Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This page describes the standard connectors in Databricks Lakeflow Connect, which offer higher levels of ingestion pipeline customization compared to the managed connectors.
Layers of the ETL stack
Some connectors operate at one level of the ETL stack. For example, Databricks offers fully-managed connectors for enterprise applications like Salesforce and databases like SQL Server. Other connectors operate at multiple layers of the ETL stack. For example, you can use standard connectors in either Structured Streaming for full customization or Lakeflow Spark Declarative Pipelines for a more managed experience.
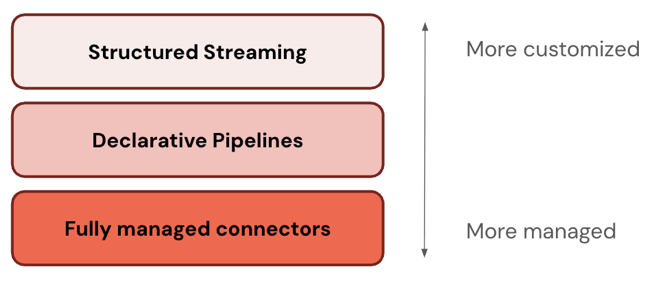
Databricks recommends starting with the most managed layer. If it doesn't satisfy your requirements (for example, if it doesn't support your data source), drop down to the next layer.
The following table describes the three layers of ingestion products, ordered from most customizable to most managed:
| Layer | Description |
|---|---|
| Structured Streaming | Apache Spark Structured Streaming is a streaming engine that offers end-to-end fault tolerance with exactly-once processing guarantees using Spark APIs. |
| Lakeflow Spark Declarative Pipelines | Lakeflow Spark Declarative Pipelines builds on Structured Streaming, offering a declarative framework for creating data pipelines. You can define the transformations to perform on your data, and Lakeflow Spark Declarative Pipelines manages orchestration, monitoring, data quality, errors, and more. Therefore, it offers more automation and less overhead than Structured Streaming. |
| Managed connectors | Fully-managed connectors build on Lakeflow Spark Declarative Pipelines, offering even more automation for the most popular data sources. They extend Lakeflow Spark Declarative Pipelines functionality to also include source-specific authentication, CDC, edge case handling, long-term API maintenance, automated retries, automated schema evolution, and so on. Therefore, they offer even more automation for any supported data sources. |
Choose a connector
The following table lists standard ingestion connectors by data source and level of pipeline customization. For a fully automated ingestion experience, use managed connectors instead.
SQL examples for incremental ingestion from cloud object storage use CREATE STREAMING TABLE syntax. It offers SQL users a scalable and robust ingestion experience, therefore it's the recommended alternative to COPY INTO.
| Source | More customization | Some customization | More automation |
|---|---|---|---|
| Cloud object storage | Auto Loader with Structured Streaming (Python, Scala) |
Auto Loader with Lakeflow Spark Declarative Pipelines (Python, SQL) |
Auto Loader with Databricks SQL (SQL) |
| SFTP servers | Ingest files from SFTP servers (Python, SQL) |
N/A | N/A |
| Apache Kafka | Structured Streaming with Kafka source (Python, Scala) |
Lakeflow Spark Declarative Pipelines with Kafka source (Python, SQL) |
Databricks SQL with Kafka source (SQL) |
| Google Pub/Sub | Structured Streaming with Pub/Sub source (Python, Scala) |
Lakeflow Spark Declarative Pipelines with Pub/Sub source (Python, SQL) |
Databricks SQL with Pub/Sub source (SQL) |
| Apache Pulsar | Structured Streaming with Pulsar source (Python, Scala) |
Lakeflow Spark Declarative Pipelines with Pulsar source (Python, SQL) |
Databricks SQL with Pulsar source (SQL) |
Ingestion schedules
You can configure ingestion pipelines to run on a recurring schedule or continuously.
| Use case | Pipeline mode |
|---|---|
| Batch ingestion | Triggered: Processes new data on a schedule or when manually triggered. |
| Streaming ingestion | Continuous: Processes new data as it arrives in the source. |