Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The profiling feature in Azure Machine Learning studio can help you debug pipeline performance issues such as hanging or long durations. Profiling lists the duration of each pipeline step and provides a Gantt chart for visualization. You can see the time spent on each job status and quickly find steps that take longer than expected.
Find the node that runs the longest overall
On the Jobs page of Azure Machine Learning studio, select the job name to open the job detail page.
In the action bar, select View profiling. Profiling works only for root pipelines. The profiler page can take a few minutes to load.
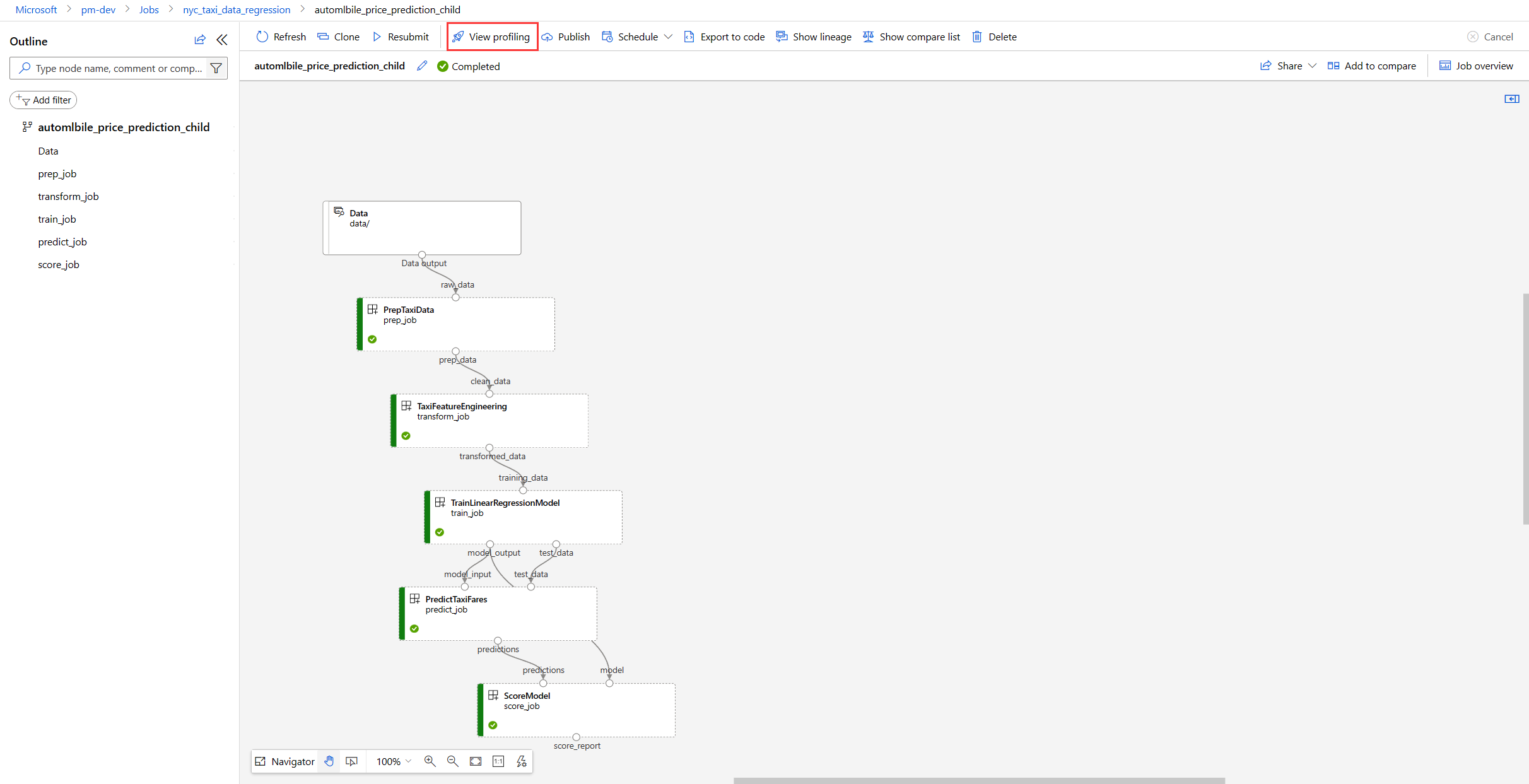
To identify the step that takes the longest, view the Gantt chart at the top of the profiler page. The length of each bar in the Gantt chart shows how long the step takes. The step with the longest bar length took the most time.

The Gantt chart has the following views:
- Critical path is the sequence of steps that determine the job's total duration. This view is shown by default. Only step jobs that have a dependency appear in a pipeline's critical path.
- Flatten view shows all step jobs, and shows more nodes than critical path.
- Compact view shows only step jobs that took longer than 30 seconds.
- Hierarchical view shows all jobs, including pipeline component jobs and step jobs.
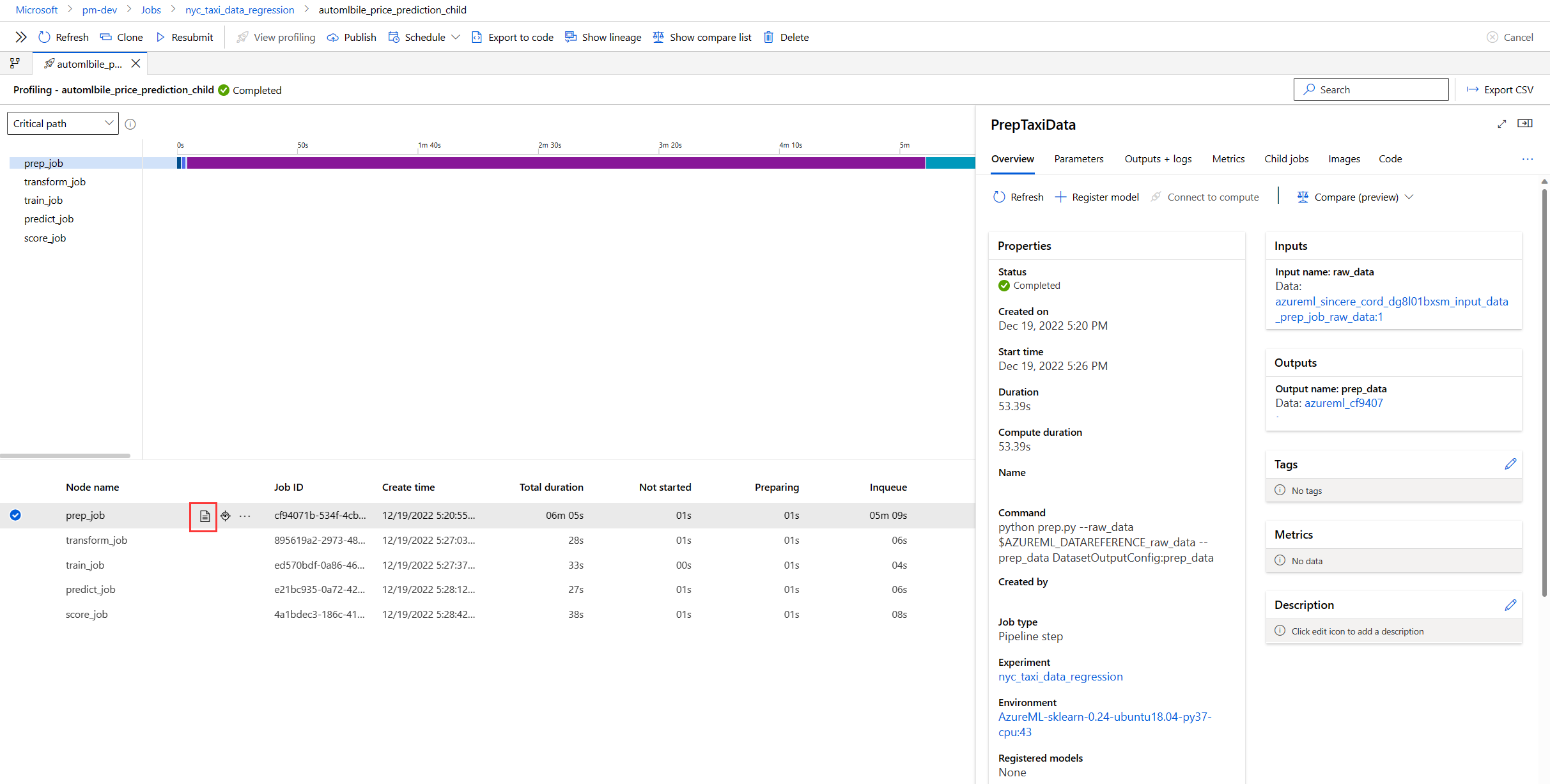
You can also determine durations by using the table at the bottom of the profiler page. When you select a row in the table, it highlights the corresponding node in the Gantt chart, and vice versa.
In the table, you can sort by the Total duration column to find the longest-running nodes.
Select the View details icon next to a node name in the table to open the node detail pane, which shows parameters, inputs and outputs, command code, logs, and other information.
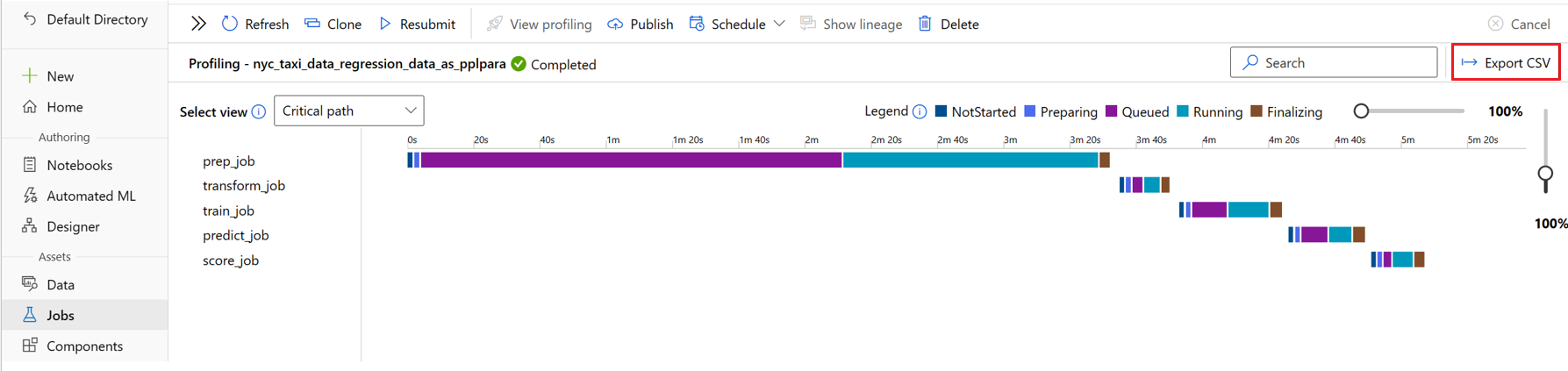
To export the duration table, select Export CSV at upper right on the profiler page.

Find the node that runs the longest in each status
Besides total duration, you can also sort the duration table by durations for each status. For example, you can sort by the Preparing column to see which step spends the most time on image building. You can open the detail pane for that step to see whether image building fails because of timeout issues.
Address status duration issues
The following table presents the definition of each job status, the estimated time it takes, and suggestions for addressing issues with that status.
| Status | Definition | Time estimation | Next steps |
|---|---|---|---|
| Not started | The job is submitted from the client and accepted in Azure Machine Learning services. Most time is spent in service scheduling and preprocessing. | If there's no backend service issue, this time should be short. | Open a support case via the Azure portal. |
| Preparing | In this status, the job is pending for preparation of job dependencies, for example environment image building. | If you're using a curated or registered custom environment, this time should be short. | Check the image building log. |
| Inqueue | The job is pending for compute resource allocation. Duration of this stage mainly depends on the status of your compute cluster. | If you're using a cluster with enough compute resource, this time should be short. | Increase the max nodes of the target compute, change the job to another less busy compute, or modify job priority to get more compute resources for the job. |
| Running | The job is executing on the remote compute. This stage consists of: 1. Runtime preparation, such as image pulling, docker starting, and data mounting or download. 2. User script execution. |
This status is expected to be the most time consuming. | 1. Check the source code for any user error. 2. View the monitoring tab for compute metrics like CPU, memory, and networking to identify any bottlenecks. 3. If the job is running, try online debug with interactive endpoints, or locally debug your code. |
| Finalizing | Job is in post-processing after execution completes. Time spent in this stage is mainly for post processes like uploading output, uploading metrics and logs, and cleaning up resources. | Time is expected to be short for command jobs. Duration might be long for polygenic risk score (PRS) or Message Passing Interface (MPI) jobs because for distributed jobs, finalizing lasts from the first node starting to the last node finishing. | Change your step job output mode from upload to mount if you find unexpected long finalizing time, or open a support case via the Azure portal. |