Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
This article discusses how to optimize memory management of your Apache Spark cluster for best performance on Azure HDInsight.
Overview
Spark operates by placing data in memory. So managing memory resources is a key aspect of optimizing the execution of Spark jobs. There are several techniques you can apply to use your cluster's memory efficiently.
- Prefer smaller data partitions and account for data size, types, and distribution in your partitioning strategy.
- Consider the newer, more efficient
Kryo data serialization, rather than the default Java serialization. - Prefer using YARN, as it separates
spark-submitby batch. - Monitor and tune Spark configuration settings.
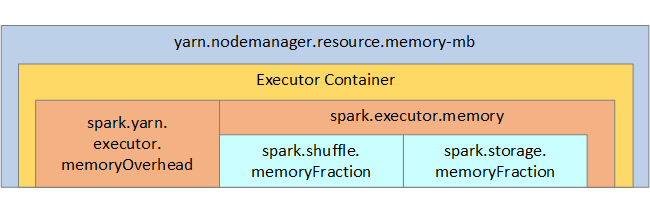
For your reference, the Spark memory structure and some key executor memory parameters are shown in the next image.
Spark memory considerations
If you're using Apache Hadoop YARN, then YARN controls the memory used by all containers on each Spark node. The following diagram shows the key objects and their relationships.
To address 'out of memory' messages, try:
- Review DAG Management Shuffles. Reduce by map-side reducing, pre-partition (or bucketize) source data, maximize single shuffles, and reduce the amount of data sent.
- Prefer
ReduceByKeywith its fixed memory limit toGroupByKey, which provides aggregations, windowing, and other functions but it has ann unbounded memory limit. - Prefer
TreeReduce, which does more work on the executors or partitions, toReduce, which does all work on the driver. - Use DataFrames rather than the lower-level RDD objects.
- Create ComplexTypes that encapsulate actions, such as "Top N", various aggregations, or windowing operations.
For additional troubleshooting steps, see OutOfMemoryError exceptions for Apache Spark in Azure HDInsight.