Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Apache Spark is a parallel processing framework that supports in-memory processing to boost the performance of big-data analytic applications. Apache Spark in Azure Synapse Analytics is one of Microsoft's implementations of Apache Spark in the cloud.
Azure Synapse now offers the ability to create Azure Synapse GPU-enabled pools to run Spark workloads using underlying RAPIDS libraries that use the massive parallel processing power of GPUs to accelerate processing. The RAPIDS Accelerator for Apache Spark allows you to run your existing Spark applications without any code change by just enabling a configuration setting, which comes pre-configured for a GPU-enabled pool. You can choose to turn on/off the RAPIDS-based GPU acceleration for your workload or parts of your workload by setting this configuration:
spark.conf.set('spark.rapids.sql.enabled','true/false')
Note
The Preview for Azure Synapse GPU-enabled pools has now been deprecated.
RAPIDS Accelerator for Apache Spark
The Spark RAPIDS accelerator is a plugin that works by overriding the physical plan of a Spark job by supported GPU operations, and running those operations on the GPUs, thereby accelerating processing. This library is currently in preview and doesn't support all Spark operations (here is a list of currently supported operators, and more support is being added incrementally through new releases).
Cluster configuration options
The RAPIDS Accelerator plugin only supports a one-to-one mapping between GPUs and executors. This means a Spark job would need to request executor and driver resources that can be accommodated by the pool resources (according to the number of available GPU and CPU cores). In order to meet this condition and ensure optimal utilization of all the pool resources, we require the following configuration of drivers and executors for a Spark application running on GPU-enabled pools:
| Pool size | Driver size options | Driver cores | Driver Memory (GB) | Executor cores | Executor Memory (GB) | Number of Executors |
|---|---|---|---|---|---|---|
| GPU-Large | Small driver | 4 | 30 | 12 | 60 | Number of nodes in pool |
| GPU-Large | Medium driver | 7 | 30 | 9 | 60 | Number of nodes in pool |
| GPU-XLarge | Medium driver | 8 | 40 | 14 | 80 | 4 * Number of nodes in pool |
| GPU-XLarge | Large driver | 12 | 40 | 13 | 80 | 4 * Number of nodes in pool |
Any workload that does not meet one of the above configurations will not be accepted. This is done to make sure Spark jobs are being run with the most efficient and performant configuration utilizing all available resources on the pool.
The user can set the above configuration through their workload. For notebooks, the user can use the %%configure magic command to set one of the above configurations as shown below.
For example, using a large pool with three nodes:
%%configure -f
{
"driverMemory": "30g",
"driverCores": 4,
"executorMemory": "60g",
"executorCores": 12,
"numExecutors": 3
}
Run a sample Spark job through notebook on an Azure Synapse GPU-accelerated pool
It would be good to be familiar with the basic concepts of how to use a notebook in Azure Synapse Analytics before proceeding with this section. Let's walk through the steps to run a Spark application utilizing GPU acceleration. You can write a Spark application in all the four languages supported inside Synapse, PySpark (Python), Spark (Scala), SparkSQL, and .NET for Spark (C#).
Create a GPU-enabled pool.
Create a notebook and attach it to the GPU-enabled pool you created in the first step.
Set the configurations as explained in the previous section.
Create a sample dataframe by copying the below code in the first cell of your notebook:
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import org.apache.spark.sql.Row
import scala.collection.JavaConversions._
val schema = StructType( Array(
StructField("emp_id", IntegerType),
StructField("name", StringType),
StructField("emp_dept_id", IntegerType),
StructField("salary", IntegerType)
))
val emp = Seq(Row(1, "Smith", 10, 100000),
Row(2, "Rose", 20, 97600),
Row(3, "Williams", 20, 110000),
Row(4, "Jones", 10, 80000),
Row(5, "Brown", 40, 60000),
Row(6, "Brown", 30, 78000)
)
val empDF = spark.createDataFrame(emp, schema)
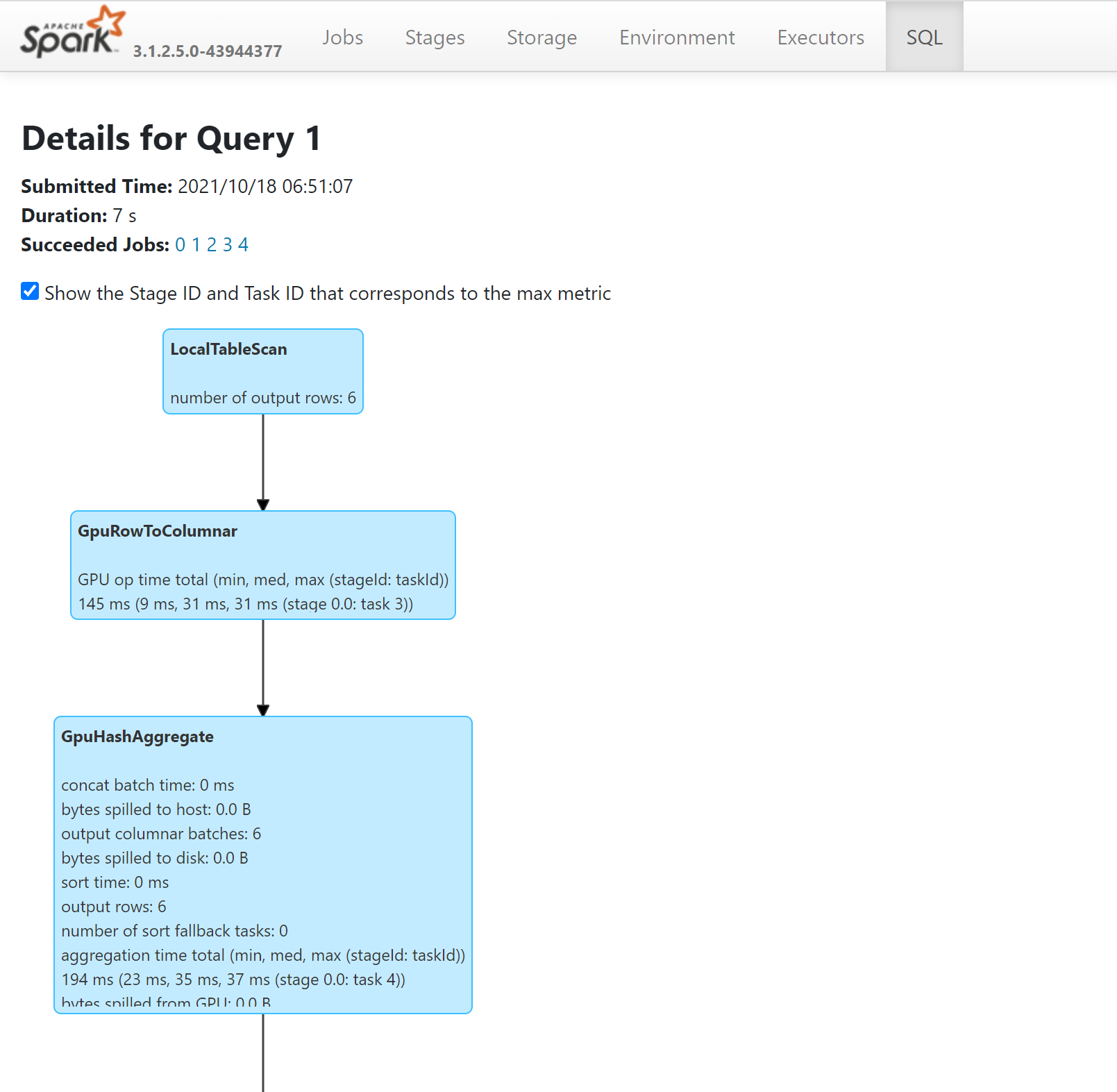
- Now let's do an aggregate by getting the maximum salary per department ID and display the result:
- You can see the operations in your query that ran on GPUs by looking into the SQL plan through the Spark History Server:
How to tune your application for GPUs
Most Spark jobs can see improved performance through tuning configuration settings from defaults, and the same holds true for jobs leveraging the RAPIDS accelerator plugin for Apache Spark.
Quotas and resource constraints in Azure Synapse GPU-enabled pools
Workspace level
Every Azure Synapse workspace comes with a default quota of 50 GPU vCores. In order to increase your quota of GPU cores, please submit a support request through the Azure portal.