all queries on the old cluster to finish before terminating it. If the old cluster cannot be terminated within 4 hours due to long-running queries, Azure Databricks forcefully terminates the cluster to complete the recycling process.
Type determines the type of warehouse. If serverless is enabled in your account, serverless is the default. See SQL warehouse types for the list.
Advanced options
Configure the following advanced options by expanding the Advanced options area when you create a new SQL warehouse or edit an existing SQL warehouse. You can also configure these options using the SQL Warehouse API.
Tags: Tags allow you to monitor the cost of cloud resources used by users and groups in your organization. You specify tags as key-value pairs.
Unity Catalog: If Unity Catalog is enabled for the workspace, it is the default for all new warehouses in the workspace. If Unity Catalog is not enabled for your workspace, you do not see this option. See What is Unity Catalog?.
Channel: Use the Preview channel to test new functionality, including your queries and dashboards, before it becomes the Databricks SQL standard.
The release notes list what's in the latest preview version.
Important
Databricks recommends against using a preview version for production workloads. Because only workspace admins can view a warehouse's properties, including its channel, consider indicating that a Databricks SQL warehouse uses a preview version in that warehouse's name to prevent users from using it for production workloads.
Set a user-level default warehouse
You can set a default SQL warehouse to automatically use when running queries. This setting overrides the workspace-level default warehouse, if one exists. See Set a default SQL warehouse for the workspace.
Use the drop-down menu to set a new default from any Databricks SQL authoring surface, including the SQL editor, AI/BI dashboards, Genie, Alerts, and Catalog Explorer.
To set a user-level default warehouse:
Click the drop-down menu to select SQL warehouse compute.
Click Customize your default warehouse.

Choose one of the following:
- Workspace default: Keep this setting to use the default warehouse set for the workspace.
- Last selected: Default selection shows the last warehouse that you selected as compute.
- Custom default: Choose a new SQL warehouse as your default warehouse. This overrides a workspace-level default setting. After setting, the selected warehouse is automatically selected as compute. You can manually override this setting by choosing a different SQL warehouse in the drop-down menu.
Manage a SQL warehouse
Workspace admins and users with CAN MANAGE privileges on a SQL warehouse can complete the following tasks on an existing SQL warehouse:
To stop a running warehouse, click the stop icon next to the warehouse.
To start a stopped warehouse, click the start icon next to the warehouse.
To edit a warehouse, click the kebab menu
 then click Edit.
then click Edit.To add and edit permissions, click the kebab menu
then click Permissions.- Assign Can view to allow users to view SQL warehouses, including query history and query profiles. These users cannot run queries on the warehouse.
- Assign Can use to users who need to run queries on the warehouse.
- Assign Can monitor to power users for troubleshooting and optimizing query performance. Can monitor permission allows users to run queries and monitor SQL warehouses, including query history and query profiles.
- Assign Can manage to users responsible for SQL warehouse sizing and spend limits decisions.
- Is owner automatically applies to the SQL warehouse's creator.
To learn about permission levels, see SQL warehouse ACLs.
To upgrade a SQL warehouse to serverless, click the kebab menu
, then click Upgrade to Serverless.To delete a warehouse, click the kebab menu
, then click Delete.
Note
Contact your Databricks representative to restore deleted warehouses within 14 days.