Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article provides step-by-step guidance on how to use HDInsight Tools in Azure Toolkit for IntelliJ to run Spark Failure Debug applications.
Prerequisites
Oracle Java Development kit. This tutorial uses Java version 8.0.202.
IntelliJ IDEA. This article uses IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. See Installing the Azure Toolkit for IntelliJ.
Connect to your HDInsight cluster. See Connect to your HDInsight cluster.
Microsoft Azure Storage Explorer. See Download Microsoft Azure Storage Explorer.
Create a project with debugging template
Create a spark2.3.2 project to continue failure debug, take failure task debugging sample file in this document.
Open IntelliJ IDEA. Open the New Project window.
a. Select Azure Spark/HDInsight from the left pane.
b. Select Spark Project with Failure Task Debugging Sample(Preview)(Scala) from the main window.
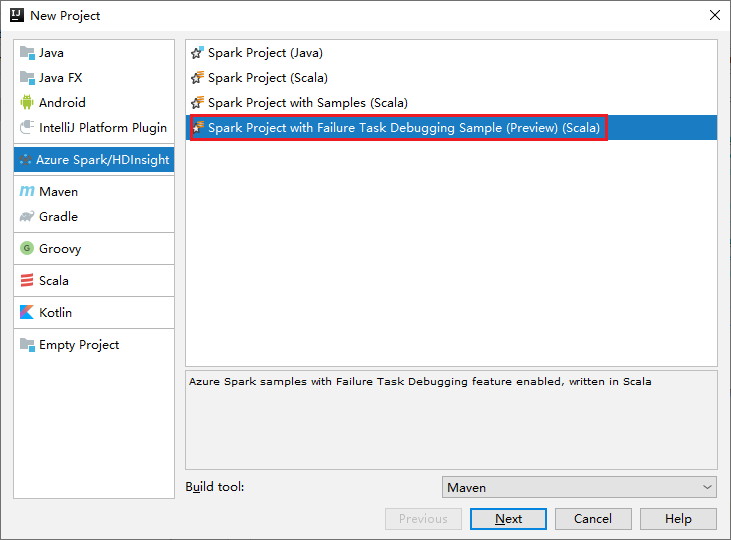
c. Select Next.
In the New Project window, do the following steps:
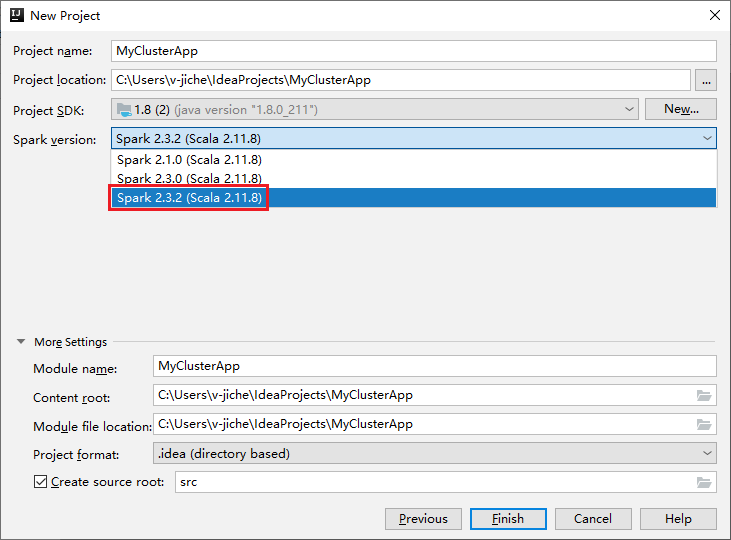
a. Enter a project name and project location.
b. In the Project SDK drop-down list, select Java 1.8 for Spark 2.3.2 cluster.
c. In the Spark Version drop-down list, select Spark 2.3.2(Scala 2.11.8).
d. Select Finish.
Select src > main > scala to open your code in the project. This example uses the AgeMean_Div() script.
Run a Spark Scala/Java application on an HDInsight cluster
Create a spark Scala/Java application, then run the application on a Spark cluster by doing the following steps:
Click Add Configuration to open Run/Debug Configurations window.

In the Run/Debug Configurations dialog box, select the plus sign (+). Then select the Apache Spark on HDInsight option.

Switch to Remotely Run in Cluster tab. Enter information for Name, Spark cluster, and Main class name. Our tools support debug with Executors. The numExecutors, the default value is 5, and you'd better not set higher than 3. To reduce the run time, you can add spark.yarn.maxAppAttempts into job Configurations and set the value to 1. Click OK button to save the configuration.
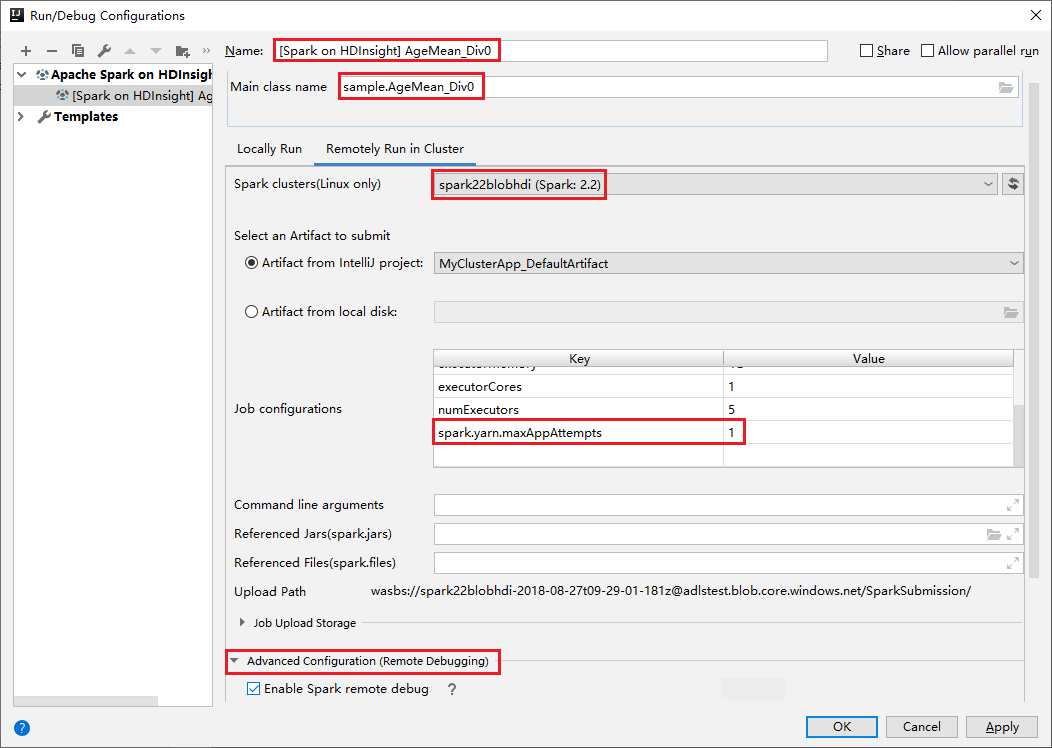
The configuration is now saved with the name you provided. To view the configuration details, select the configuration name. To make changes, select Edit Configurations.
After you complete the configurations settings, you can run the project against the remote cluster.

You can check the application ID from the output window.

Download failed job profile
If the job submission fails, you could download the failed job profile to the local machine for further debugging.
Open Microsoft Azure Storage Explorer, locate the HDInsight account of the cluster for the failed job, download the failed job resources from the corresponding location: \hdp\spark2-events\.spark-failures\<application ID> to a local folder. The activities window will show the download progress.

Configure local debugging environment and debug on failure
Open the original project or create a new project and associate it with the original source code. Only spark2.3.2 version is supported for failure debugging currently.
In IntelliJ IDEA, create a Spark Failure Debug config file, select the FTD file from the previously downloaded failed job resources for the Spark Job Failure Context location field.
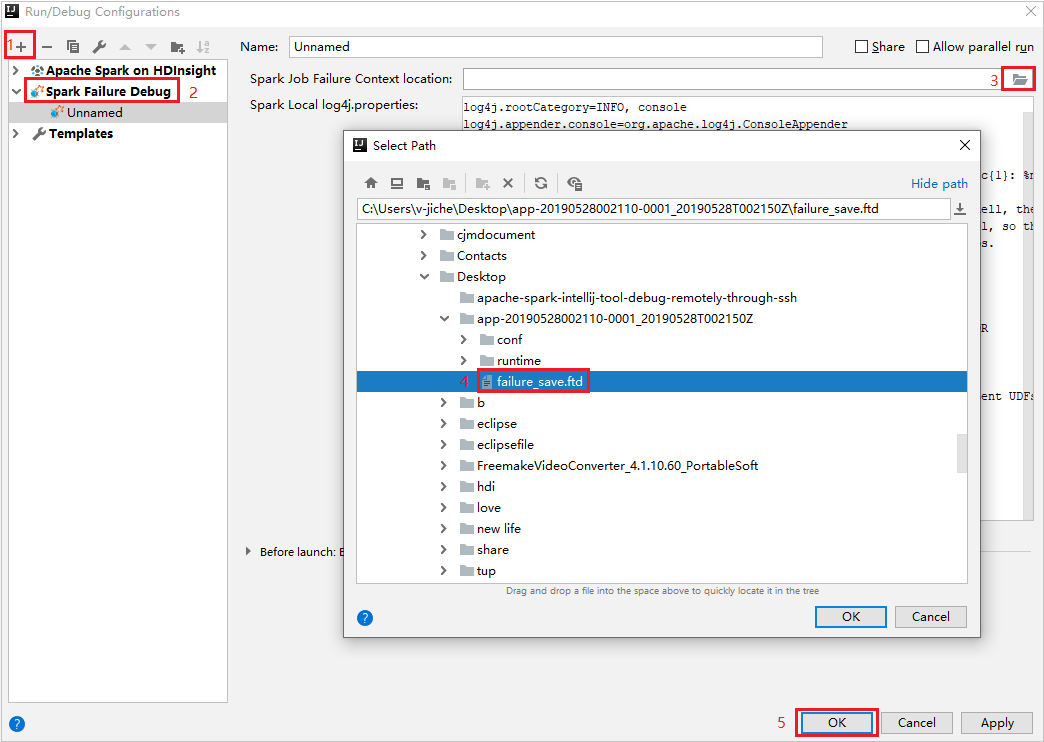
Click the local run button in the toolbar, the error will display in Run window.
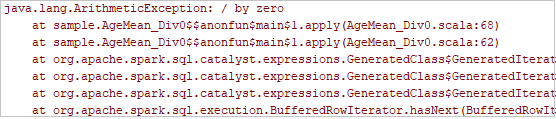
Set break point as the log indicates, then click local debug button to do local debugging just as your normal Scala / Java projects in IntelliJ.
After debugging, if the project completes successfully, you could resubmit the failed job to your spark on HDInsight cluster.
Next steps
Scenarios
- Apache Spark with BI: Do interactive data analysis by using Spark in HDInsight with BI tools
- Apache Spark with Machine Learning: Use Spark in HDInsight to analyze building temperature using HVAC data
- Apache Spark with Machine Learning: Use Spark in HDInsight to predict food inspection results
- Website log analysis using Apache Spark in HDInsight
Create and run applications
- Create a standalone application using Scala
- Run jobs remotely on an Apache Spark cluster using Apache Livy
Tools and extensions
- Use Azure Toolkit for IntelliJ to create Apache Spark applications for an HDInsight cluster
- Use Azure Toolkit for IntelliJ to debug Apache Spark applications remotely through VPN
- Use HDInsight Tools in Azure Toolkit for Eclipse to create Apache Spark applications
- Use Apache Zeppelin notebooks with an Apache Spark cluster on HDInsight
- Kernels available for Jupyter Notebook in the Apache Spark cluster for HDInsight
- Use external packages with Jupyter Notebooks
- Install Jupyter on your computer and connect to an HDInsight Spark cluster