Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Machine learning model training is an iterative process and requires significant experimentation. With the Azure Machine Learning interactive job experience, data scientists can use the Azure Machine Learning Python SDK, Azure Machine Learning CLI or the Azure Studio to access the container where their job is running. Once the job container is accessed, users can iterate on training scripts, monitor training progress or debug the job remotely like they typically do on their local machines. Jobs can be interacted with via different training applications including JupyterLab, TensorBoard, VS Code or by connecting to the job container directly via SSH.
Interactive training is supported on Azure Machine Learning Compute Clusters and Azure Arc-enabled Kubernetes Cluster.
Prerequisites
- Review getting started with training on Azure Machine Learning.
- For more information, see this link for VS Code to set up the Azure Machine Learning extension.
- Make sure your job environment has the
openssh-serverandipykernel ~=6.0packages installed (all Azure Machine Learning curated training environments have these packages installed by default). - Interactive applications can't be enabled on distributed training runs where the distribution type is anything other than PyTorch, TensorFlow, or MPI. Custom distributed training setup (configuring multi-node training without using the above distribution frameworks) isn't currently supported.
- To use SSH, you need an SSH key pair. You can use the
ssh-keygen -f "<filepath>"command to generate a public and private key pair.
Interact with your job container
By specifying interactive applications at job creation, you can connect directly to the container on the compute node where your job is running. Once you have access to the job container, you can test or debug your job in the exact same environment where it would run. You can also use VS Code to attach to the running process and debug as you would locally.
Enable during job submission
Create a new job from the left pane in the studio portal.
Choose Compute cluster or Attached compute (Kubernetes) as the compute type, choose the compute target, and specify how many nodes you need in
Instance count.
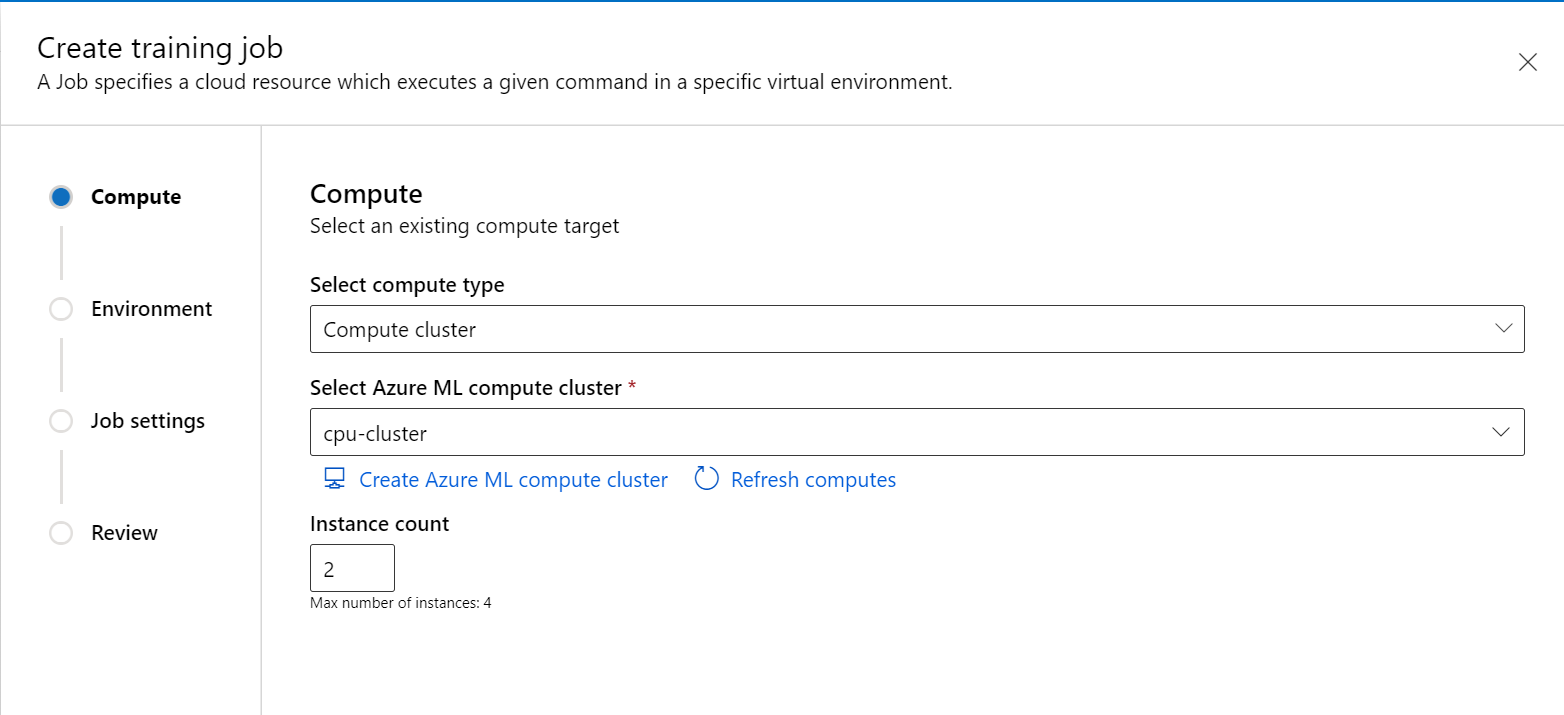
Follow the wizard to choose the environment you want to start the job.
In the Training script step, add your training code (and input/output data) and reference it in your command to make sure it's mounted to your job.
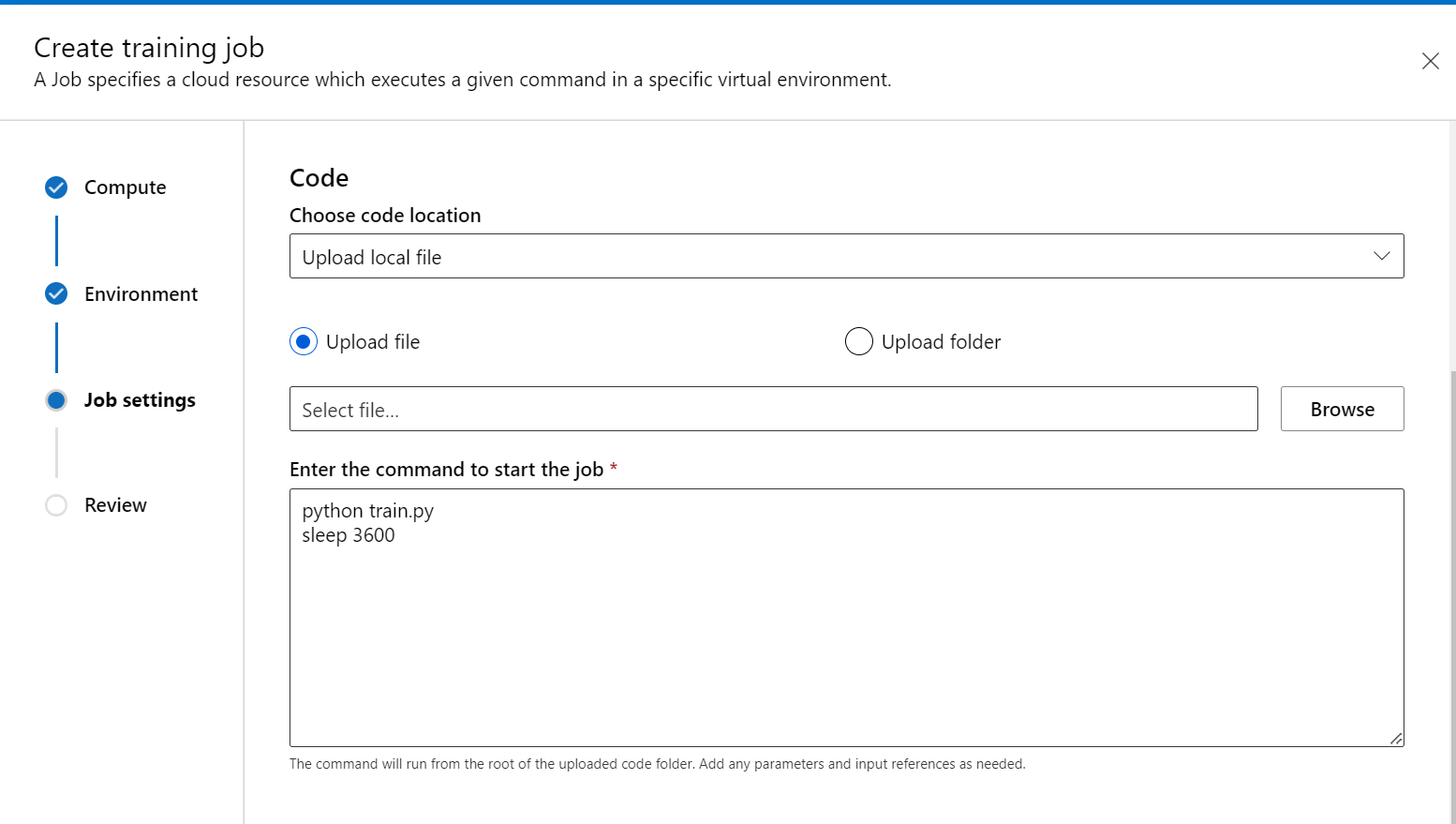
You can put sleep <specific time> at the end of your command to specify the amount of time you want to reserve the compute resource. The format follows:
- sleep 1s
- sleep 1m
- sleep 1h
- sleep 1d
You can also use the sleep infinity command that would keep the job alive indefinitely.
Note
If you use sleep infinity, you will need to manually cancel the job to let go of the compute resource (and stop billing).
- In Compute settings, expand the option for Training applications. Select at least one training application you want to use to interact with the job. If you don't select an application, the debug feature won't be available.

- Review and create the job.
Connect to endpoints
To interact with your running job, select the button Debug and monitor on the job details page.
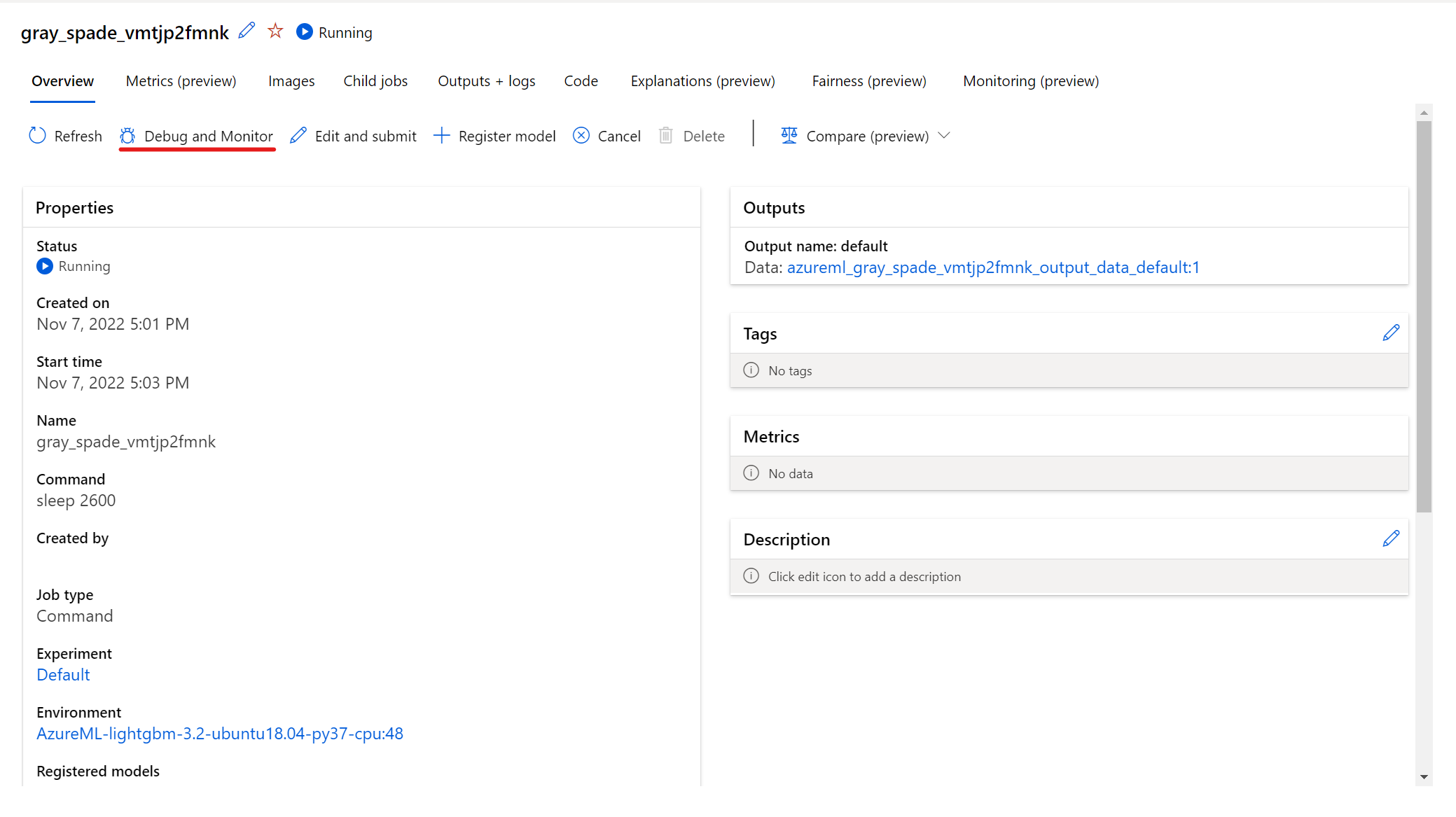
Clicking the applications in the panel opens a new tab for the applications. You can access the applications only when they are in Running status and only the job owner is authorized to access the applications. If you're training on multiple nodes, you can pick the specific node you would like to interact with.
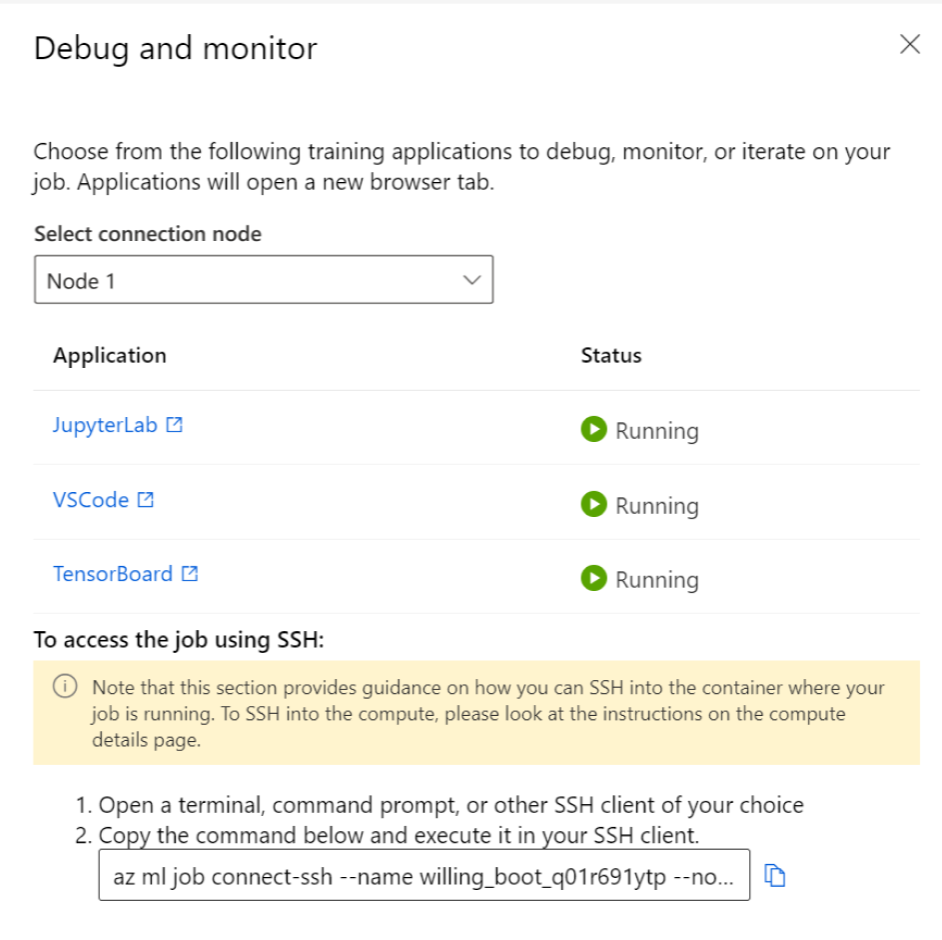
It might take a few minutes to start the job and the training applications specified during job creation.
Interact with the applications
When you select on the endpoints to interact when your job, you're taken to the user container under your working directory, where you can access your code, inputs, outputs, and logs. If you run into any issues while connecting to the applications, the interactive capability and applications logs can be found from system_logs->interactive_capability under Outputs + logs tab.
You can open a terminal from Jupyter Lab and start interacting within the job container. You can also directly iterate on your training script with Jupyter Lab.
You can also interact with the job container within VS Code. To attach a debugger to a job during job submission and pause execution, navigate here.
Note
Private link-enabled workspaces are not currently supported when interacting with the job container with VS Code.
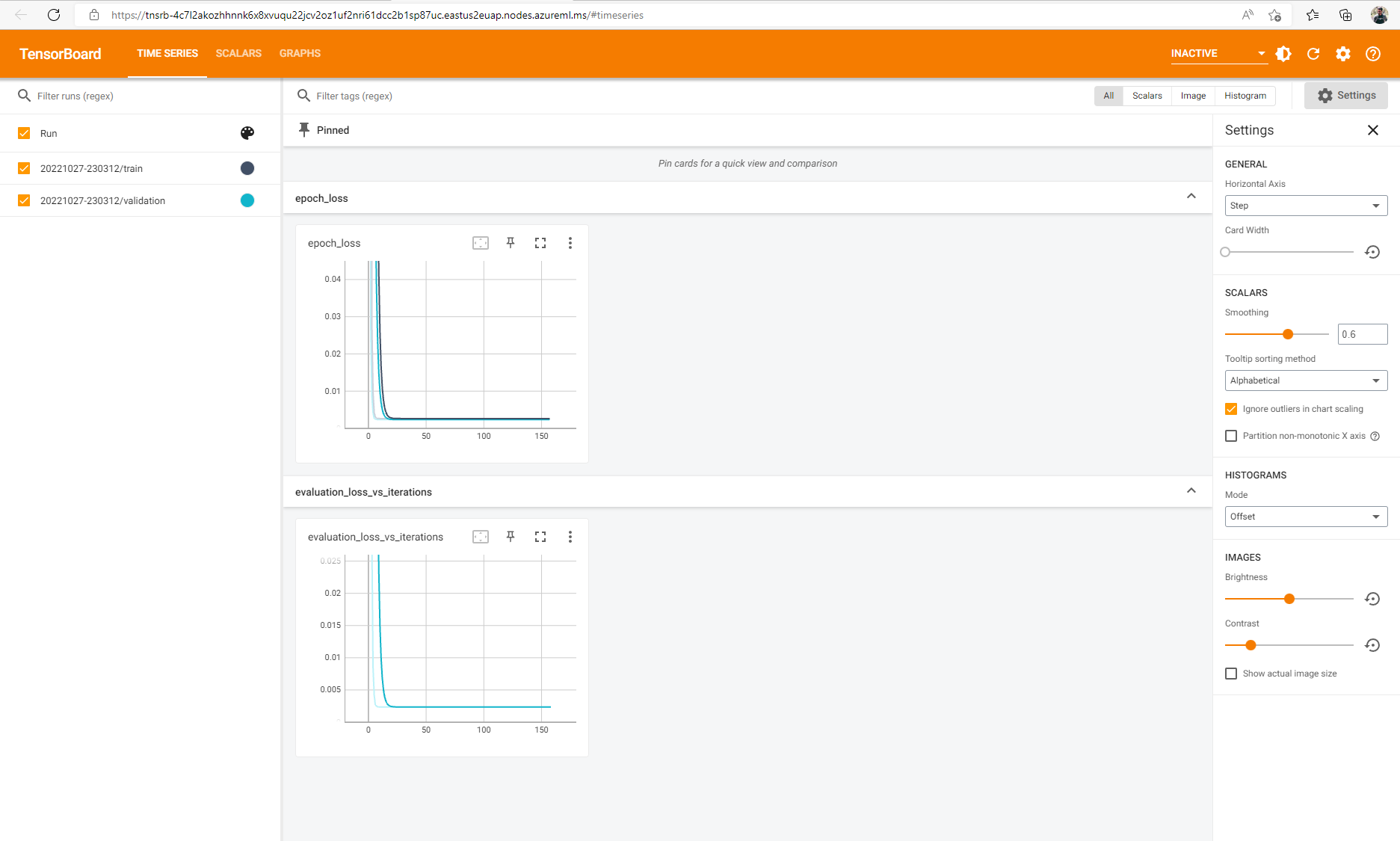
If you have logged tensorflow events for your job, you can use TensorBoard to monitor the metrics when your job is running.
End job
Once you're done with the interactive training, you can also go to the job details page to cancel the job, which will release the compute resource. Alternatively, use az ml job cancel -n <your job name> in the CLI or ml_client.job.cancel("<job name>") in the SDK.

Attach a debugger to a job
To submit a job with a debugger attached and the execution paused, you can use debugpy, and VS Code (debugpy must be installed in your job environment).
Note
Private link-enabled workspaces are not currently supported when attaching a debugger to a job in VS Code.
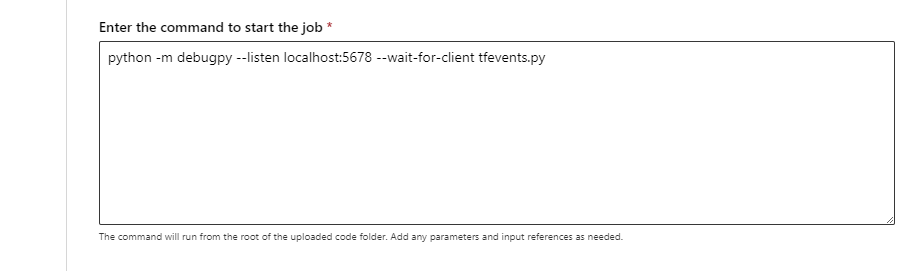
- During job submission (either through the UI, the CLI or the SDK) use the debugpy command to run your python script. For example, the following screenshot shows a sample command that uses debugpy to attach the debugger for a tensorflow script (
tfevents.pycan be replaced with the name of your training script).
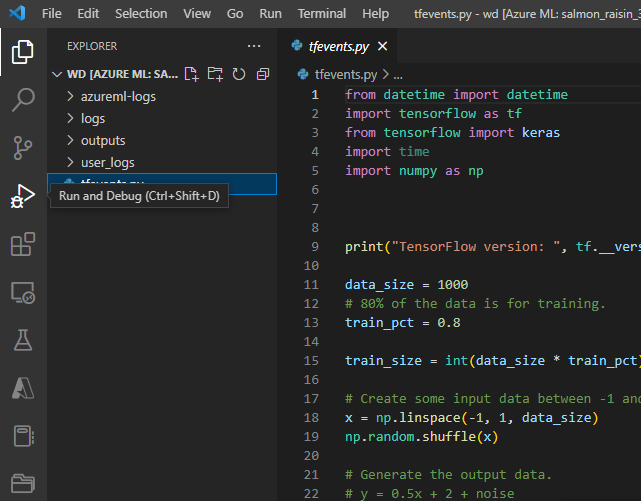
Once the job has been submitted, connect to the VS Code, and select the in-built debugger.
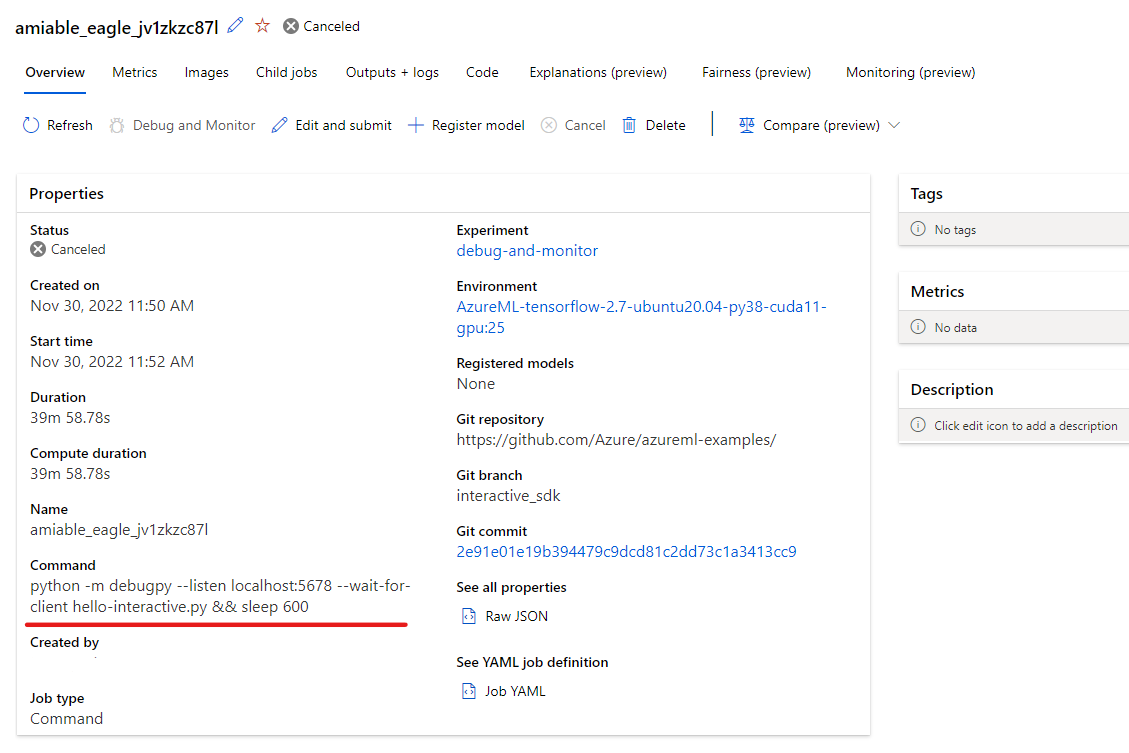
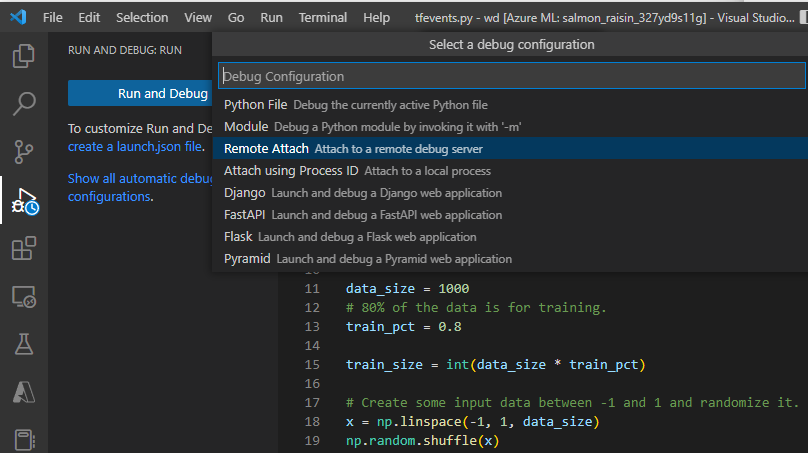
Use the "Remote Attach" debug configuration to attach to the submitted job and pass in the path and port you configured in your job submission command. You can also find this information on the job details page.
Set breakpoints and walk through your job execution as you would in your local debugging workflow.
Note
If you use debugpy to start your job, your job will not execute unless you attach the debugger in VS Code and execute the script. If this is not done, the compute will be reserved until the job is cancelled.
Next steps
- Learn more about how and where to deploy a model.