Deployment scenarios
Microsoft deploys payment hardware security modules (HSM) in stamps within a region and multi-region to enable high availability (HA) and disaster recovery. In a region, HSMs are deployed across different stamps to prevent single rack failure, and customers must provision two devices in a region from two separate stamps in order to achieve high availability. For disaster recovery, customer must provision HSM devices in an alternative region.
Thales doesn't provide PayShield SDK to customers, which supports HA over a cluster (a collection of HSMs initialized with same LMK). However, the customers usage scenario of the Thales PayShield devices is like a Stateless Server. Thus, no synchronization is required between HSMs during application runtime. Customers handle the HA using their custom client. One implementation would be to load balance between healthy HSMs connected to the application. Customers are responsible for implementing high availability by provisioning multiple devices, load balancing them, and using any kind of available backup mechanism to back up keys.
Important
- Ensure your Microsoft Cloud Solution Architect has reviewed your payment HSM deployment architecture design and readiness before production launch.
- Review the supported topologies and constraints listed in the Solution design.
- Network Security Groups and User Defined Routes are not supported for payment HSM subnets.
- Virtual network peering does not support cross-region communication with payment HSM instances. A VM in one region cannot communicate with a payment HSM instance in another region without the use of ExpressRoute or a VPN gateway.
- Customers can allocate a maximum of two payment HSMs from each stamp in one region under same subscription.
- If customer does not have a High Availability setup in their production environment, the customer will not be able to receive S2 support from Microsoft side.
High availability deployment
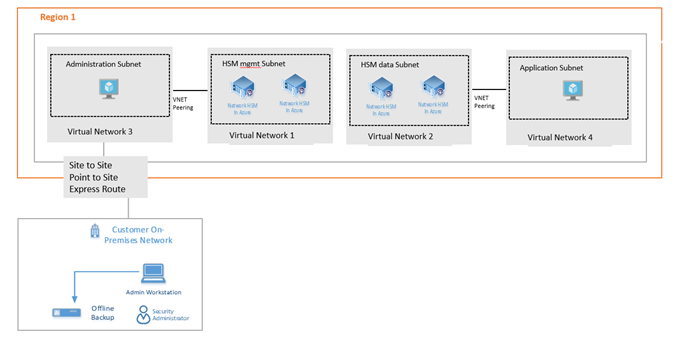
For High Availability, customer must allocate HSMs between stamp 1 and stamp 2 (in other words, no two HSMs from same stamp)
Disaster recovery deployment
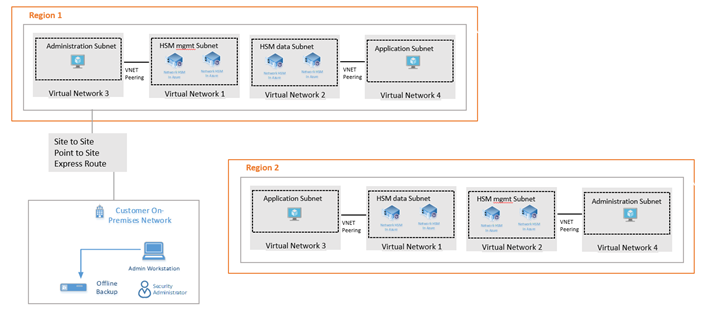
This scenario caters to regional-level failure. The usual strategy is to completely switch the application stack (and its HSMs), rather than trying to reach an HSM in Region 2 from application in Region 1 due to latency.
Next steps
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for