Create an Azure File Sync server endpoint
A server endpoint represents a specific location on a registered server, such as a folder on a server volume. A server endpoint must meet the following conditions:
- A server endpoint must be a path on a registered server (rather than a mounted share). Network attached storage (NAS) isn't supported.
- Although the server endpoint can be on the system volume, server endpoints on the system volume can't use cloud tiering.
- Changing the path or drive letter after you established a server endpoint on a volume isn't supported. Make sure you're using a suitable path before creating the server endpoint.
- A registered server can support multiple server endpoints, however, a sync group can only have one server endpoint per registered server at any given time. Other server endpoints within the sync group must be on different registered servers.
- Multiple server endpoints can exist on the same volume if their namespaces aren't overlapping (for example, F:\sync1 and F:\sync2) and each endpoint is syncing to a unique sync group.
This article helps you understand the options and decisions needed to create a new server endpoint and start sync. For this to work, you need to have finished planning for your Azure File Sync deployment and also have deployed resources needed in prior steps to create a server endpoint.
Prerequisites
To create a server endpoint, you must first ensure that the following criteria are met:
- The server has the Azure File Sync agent installed and has been registered. See Register/unregister a server with Azure File Sync for details on installing the Azure File Sync Agent.
- Ensure that a Storage Sync Service has been deployed. See How to deploy Azure File Sync for details on how to deploy a Storage Sync Service.
- Ensure that a sync group has been deployed. Learn how to Create a sync group.
- Ensure that the server is connected to the internet and that Azure is accessible. Azure File Sync uses port 443 for all communication between the server and cloud service.
Create a server endpoint
To add a server endpoint, go to the newly created sync group. Under Server endpoints, select +Add server endpoint. The Add server endpoint blade opens. Enter the following information to create a server endpoint:
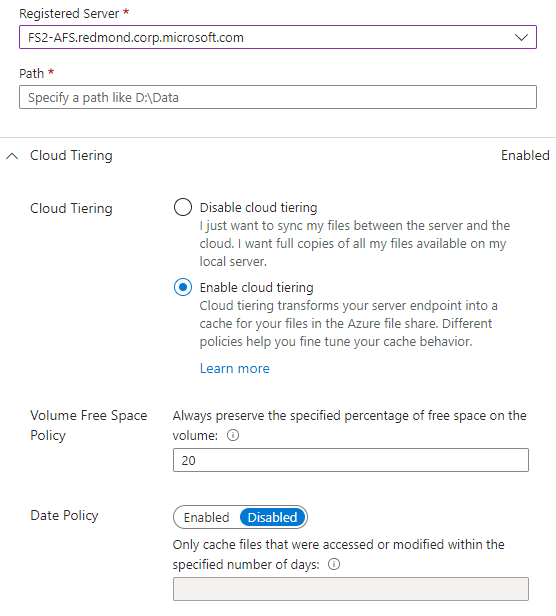
- Registered server: The name of the server or cluster where you want to create the server endpoint.
- Path: The path on the Windows Server to be synced to the Azure file share. The path can be a folder (for example, D:\Data), volume root (for example, D:\), or volume mount point (for example, D:\Mount).
- Cloud Tiering: A switch to enable or disable cloud tiering. With cloud tiering, infrequently used or accessed files can be tiered to Azure Files. When you enable cloud tiering, there are two policies that you can set to inform Azure File Sync when to tier cool files: the Volume Free Space Policy and the Date Policy.
- Volume Free Space: The amount of free space to reserve on the volume on which the server endpoint is located. For example, if volume free space is set to 50% on a volume that has only one server endpoint, roughly half the amount of data is tiered to Azure Files. Regardless of whether cloud tiering is enabled, your Azure file share always has a complete copy of the data in the sync group.
- Date Policy: Files are tiered to the cloud if they haven't been accessed (that is, read or written to) for the specified number of days. For example, if you noticed that files that have gone more than 15 days without being accessed are typically archival files, you should set your date policy to 15 days.
- Initial Sync: The Initial Sync section is available only for the first server endpoint in a sync group (section changes to Initial Download when creating more than one server endpoint in a sync group). Within the Initial Sync section, you can select the Initial Upload and Initial Download behavior.
Initial Upload: You can select how the server initially uploads the data to the Azure file share:
- Option #1: Merge the content of this server path with the content in the Azure file share. Files with the same name and path will lead to conflicts if their content is different. Both versions of those files will be stored next to each other. If your server path or Azure file share are empty, always choose this option.
- Option #2: Authoritatively overwrite files and folders in the Azure file share with content in this server’s path. This option avoids file conflicts.
To learn more, see Initial sync.
Initial Download: You can select how the server initially downloads the Azure file share data. This setting is important when the server is connecting to an Azure file share with files in it. "Namespace" stands for the file and folder structure without the file content. File content of "tiered files" is recalled from the cloud to the server by local access or policy.
- Option #1: Download the namespace first and then recall the file content, as much as will fit on the local disk.
- Option #2: Download the namespace only. The file content will be recalled when accessed.
- Option #3: Avoid tiered files. Files will only appear on the server once they're fully downloaded.
To learn more, see Initial download.
To add the server endpoint, select Create. Your files are now kept in sync across your Azure file share and Windows Server.
Cloud tiering section
When creating a new server endpoint, you can opt into the cloud tiering feature of Azure File Sync. The options in the Cloud tiering section can be changed later. However, different options in the following section are available based on having cloud tiering enabled or not for your new server endpoint.
Refer to the cloud tiering article that covers the basics, the policies, and best practices in detail.
Initial sync section
The Initial sync section is available only for the first server endpoint in a sync group. For any additional server endpoint, see the Initial download section.
There are two fundamentally different initial sync behaviors:
Merge
Authoritative upload
Merge is the standard option and selected by default. You should leave the selection on Merge unless for certain migration scenarios.
- When joining a server location, in most scenarios either the server location or the cloud share is empty. In these cases, Merge is the right behavior and will lead to expected results.
- When both locations contain files and folders, the namespaces will merge. If there are files or folder names on the server that also exist in the cloud share, there will be a sync conflict. Conflicts are automatically resolved.
Within the Merge option, there is a selection to be made for how content from the Azure file share will initially arrive on the server. This selection has no impact if the Azure file share is empty. You can find more details in the upcoming paragraph: Initial download
Authoritative upload is an initial sync option reserved for a specific migration scenario. Syncing the same server path that was also used to seed the cloud share with for instance Azure Data Box. In this case, the cloud and the server locations have mostly the same data but the server is slightly newer. Users kept making changes while Data Box was in transport. This migration scenario then calls for updating the cloud seamlessly with the changes on the server (newer) without producing any conflicts. So the server is the authority of the shape of the namespace and Data Box was used to avoid large-scale initial upload from the server. Server authoritative upload enables a zero-downtime adoption of the cloud, even when an offline data transport mechanism was used to seed the cloud storage.
A server endpoint can only succeed provisioning with the authoritative upload option, when the server location has data in it. This block is to protect from accidental misconfigurations. Authoritative upload works like RoboCopy /MIR. This mode mirrors source to target. The source is the AFS server and the target is the cloud share. Authoritative upload will shape the target in the image of the source.
- New or updated files and folders will be uploaded from the server.
- Files and folders that don't exist on the server (anymore) will be deleted from the cloud share.
- Metadata-only changes to files and folders on the server will be efficiently moved to the cloud share as metadata-only updates.
- Files and folders might exist on server and the cloud share. But some files or folders might have changed their parent directory on the server since the seeding of the Azure file share. These files and folders will be purged from the cloud share and uploaded again. Because of this, it's best to avoid restructuring your namespace at a larger scale during a migration.
Initial download section
The Initial download section is available for the second and any more server endpoints in a sync group. The first server endpoint in a sync group has extra options that relate to migration with Azure Data Box. These options don't apply if this server endpoint isn't the first one in your sync group.
Note
Selecting an initial download option has no impact if the Azure file share is empty.
As part of this section, a choice can be made for how content from the Azure file share will initially arrive on the server:

- Namespace only
Will bring only the file and folder structure from the Azure file share to the local server. None of the file content is downloaded. This option is the default if you previously enabled cloud tiering for this new server endpoint. - Namespace first, then content
For a faster availability of the data, your namespace is brought down first, independent of your cloud tiering setting. Once the namespace is available on the server, the file content is then recalled from the cloud to the server. Recall happens based on the last-modified timestamp on each file. If the free space on server volume is less than 10%, the remaining files will remain tiered files. This option is the default if you didn't turn on cloud tiering for this server endpoint. - Avoid tiered files
This option will download each file in its entirety before the file shows up in the folder on server. This option avoids a tiered file to ever exist on the server. A namespace item and file content are always present at the same time. Avoid this option if fast disaster recovery from the cloud is your reason for creating a server endpoint. If you have applications that require full files to be present and can't tolerate tiered files in their namespace, this is ideal. This option isn't available if you're using cloud tiering for your new server endpoint.
Once you select an initial download option, you can't change it after you confirm to create the server endpoint.
Note
When adding a server endpoint and files exist in the Azure file share, if you choose to download the namespace first, files will show up as tiered until they're downloaded locally. Files are downloaded using a single thread by default to limit network bandwidth usage. To improve the file download performance, use the Invoke-StorageSyncFileRecall cmdlet with a thread count greater than 1.
File download behavior once initial download completes
How files appear on the server after initial download finishes depends on your use of the cloud tiering feature and whether or not you opted to proactively recall changes in the cloud. The latter is a feature useful for sync groups with multiple server endpoints in different geographic locations.
- Cloud tiering is enabled
New and changed files from other server endpoints will appear as tiered files on this server endpoint. These changes will only come down as full files if you opted for proactive recall of changes in the Azure file share by other server endpoints. - Cloud tiering is disabled
New and changed files from other server endpoints will appear as full files on this server endpoint. They won't appear as tiered files first and then recalled. Tiered files with cloud tiering off are a fast disaster recovery feature and appear only during initial provisioning.
Provisioning steps
When a new server endpoint is created using the portal or PowerShell, the server endpoint isn't ready to be used immediately. Depending on how much data is present on the corresponding file share in the cloud, it might take few minutes to hours for the server endpoint to be functional and ready to use.
In the past, if you wanted to check the status of the server endpoint provisioning status and whether the server is ready for users to access data, you had to log in to the server endpoint and see if all the data had been downloaded. With provisioning steps, you can understand whether a server endpoint is ready to use or not and if the sync is fully functional directly from the Azure portal, in the server endpoint overview blade.
For supported scenarios, the Provisioning steps tab provides information on what's happening on the server endpoint, including when the server endpoint is ready for user access.
Supported scenarios
Currently, provisioning steps are only displayed when the new server endpoint being added has no data on the server path selected for the server endpoint. In other scenarios, the provisioning steps tab isn't available.
Provisioning status
Here are the different statuses that are displayed when server endpoint provisioning is in progress and what they mean:
- In progress: SEP isn't ready for user access.
- Ready (sync not functional): Users can access data, but changes won't sync to cloud file share.
- Ready (sync functional): Users can access data and changes will be synced to the cloud share making the endpoint fully functional.
- Failed: Provisioning failed because of an error.
The provisioning steps tab is only visible in the Azure portal for supported scenarios. It won't be available or visible for unsupported scenarios.
Next steps
There's more to discover about Azure file shares and Azure File Sync. The following articles will help you understand advanced options and best practices. They also provide help with troubleshooting. These articles contain links to the Azure file share documentation where appropriate.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for