Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Before deploying an HDInsight cluster, plan for the intended cluster capacity by determining the needed performance and scale. This planning helps optimize both usability and costs. Some cluster capacity decisions can't be changed after deployment. If the performance parameters change, a cluster can be dismantled and re-created without losing stored data.
The key questions to ask for capacity planning are:
- In which geographic region should you deploy your cluster?
- How much storage do you need?
- What cluster type should you deploy?
- What size and type of virtual machine (VM) should your cluster nodes use?
- How many worker nodes should your cluster have?
Choose an Azure region
The Azure region determines where your cluster is physically provisioned. To minimize the latency of reads and writes, the cluster should be near your data.
HDInsight is available in many Azure regions. To find the closest region, see Products available by region.
Choose storage location and size
Location of default storage
The default storage, either an Azure Storage account or Azure Data Lake Storage, must be in the same location as your cluster. Azure Storage is available at all locations. Data Lake Storage is available in some regions - see the current Data Lake Storage availability.
Location of existing data
If you want to use an existing storage account or Data Lake Storage as your cluster's default storage, then you must deploy your cluster at that same location.
Storage size
On a deployed cluster, you can attach another Azure Storage accounts or access other Data Lake Storage. All your storage accounts must live in the same location as your cluster. A Data Lake Storage can be in a different location, though great distances may introduce some latency.
Azure Storage has some capacity limits, while Data Lake Storage is almost unlimited. A cluster can access a combination of different storage accounts. Typical examples include:
- When the amount of data is likely to exceed the storage capacity of a single blob storage container.
- When the rate of access to the blob container might exceed the threshold where throttling occurs.
- When you want to make data, you've already uploaded to a blob container available to the cluster.
- When you want to isolate different parts of the storage for reasons of security, or to simplify administration.
For better performance, use only one container per storage account.
Choose a cluster type
The cluster type determines the workload your HDInsight cluster is configured to run. Types include Apache Hadoop, Apache Kafka, or Apache Spark. For a detailed description of the available cluster types, see Introduction to Azure HDInsight. Each cluster type has a specific deployment topology that includes requirements for the size and number of nodes.
Choose the VM size and type
Each cluster type has a set of node types, and each node type has specific options for their VM size and type.
To determine the optimal cluster size for your application, you can benchmark cluster capacity and increase the size as indicated. For example, you can use a simulated workload, or a canary query. Run your simulated workloads on different size clusters. Gradually increase the size until the intended performance is reached. A canary query can be inserted periodically among the other production queries to show whether the cluster has enough resources.
For more information on how to choose the right VM family for your workload, see Selecting the right VM size for your cluster.
Choose the cluster scale
A cluster's scale is determined by the quantity of its VM nodes. For all cluster types, there are node types that have a specific scale, and node types that support scale-out. For example, a cluster may require exactly three Apache ZooKeeper nodes or two Head nodes. Worker nodes that do data processing in a distributed fashion benefit from another worker nodes.
Depending on your cluster type, increasing the number of worker nodes adds more computational capacity (such as more cores). More nodes will increase the total memory required for the entire cluster to support in-memory storage of data being processed. As with the choice of VM size and type, selecting the right cluster scale is typically reached empirically. Use simulated workloads or canary queries.
You can scale out your cluster to meet peak load demands. Then scale it back down when those extra nodes are no longer needed. The Autoscale feature allows you to automatically scale your cluster based upon predetermined metrics and timings. For more information on scaling your clusters manually, see Scale HDInsight clusters.
Cluster lifecycle
You're charged for a cluster's lifetime. If there are only specific times that you need your cluster, create on-demand clusters using Azure Data Factory. You can also create PowerShell scripts that provision and delete your cluster, and then schedule those scripts using Azure Automation.
Note
When a cluster is deleted, its default Hive metastore is also deleted. To persist the metastore for the next cluster re-creation, use an external metadata store such as Azure Database or Apache Oozie.
Isolate cluster job errors
Sometimes errors can occur because of the parallel execution of multiple maps and reduce components on a multi-node cluster. To help isolate the issue, try distributed testing. Run concurrent multiple jobs on a single worker node cluster. Then expand this approach to run multiple jobs concurrently on clusters containing more than one node. To create a single-node HDInsight cluster in Azure, use the Custom(size, settings, apps) option and use a value of 1 for Number of Worker nodes in the Cluster size section when provisioning a new cluster in the portal.
View quota management for HDInsight
View a granular level and categorization of the quota at a VM family level. View the current quota and how much quota is remaining for a region at a VM family level.
Note
This feature is currently available on HDInsight 4.x and 5.x for East US EUAP region. Other regions to follow subsequently.
View current quota:
See the current quota and how much quota is remaining for a region at a VM family level.
From Azure portal, in the top search bar, search and select Quotas.
From the Quota page, select Azure HDInsight
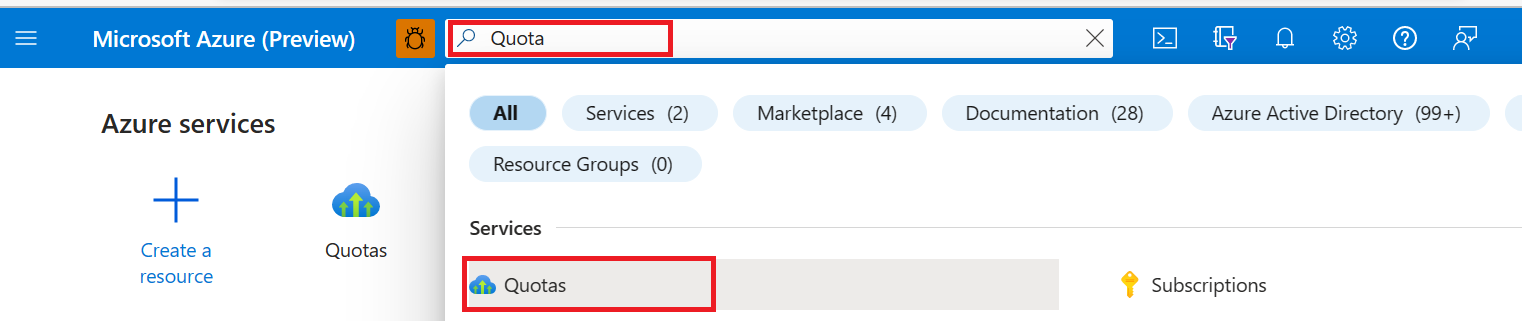
From the dropdown box, select your Subscription and Region
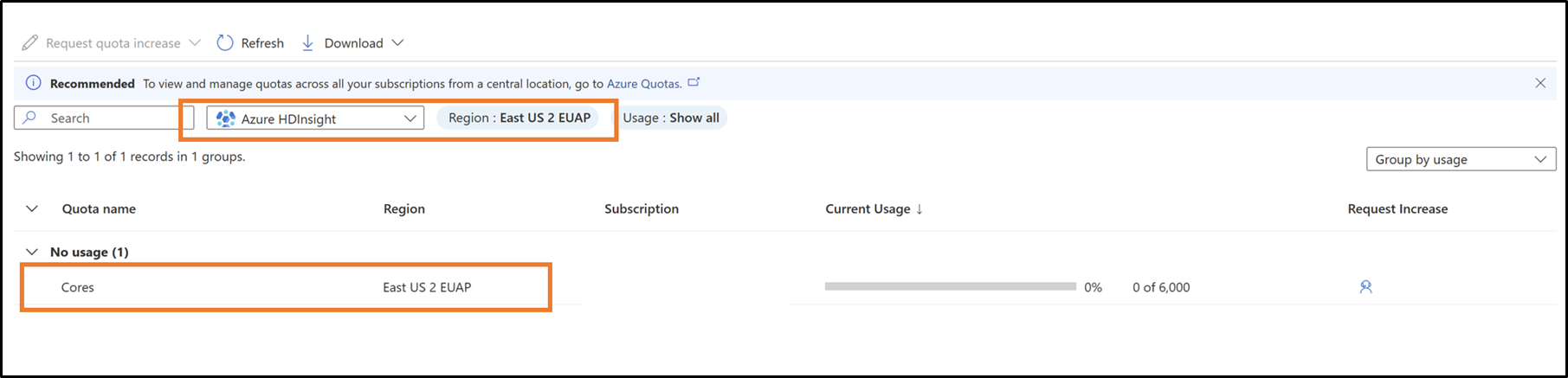
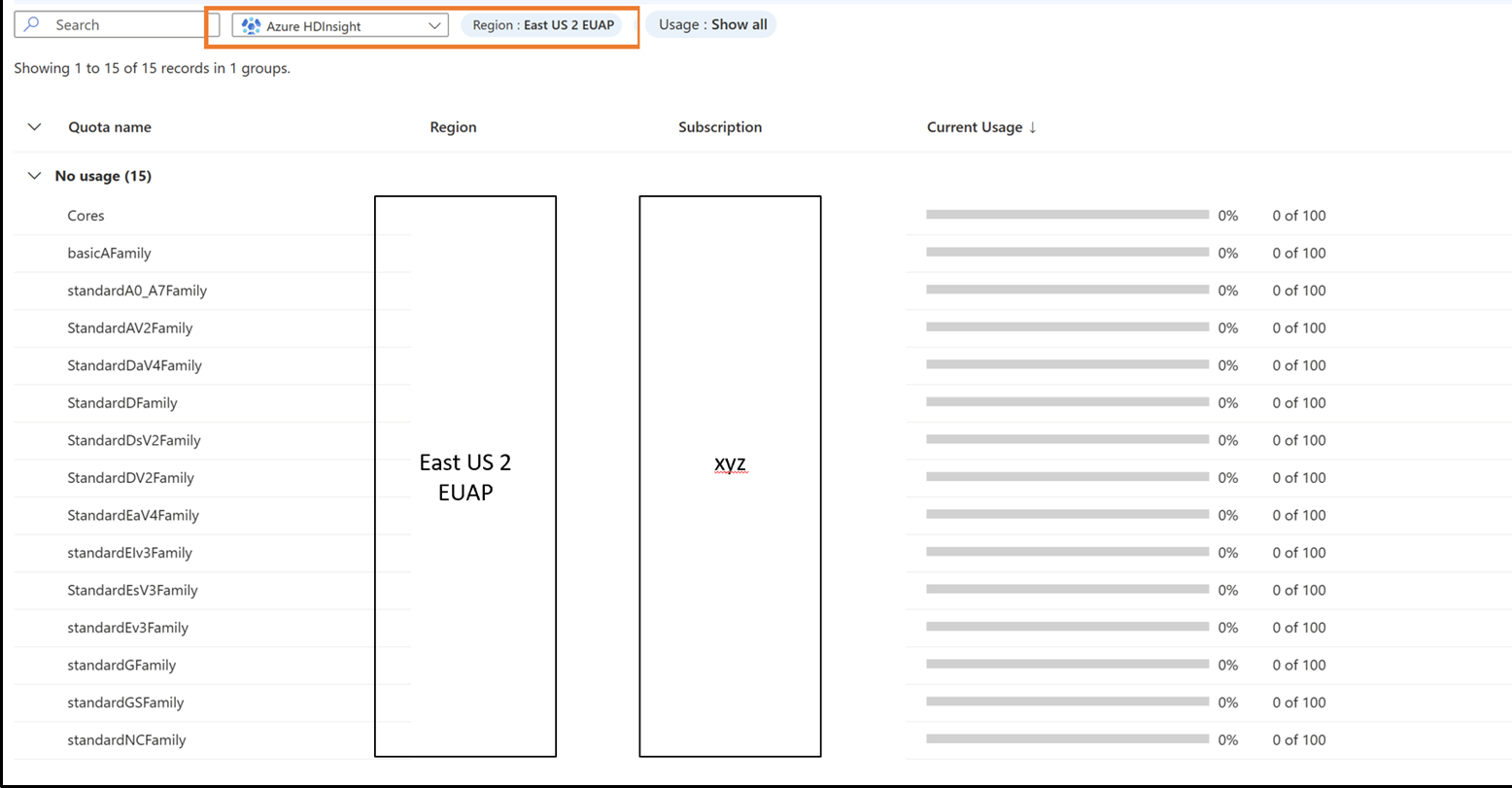
Request new quotas per VM family and region
- Click on the row for which you want to view the quota details.
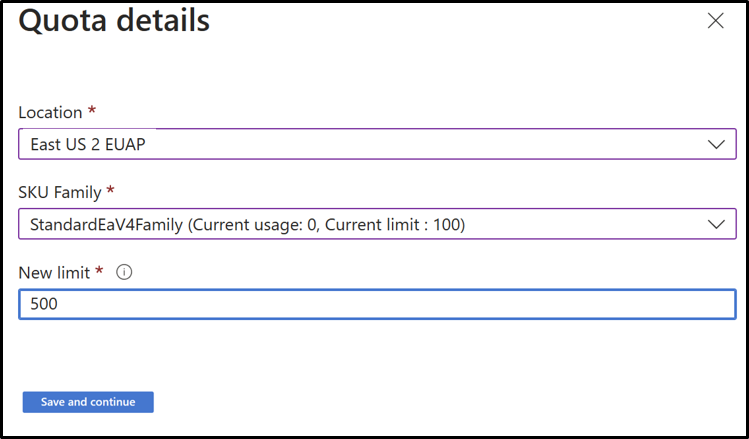




Quotas
For more information on managing subscription quotas, see Requesting quota increases.
Next steps
- Set up clusters in HDInsight with Apache Hadoop, Spark, Kafka, and more: Learn how to set up and configure clusters in HDInsight.
- Monitor cluster performance: Learn about key scenarios to monitor for your HDInsight cluster that might affect your cluster's capacity.