Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Applies to: ✔️ Linux VMs
Azure is home for all Oracle workloads, including workloads that need to continue to run optimally in Azure with Oracle. If you have the Oracle Diagnostic Pack or the Automatic Workload Repository (AWR), you can gather data about your workloads. Use this data to assess the Oracle workload, size the resource needs, and migrate the workload to Azure. The various metrics provided by Oracle in these reports can provide an understanding of application performance and platform usage.
This article helps you to prepare an Oracle workload to run in Azure and explore the best architecture solutions to provide optimal cloud performance. The data provided by Oracle in the Statspack and even more so in its descendent, the AWR, assists you in developing clear expectations. These expectations include the limits of physical tuning through architecture, the advantages of logical tuning of database code, and the overall database design.
Differences between the two environments
When you're migrating on-premises applications to Azure, keep in mind a few important differences between the two environments.
One important difference is that in an Azure implementation, resources such as VMs, disks, and virtual networks are shared among other clients. In addition, resources can be throttled based on the requirements. Instead of focusing on avoiding failing, Azure focuses more on surviving the failure. The first approach tries to increase mean time between failures (MTBF) and the second tries to decrease mean time to recovery (MTTR).
The following table lists some of the differences between an on-premises implementation and an Azure implementation of an Oracle database.
| On-premises implementation | Azure implementation | |
|---|---|---|
| Networking | LAN/WAN | Software-defined networking (SDN) |
| Security group | IP/port restriction tools | Network security group (NSG) |
| Resilience | MTBF | MTTR |
| Planned maintenance | Patching/upgrades | Availability sets with patching/upgrades managed by Azure |
| Resource | Dedicated | Shared with other clients |
| Regions | Datacenters | Region pairs |
| Storage | SAN/physical disks | Azure-managed storage |
| Scale | Vertical scale | Horizontal scale |
Requirements
Consider the following requirements before you start your migration:
- Determine the real CPU usage. Oracle licenses by core, which means that sizing your vCPU needs can be essential to help you reduce costs.
- Determine the database size, backup storage, and growth rate.
- Determine the I/O requirements, which you can estimate based on Oracle Statspack and the AWR reports. You can also estimate the requirements from storage monitoring tools available from the operating system.
Configuration options
It's a good idea to generate an AWR report and obtain some metrics from it to help you make decisions about configuration. Then, there are four potential areas that you can tune to improve performance in an Azure environment:
- Virtual machine size
- Network throughput
- Disk types and configurations
- Disk cache settings
Generate an AWR report
If you have an existing an Oracle Enterprise Edition database and are planning to migrate to Azure, you have several options. If you have the Diagnostics Pack for your Oracle instances, you can run the Oracle AWR report to get the metrics, such as IOPS, Mbps, and GiBs. For those databases without the Diagnostics Pack license, or for an Oracle Standard Edition database, you can collect the same important metrics with a Statspack report after you collect manual snapshots. The main differences between these two reporting methods are that AWR is automatically collected, and that it provides more information about the database than does Statspack.
Consider running your AWR report during both regular and peak workloads, so you can compare. To collect the more accurate workload, consider an extended window report of one week, as opposed to one day. AWR provides averages as part of its calculations in the report. By default, the AWR repository retains eight days of data and takes snapshots at hourly intervals.
For a datacenter migration, you should gather reports for sizing on the production systems. Estimate remaining database copies used for user testing, test, and development by percentages. For example, estimate 50 percent of production sizing.
To run an AWR report from the command line, use the following command:
sqlplus / as sysdba
@$ORACLE_HOME/rdbms/admin/awrrpt.sql;
Key metrics
The report prompts you for the following information:
- Report type: HTML or TEXT. The HTML type provides more information.
- The number of days of snapshots to display. For example, for one-hour intervals, a one-week report produces 168 snapshot IDs.
- The beginning
SnapshotIDfor the report window. - The ending
SnapshotIDfor the report window. - The name of the report that the AWR script creates.
If you're running the AWR report on a Real Application Cluster (RAC), the command-line report is the awrgrpt.sql file, instead of awrrpt.sql. The g report creates a report for all nodes in the RAC database in a single report. This report eliminates the need to run one report on each RAC node.
You can obtain the following metrics from the AWR report:
- Database name, instance name, and host name
- Database version for supportability by Oracle
- CPU/Cores
- SGA/PGA, and advisors to let you know if undersized
- Total memory in GB
- CPU percentage busy
- DB CPUs
- IOPs (read/write)
- MBPs (read/write)
- Network throughput
- Network latency rate (low/high)
- Top wait events
- Parameter settings for database
- Whether the database is RAC, Exadata, or using advanced features or configurations
Virtual machine size
Here are some steps you can take to configure virtual machine size for optimal performance.
Estimate VM size based on CPU, memory, and I/O usage from the AWR report
Look at the top five timed foreground events that indicate where the system bottlenecks are. For example, in the following diagram, the log file sync is at the top. It indicates the number of waits that is required before the log writer writes the log buffer to the redo log file. These results indicate that better performing storage or disks are required. In addition, the diagram also shows the number of CPU cores and the amount of memory.
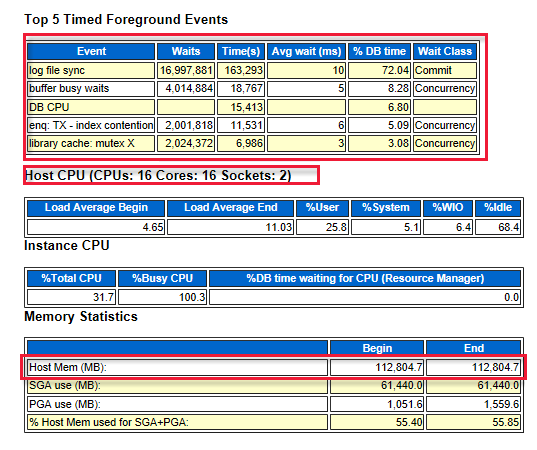
The following diagram shows the total I/O of read and write. There were 59 GB read and 247.3 GB written during the time of the report.

Choose a VM
Based on the information that you collected from the AWR report, the next step is to choose a VM of a similar size that meets your requirements. For more information about available VMs, see Memory optimized virtual machine sizes.
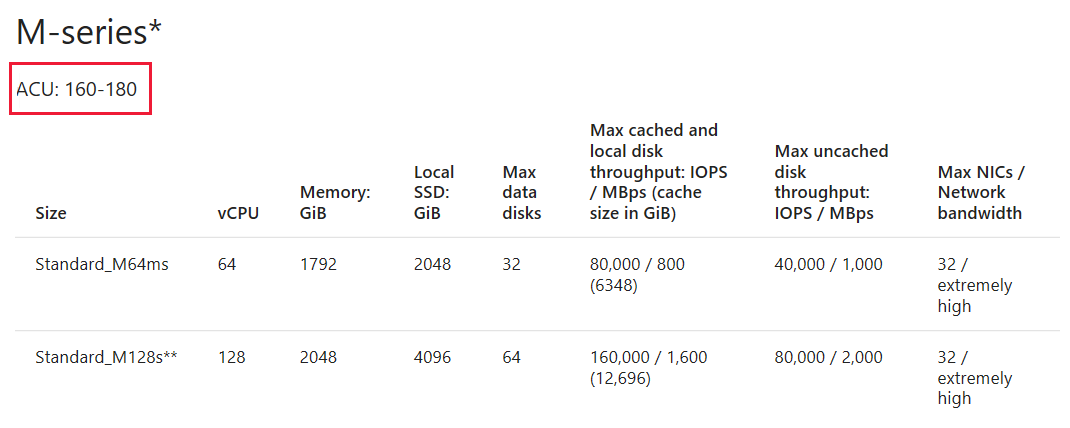
Fine-tune the VM sizing with a similar VM series based on the ACU
After you choose the VM, pay attention to the Azure compute unit (ACU) for the VM. You might choose a different VM based on the ACU value that better suits your requirements. For more information, see Azure compute unit.
Network throughput
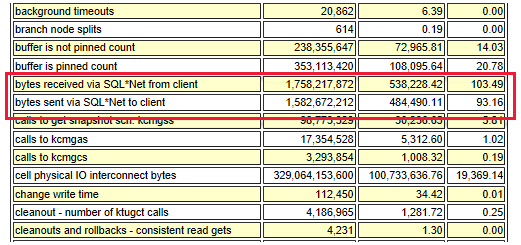
The following diagram shows the relation between throughput and IOPS:

The total network throughput is estimated based on the following information:
- SQL*Net traffic
- MBps times the number of servers (outbound stream, such as Oracle Data Guard)
- Other factors, such as application replication
Based on your network bandwidth requirements, there are various gateway types for you to choose from. These types include basic, VpnGw, and Azure ExpressRoute. For more information, see VPN Gateway pricing.
Recommendations
- Network latency is higher compared to an on-premises deployment. Reducing network round trips can greatly improve performance.
- To reduce round-trips, consolidate applications that have high transactions or chatty apps on the same virtual machine.
- Use virtual machines with accelerated networking for better network performance.
- For certain Linux distributions, consider enabling TRIM/UNMAP support.
- Install Oracle Enterprise Manager on a separate virtual machine.
- Huge pages aren't enabled on Linux by default. Consider enabling huge pages, and set
use_large_pages = ONLYon the Oracle DB. This approach might help increase performance. For more information, see USE_LARGE_PAGES.
Disk types and configurations
Here are some tips as you consider disks.
Default OS disks: These disk types offer persistent data and caching. They're optimized for operating system access at startup, and aren't designed for either transactional or data warehouse (analytical) workloads.
Managed disks: Azure manages the storage accounts that you use for your VM disks. You specify the disk type and the size of the disk that you need. The type is most often Premium (SSD) for Oracle workloads. Azure creates and manages the disk for you. A premium SSD-managed disk is only available for memory-optimized and designed VM series. After you choose a particular VM size, the menu shows only the available premium storage SKUs that are based on that VM size.


After you configure your storage on a VM, you might want to load test the disks before you create a database. Knowing the I/O rate in terms of both latency and throughput can help you determine if the VMs support the expected throughput with latency targets. There are several tools for application load testing, such as Oracle Orion, Sysbench, SLOB, and Fio.
Run the load test again after you deploy an Oracle database. Start your regular and peak workloads, and the results show you the baseline of your environment. Be realistic in the workload test. It doesn't make sense to run a workload that is nothing like what you run on the VM in reality.
Because Oracle can be an I/O intensive database, it's important to size the storage based on the IOPS rate rather than the storage size. For example, if the required IOPS value is 5,000, but you only need 200 GB, you might still get the P30 class premium disk even though it comes with more than 200 GB of storage.
You can get the IOPS rate from the AWR report. The redo log, physical reads, and writes rate determine the IOPS rate. Always verify that the VM series you choose has the ability to handle the I/O demand of the workload. If the VM has a lower I/O limit than the storage, the VM sets the limit maximum.
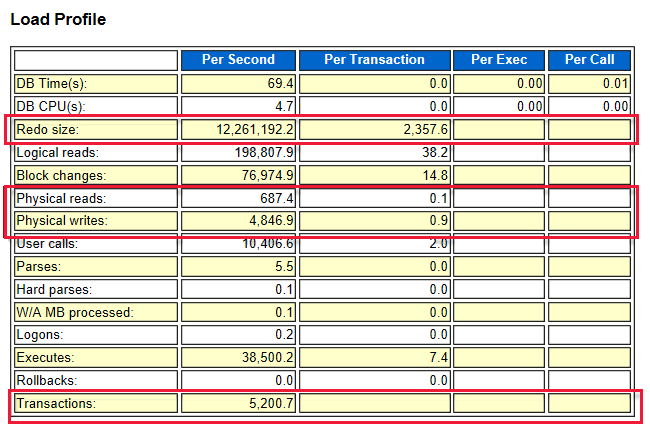
For example, the redo size is 12,200,000 bytes per second, which is equal to 11.63 MBPs. The IOPS value is 12,200,000 / 2,358 = 5,174.
After you have a clear picture of the I/O requirements, you can choose a combination of drives that are best suited to meet those requirements.
Disk type recommendations
- For data tablespace, spread the I/O workload across several disks by using managed storage or Oracle Automatic Storage Management (ASM).
- Use Oracle advanced compression to reduce I/O for both data and indexes.
- Separate redo logs, temp, and undo tablespaces on separate data disks.
- Don't put any application files on default operating system disks. These disks aren't optimized for fast VM boot times, and they might not provide good performance for your application.
- When you're using M-Series VMs on premium storage, enable write accelerator on the redo logs disk.
- Consider moving redo logs with high latency to the ultra disk.
Disk cache settings
Although you have three options for host caching, only read-only caching is recommended for a database workload on an Oracle database. Read/write can introduce significant vulnerabilities to a data file, because the goal of a database write is to record it to the data file, not to cache the information. With read-only, all requests are cached for future reads. All writes continue to be written to disk.
Disk cache recommendations
To maximize throughput, start with read-only for host caching whenever possible. For premium storage, keep in mind that you must disable the barriers when you mount the file system with the read-only options. Update the /etc/fstab file with the universally unique identifier to the disks.

- For operating system disks, use premium SSD with read-write host caching.
- For data disks that contain the following, use premium SSD with read-only host caching: Oracle data files, temp files, control files, block change tracking files, BFILEs, files for external tables, and flashback logs.
- For data disks that contain Oracle online redo log files, use premium SSD or UltraDisk with no host caching, the None option. Oracle redo log files that are archived and Oracle Recovery Manager backup sets, can also reside with the online redo log files. Host caching is limited to 4,095 GiB, so don't allocate a premium SSD larger than P50 with host caching. If you need more than 4 TiB of storage, stripe several premium SSDs with RAID-0. Use Linux LVM2 or Oracle Automatic Storage Management.
If workloads vary greatly between the day and evening, and the I/O workload can support it, P1-P20 premium SSD with bursting might provide the performance required during night-time batch loads or limited I/O demands.
Security
After you set up and configure your Azure environment, you need to secure your network. Here are some recommendations:
NSG policy: You can define your NSG by a subnet or a network interface card. It's simpler to control access at the subnet level, both for security and for force-routing application firewalls.
Jumpbox: For more secure access, administrators shouldn't directly connect to the application service or database. Use a jumpbox between the administrator machine and Azure resources.
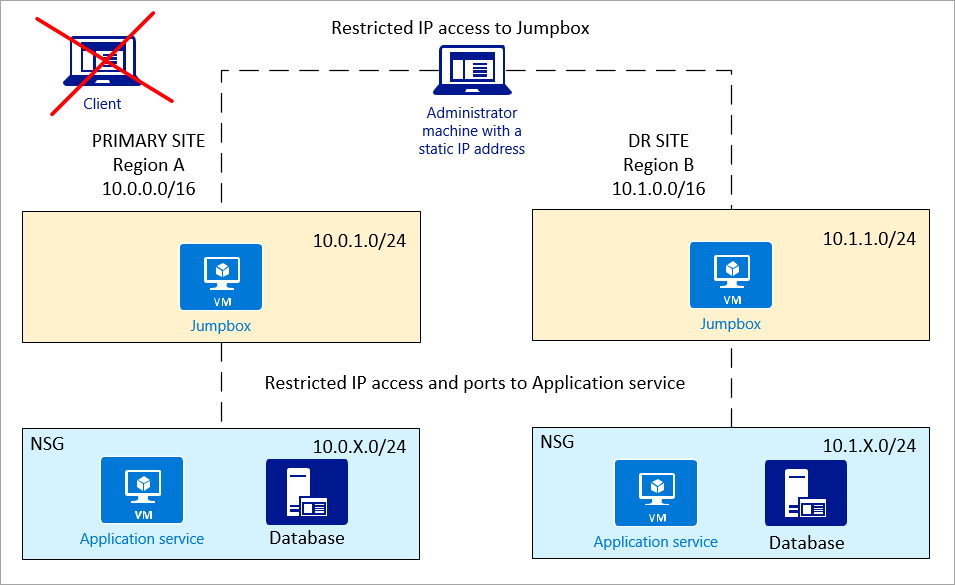
The administrator machine should only offer IP-restricted access to the jumpbox. The jumpbox should have access to the application and database.
Private network (subnets): It's a good idea to have the application service and database on separate subnets, so that NSG policy can set better control.

Resources
- Configure Oracle ASM
- Configure Oracle Data Guard
- Configure Oracle GoldenGate
- Oracle backup and recovery