Using Apache Kafka® on HDInsight with Apache Flink® on HDInsight on AKS
Note
We will retire Azure HDInsight on AKS on January 31, 2025. Before January 31, 2025, you will need to migrate your workloads to Microsoft Fabric or an equivalent Azure product to avoid abrupt termination of your workloads. The remaining clusters on your subscription will be stopped and removed from the host.
Only basic support will be available until the retirement date.
Important
This feature is currently in preview. The Supplemental Terms of Use for Microsoft Azure Previews include more legal terms that apply to Azure features that are in beta, in preview, or otherwise not yet released into general availability. For information about this specific preview, see Azure HDInsight on AKS preview information. For questions or feature suggestions, please submit a request on AskHDInsight with the details and follow us for more updates on Azure HDInsight Community.
A well known use case for Apache Flink is stream analytics. The popular choice by many users to use the data streams, which are ingested using Apache Kafka. Typical installations of Flink and Kafka start with event streams being pushed to Kafka, which can be consumed by Flink jobs.
This example uses HDInsight on AKS clusters running Flink 1.17.0 to process streaming data consuming and producing Kafka topic.
Note
FlinkKafkaConsumer is deprecated and will be removed with Flink 1.17, please use KafkaSource instead. FlinkKafkaProducer is deprecated and will be removed with Flink 1.15, please use KafkaSink instead.
Prerequisites
Both Kafka and Flink need to be in the same VNet or there should be vnet-peering between the two clusters.
Create a Kafka cluster in the same VNet. You can choose Kafka 3.2 or 2.4 on HDInsight based on your current usage.
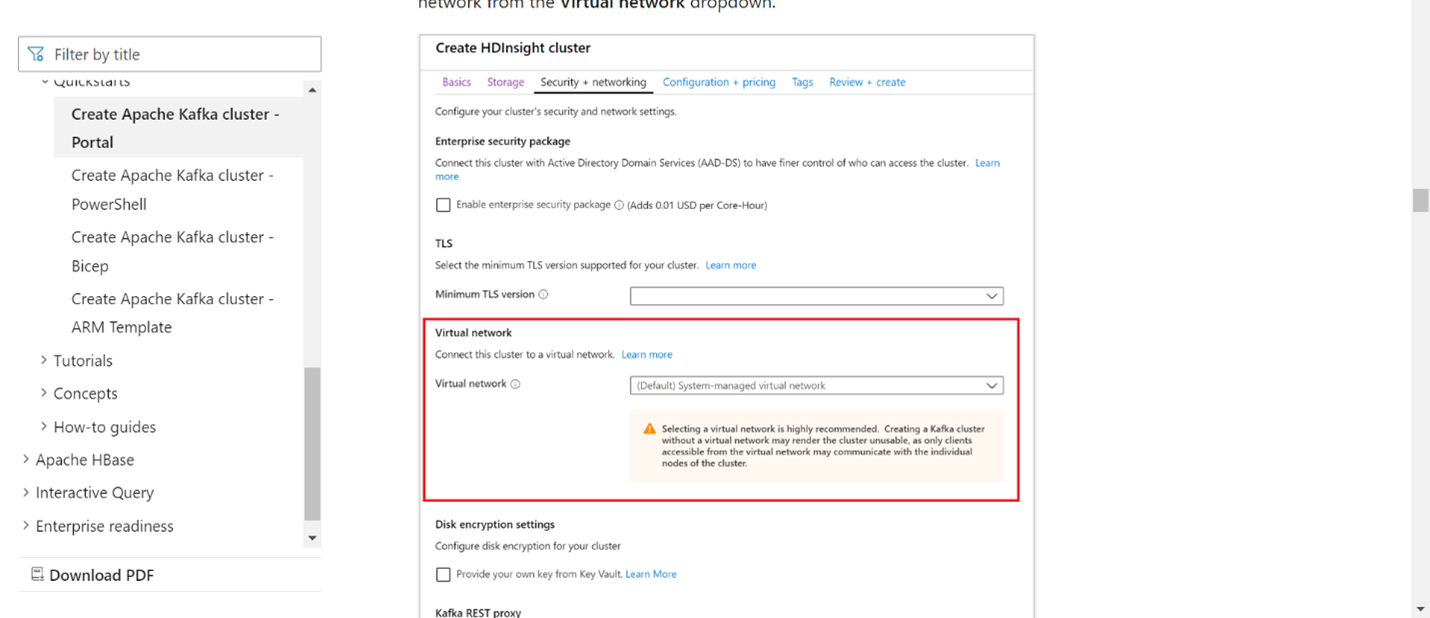
Add the VNet details in the virtual network section.
Create a HDInsight on AKS Cluster pool with same VNet.
Create a Flink cluster to the cluster pool created.

Apache Kafka Connector
Flink provides an Apache Kafka Connector for reading data from and writing data to Kafka topics with exactly once guarantees.
Maven dependency
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>1.17.0</version>
</dependency>
Building Kafka Sink
Kafka sink provides a builder class to construct an instance of a KafkaSink. We use the same to construct our Sink and use it along with Flink cluster running on HDInsight on AKS
SinKafkaToKafka.java
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.connector.base.DeliveryGuarantee;
import org.apache.flink.connector.kafka.sink.KafkaRecordSerializationSchema;
import org.apache.flink.connector.kafka.sink.KafkaSink;
import org.apache.flink.connector.kafka.source.KafkaSource;
import org.apache.flink.connector.kafka.source.enumerator.initializer.OffsetsInitializer;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SinKafkaToKafka {
public static void main(String[] args) throws Exception {
// 1. get stream execution environment
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. read kafka message as stream input, update your broker IPs below
String brokers = "X.X.X.X:9092,X.X.X.X:9092,X.X.X.X:9092";
KafkaSource<String> source = KafkaSource.<String>builder()
.setBootstrapServers(brokers)
.setTopics("clicks")
.setGroupId("my-group")
.setStartingOffsets(OffsetsInitializer.earliest())
.setValueOnlyDeserializer(new SimpleStringSchema())
.build();
DataStream<String> stream = env.fromSource(source, WatermarkStrategy.noWatermarks(), "Kafka Source");
// 3. transformation:
// https://www.taobao.com,1000 --->
// Event{user: "Tim",url: "https://www.taobao.com",timestamp: 1970-01-01 00:00:01.0}
SingleOutputStreamOperator<String> result = stream.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
String[] fields = value.split(",");
return new Event(fields[0].trim(), fields[1].trim(), Long.valueOf(fields[2].trim())).toString();
}
});
// 4. sink click into another kafka events topic
KafkaSink<String> sink = KafkaSink.<String>builder()
.setBootstrapServers(brokers)
.setProperty("transaction.timeout.ms","900000")
.setRecordSerializer(KafkaRecordSerializationSchema.builder()
.setTopic("events")
.setValueSerializationSchema(new SimpleStringSchema())
.build())
.setDeliveryGuarantee(DeliveryGuarantee.EXACTLY_ONCE)
.build();
result.sinkTo(sink);
// 5. execute the stream
env.execute("kafka Sink to other topic");
}
}
Writing a Java program Event.java
import java.sql.Timestamp;
public class Event {
public String user;
public String url;
public Long timestamp;
public Event() {
}
public Event(String user,String url,Long timestamp) {
this.user = user;
this.url = url;
this.timestamp = timestamp;
}
@Override
public String toString(){
return "Event{" +
"user: \"" + user + "\"" +
",url: \"" + url + "\"" +
",timestamp: " + new Timestamp(timestamp) +
"}";
}
}
Package the jar and submit the job to Flink
On Webssh, upload the jar and submit the jar

On Flink Dashboard UI

Produce the topic - clicks on Kafka

Consume the topic - events on Kafka

Reference
- Apache Kafka Connector
- Apache, Apache Kafka, Kafka, Apache Flink, Flink, and associated open source project names are trademarks of the Apache Software Foundation (ASF).