Deploy MLflow models in batch deployments
APPLIES TO:
 Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
Azure CLI ml extension v2 (current)
Python SDK azure-ai-ml v2 (current)
In this article, learn how to deploy MLflow models to Azure Machine Learning for both batch inference using batch endpoints. When deploying MLflow models to batch endpoints, Azure Machine Learning:
- Provides a MLflow base image/curated environment that contains the required dependencies to run an Azure Machine Learning Batch job.
- Creates a batch job pipeline with a scoring script for you that can be used to process data using parallelization.
Note
For more information about the supported input file types and details about how MLflow model works see Considerations when deploying to batch inference.
About this example
This example shows how you can deploy an MLflow model to a batch endpoint to perform batch predictions. This example uses an MLflow model based on the UCI Heart Disease Data Set. The database contains 76 attributes, but we're using a subset of 14 of them. The model tries to predict the presence of heart disease in a patient. It is integer valued from 0 (no presence) to 1 (presence).
The model has been trained using an XGBBoost classifier and all the required preprocessing has been packaged as a scikit-learn pipeline, making this model an end-to-end pipeline that goes from raw data to predictions.
The example in this article is based on code samples contained in the azureml-examples repository. To run the commands locally without having to copy/paste YAML and other files, first clone the repo and then change directories to the folder:
git clone https://github.com/Azure/azureml-examples --depth 1
cd azureml-examples/cli
The files for this example are in:
cd endpoints/batch/deploy-models/heart-classifier-mlflow
Follow along in Jupyter Notebooks
You can follow along this sample in the following notebooks. In the cloned repository, open the notebook: mlflow-for-batch-tabular.ipynb.
Prerequisites
Before following the steps in this article, make sure you have the following prerequisites:
An Azure subscription. If you don't have an Azure subscription, create a free account before you begin. Try the free or paid version of Azure Machine Learning.
An Azure Machine Learning workspace. If you don't have one, use the steps in the Manage Azure Machine Learning workspaces article to create one.
Ensure that you have the following permissions in the workspace:
Create or manage batch endpoints and deployments: Use an Owner, Contributor, or Custom role that allows
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*.Create ARM deployments in the workspace resource group: Use an Owner, Contributor, or Custom role that allows
Microsoft.Resources/deployments/writein the resource group where the workspace is deployed.
You need to install the following software to work with Azure Machine Learning:
The Azure CLI and the
mlextension for Azure Machine Learning.az extension add -n mlNote
Pipeline component deployments for Batch Endpoints were introduced in version 2.7 of the
mlextension for Azure CLI. Useaz extension update --name mlto get the last version of it.
Connect to your workspace
The workspace is the top-level resource for Azure Machine Learning, providing a centralized place to work with all the artifacts you create when you use Azure Machine Learning. In this section, we'll connect to the workspace in which you'll perform deployment tasks.
Pass in the values for your subscription ID, workspace, location, and resource group in the following code:
az account set --subscription <subscription>
az configure --defaults workspace=<workspace> group=<resource-group> location=<location>
Steps
Follow these steps to deploy an MLflow model to a batch endpoint for running batch inference over new data:
Batch Endpoint can only deploy registered models. In this case, we already have a local copy of the model in the repository, so we only need to publish the model to the registry in the workspace. You can skip this step if the model you're trying to deploy is already registered.
Before moving any forward, we need to make sure the batch deployments we're about to create can run on some infrastructure (compute). Batch deployments can run on any Azure Machine Learning compute that already exists in the workspace. That means that multiple batch deployments can share the same compute infrastructure. In this example, we're going to work on an Azure Machine Learning compute cluster called
cpu-cluster. Let's verify the compute exists on the workspace or create it otherwise.Now it is time to create the batch endpoint and deployment. Let's start with the endpoint first. Endpoints only require a name and a description to be created. The name of the endpoint will end-up in the URI associated with your endpoint. Because of that, batch endpoint names need to be unique within an Azure region. For example, there can be only one batch endpoint with the name
mybatchendpointinwestus2.Create the endpoint:
To create a new endpoint, create a
YAMLconfiguration like the following:endpoint.yml
$schema: https://azuremlschemas.azureedge.net/latest/batchEndpoint.schema.json name: heart-classifier-batch description: A heart condition classifier for batch inference auth_mode: aad_tokenThen, create the endpoint with the following command:
az ml batch-endpoint create -n $ENDPOINT_NAME -f endpoint.ymlNow, let create the deployment. MLflow models don't require you to indicate an environment or a scoring script when creating the deployments as it is created for you. However, you can specify them if you want to customize how the deployment does inference.
To create a new deployment under the created endpoint, create a
YAMLconfiguration like the following. You can check the full batch endpoint YAML schema for extra properties.deployment-simple/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json endpoint_name: heart-classifier-batch name: classifier-xgboost-mlflow description: A heart condition classifier based on XGBoost type: model model: azureml:heart-classifier-mlflow@latest compute: azureml:batch-cluster resources: instance_count: 2 settings: max_concurrency_per_instance: 2 mini_batch_size: 2 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 300 error_threshold: -1 logging_level: infoThen, create the deployment with the following command:
az ml batch-deployment create --file deployment-simple/deployment.yml --endpoint-name $ENDPOINT_NAME --set-defaultImportant
Configure
timeoutin your deployment based on how long it takes for your model to run inference on a single batch. The bigger the batch size the longer this value has to be. Remeber thatmini_batch_sizeindicates the number of files in a batch, not the number of samples. When working with tabular data, each file may contain multiple rows which will increase the time it takes for the batch endpoint to process each file. Use high values on those cases to avoid time out errors.Although you can invoke a specific deployment inside of an endpoint, you'll usually want to invoke the endpoint itself and let the endpoint decide which deployment to use. Such deployment is named the "default" deployment. This gives you the possibility of changing the default deployment and hence changing the model serving the deployment without changing the contract with the user invoking the endpoint. Use the following instruction to update the default deployment:
At this point, our batch endpoint is ready to be used.
Testing out the deployment
For testing our endpoint, we're going to use a sample of unlabeled data located in this repository and that can be used with the model. Batch endpoints can only process data that is located in the cloud and that is accessible from the Azure Machine Learning workspace. In this example, we're going to upload it to an Azure Machine Learning data store. Particularly, we're going to create a data asset that can be used to invoke the endpoint for scoring. However, notice that batch endpoints accept data that can be placed in various locations.
Let's create the data asset first. This data asset consists of a folder with multiple CSV files that we want to process in parallel using batch endpoints. You can skip this step is your data is already registered as a data asset or you want to use a different input type.
a. Create a data asset definition in
YAML:heart-dataset-unlabeled.yml
$schema: https://azuremlschemas.azureedge.net/latest/data.schema.json name: heart-dataset-unlabeled description: An unlabeled dataset for heart classification. type: uri_folder path: datab. Create the data asset:
az ml data create -f heart-dataset-unlabeled.ymlNow that the data is uploaded and ready to be used, let's invoke the endpoint:
JOB_NAME = $(az ml batch-endpoint invoke --name $ENDPOINT_NAME --input azureml:heart-dataset-unlabeled@latest --query name -o tsv)Note
The utility
jqmay not be installed on every installation. You can get installation instructions in this link.Tip
Notice how we're not indicating the deployment name in the invoke operation. That's because the endpoint automatically routes the job to the default deployment. Since our endpoint only has one deployment, then that one is the default one. You can target an specific deployment by indicating the argument/parameter
deployment_name.A batch job is started as soon as the command returns. You can monitor the status of the job until it finishes:
Analyzing the outputs
Output predictions are generated in the predictions.csv file as indicated in the deployment configuration. The job generates a named output called score where this file is placed. Only one file is generated per batch job.
The file is structured as follows:
There is one row per each data point that was sent to the model. For tabular data, it means that the file (
predictions.csv) contains one row for every row present in each of the processed files. For other data types (e.g. images, audio, text), there is one row per each processed file.The following columns are in the file (in order):
row(optional), the corresponding row index in the input data file. This only applies if the input data is tabular. Predictions are returned in the same order they appear in the input file so you can rely on the row number to match the corresponding prediction.prediction, the prediction associated with the input data. This value is returned "as-is" it was provided by the model'spredict().function.file_name, the file name where the data was read from. In tabular data, use this field to know which prediction belongs to which input data.
You can download the results of the job by using the job name:
To download the predictions, use the following command:
az ml job download --name $JOB_NAME --output-name score --download-path ./
Once the file is downloaded, you can open it using your favorite tool. The following example loads the predictions using Pandas dataframe.
import pandas as pd
score = pd.read_csv(
"named-outputs/score/predictions.csv", names=["row", "prediction", "file"]
)The output looks as follows:
| row | prediction | file |
|---|---|---|
| 0 | 0 | heart-unlabeled-0.csv |
| 1 | 1 | heart-unlabeled-0.csv |
| 2 | 0 | heart-unlabeled-0.csv |
| ... | ... | ... |
| 307 | 0 | heart-unlabeled-3.csv |
Tip
Notice that in this example the input data was tabular data in CSV format and there were 4 different input files (heart-unlabeled-0.csv, heart-unlabeled-1.csv, heart-unlabeled-2.csv and heart-unlabeled-3.csv).
Considerations when deploying to batch inference
Azure Machine Learning supports deploying MLflow models to batch endpoints without indicating a scoring script. This represents a convenient way to deploy models that require processing of big amounts of data in a batch-fashion. Azure Machine Learning uses information in the MLflow model specification to orchestrate the inference process.
How work is distributed on workers
Batch Endpoints distribute work at the file level, for both structured and unstructured data. As a consequence, only URI file and URI folders are supported for this feature. Each worker processes batches of Mini batch size files at a time. For tabular data, batch endpoints don't take into account the number of rows inside of each file when distributing the work.
Warning
Nested folder structures are not explored during inference. If you're partitioning your data using folders, make sure to flatten the structure beforehand.
Batch deployments will call the predict function of the MLflow model once per file. For CSV files containing multiple rows, this may impose a memory pressure in the underlying compute and may increase the time it takes for the model to score a single file (specially for expensive models like large language models). If you encounter several out-of-memory exceptions or time-out entries in logs, consider splitting the data in smaller files with less rows or implement batching at the row level inside of the model/scoring script.
File's types support
The following data types are supported for batch inference when deploying MLflow models without an environment and a scoring script. If you like to process a different file type, or execute inference in a different way that batch endpoints do by default you can always create the deployment with a scoring script as explained in Using MLflow models with a scoring script.
| File extension | Type returned as model's input | Signature requirement |
|---|---|---|
.csv, .parquet, .pqt |
pd.DataFrame |
ColSpec. If not provided, columns typing is not enforced. |
.png, .jpg, .jpeg, .tiff, .bmp, .gif |
np.ndarray |
TensorSpec. Input is reshaped to match tensors shape if available. If no signature is available, tensors of type np.uint8 are inferred. For additional guidance read Considerations for MLflow models processing images. |
Warning
Be advised that any unsupported file that may be present in the input data will make the job to fail. You'll see an error entry as follows: "ERROR:azureml:Error processing input file: '/mnt/batch/tasks/.../a-given-file.avro'. File type 'avro' is not supported.".
Signature enforcement for MLflow models
Input's data types are enforced by batch deployment jobs while reading the data using the available MLflow model signature. This means that your data input should comply with the types indicated in the model signature. If the data can't be parsed as expected, the job will fail with an error message similar to the following one: "ERROR:azureml:Error processing input file: '/mnt/batch/tasks/.../a-given-file.csv'. Exception: invalid literal for int() with base 10: 'value'".
Tip
Signatures in MLflow models are optional but they are highly encouraged as they provide a convenient way to early detect data compatibility issues. For more information about how to log models with signatures read Logging models with a custom signature, environment or samples.
You can inspect the model signature of your model by opening the MLmodel file associated with your MLflow model. For more details about how signatures work in MLflow see Signatures in MLflow.
Flavor support
Batch deployments only support deploying MLflow models with a pyfunc flavor. If you need to deploy a different flavor, see Using MLflow models with a scoring script.
Customizing MLflow models deployments with a scoring script
MLflow models can be deployed to batch endpoints without indicating a scoring script in the deployment definition. However, you can opt in to indicate this file (usually referred as the batch driver) to customize how inference is executed.
You'll typically select this workflow when:
- You need to process a file type not supported by batch deployments MLflow deployments.
- You need to customize the way the model is run, for instance, use an specific flavor to load it with
mlflow.<flavor>.load(). - You need to do pre/pos processing in your scoring routine when it is not done by the model itself.
- The output of the model can't be nicely represented in tabular data. For instance, it is a tensor representing an image.
- You model can't process each file at once because of memory constrains and it needs to read it in chunks.
Important
If you choose to indicate a scoring script for an MLflow model deployment, you'll also have to specify the environment where the deployment will run.
Steps
Use the following steps to deploy an MLflow model with a custom scoring script.
Identify the folder where your MLflow model is placed.
a. Go to Azure Machine Learning portal.
b. Go to the section Models.
c. Select the model you're trying to deploy and click on the tab Artifacts.
d. Take note of the folder that is displayed. This folder was indicated when the model was registered.
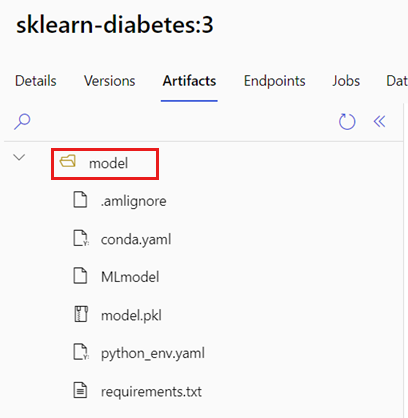
Create a scoring script. Notice how the folder name
modelyou identified before has been included in theinit()function.deployment-custom/code/batch_driver.py
# Copyright (c) Microsoft. All rights reserved. # Licensed under the MIT license. import os import glob import mlflow import pandas as pd import logging def init(): global model global model_input_types global model_output_names # AZUREML_MODEL_DIR is an environment variable created during deployment # It is the path to the model folder # Please provide your model's folder name if there's one model_path = glob.glob(os.environ["AZUREML_MODEL_DIR"] + "/*/")[0] # Load the model, it's input types and output names model = mlflow.pyfunc.load(model_path) if model.metadata and model.metadata.signature: if model.metadata.signature.inputs: model_input_types = dict( zip( model.metadata.signature.inputs.input_names(), model.metadata.signature.inputs.pandas_types(), ) ) if model.metadata.signature.outputs: if model.metadata.signature.outputs.has_input_names(): model_output_names = model.metadata.signature.outputs.input_names() elif len(model.metadata.signature.outputs.input_names()) == 1: model_output_names = ["prediction"] else: logging.warning( "Model doesn't contain a signature. Input data types won't be enforced." ) def run(mini_batch): print(f"run method start: {__file__}, run({len(mini_batch)} files)") data = pd.concat( map( lambda fp: pd.read_csv(fp).assign(filename=os.path.basename(fp)), mini_batch ) ) if model_input_types: data = data.astype(model_input_types) # Predict over the input data, minus the column filename which is not part of the model. pred = model.predict(data.drop("filename", axis=1)) if pred is not pd.DataFrame: if not model_output_names: model_output_names = ["pred_col" + str(i) for i in range(pred.shape[1])] pred = pd.DataFrame(pred, columns=model_output_names) return pd.concat([data, pred], axis=1)Let's create an environment where the scoring script can be executed. Since our model is MLflow, the conda requirements are also specified in the model package (for more details about MLflow models and the files included on it see The MLmodel format). We're going then to build the environment using the conda dependencies from the file. However, we need also to include the package
azureml-corewhich is required for Batch Deployments.Tip
If your model is already registered in the model registry, you can download/copy the
conda.ymlfile associated with your model by going to Azure Machine Learning studio > Models > Select your model from the list > Artifacts. Open the root folder in the navigation and select theconda.ymlfile listed. Click on Download or copy its content.Important
This example uses a conda environment specified at
/heart-classifier-mlflow/environment/conda.yaml. This file was created by combining the original MLflow conda dependencies file and adding the packageazureml-core. You can't use theconda.ymlfile from the model directly.The environment definition will be included in the deployment definition itself as an anonymous environment. You'll see in the following lines in the deployment:
environment: name: batch-mlflow-xgboost image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yamlConfigure the deployment:
To create a new deployment under the created endpoint, create a
YAMLconfiguration like the following. You can check the full batch endpoint YAML schema for extra properties.deployment-custom/deployment.yml
$schema: https://azuremlschemas.azureedge.net/latest/modelBatchDeployment.schema.json endpoint_name: heart-classifier-batch name: classifier-xgboost-custom description: A heart condition classifier based on XGBoost type: model model: azureml:heart-classifier-mlflow@latest environment: name: batch-mlflow-xgboost image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest conda_file: environment/conda.yaml code_configuration: code: code scoring_script: batch_driver.py compute: azureml:batch-cluster resources: instance_count: 2 settings: max_concurrency_per_instance: 2 mini_batch_size: 2 output_action: append_row output_file_name: predictions.csv retry_settings: max_retries: 3 timeout: 300 error_threshold: -1 logging_level: infoLet's create the deployment now:
At this point, our batch endpoint is ready to be used.

Clean up resources
Run the following code to delete the batch endpoint and all the underlying deployments. Batch scoring jobs won't be deleted.
az ml batch-endpoint delete --name $ENDPOINT_NAME --yes
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for