Architecture pattern for mission-critical workloads on Azure
2025-05-06
This article presents a key pattern for mission-critical architectures on Azure. Apply this pattern when you start your design process, and then select components that are best suited for your business requirements. The article recommends a north star design approach and includes other examples with common technology components.
We recommend that you evaluate the key design areas, define the critical user and system flows that use the underlying components, and develop a matrix of Azure resources and their configuration while keeping in mind the following characteristics.
Characteristic
Considerations
Lifetime
What's the expected lifetime of the resource, relative to other resources in the solution? Should the resource outlive or share the lifetime with the entire system or region, or should it be temporary?
State
What impact will the persisted state at this layer have on reliability or manageability?
Reach
Is the resource required to be globally distributed? Can the resource communicate with other resources, located globally or within that region?
Dependencies
What are the dependencies on other resources?
Scale limits
What is the expected throughput for that resource? How much scale is provided by the resource to fit that demand?
Availability/disaster recovery
What is the impact on availability from a disaster at this layer? Would it cause a systemic outage or only a localized capacity or availability issue?
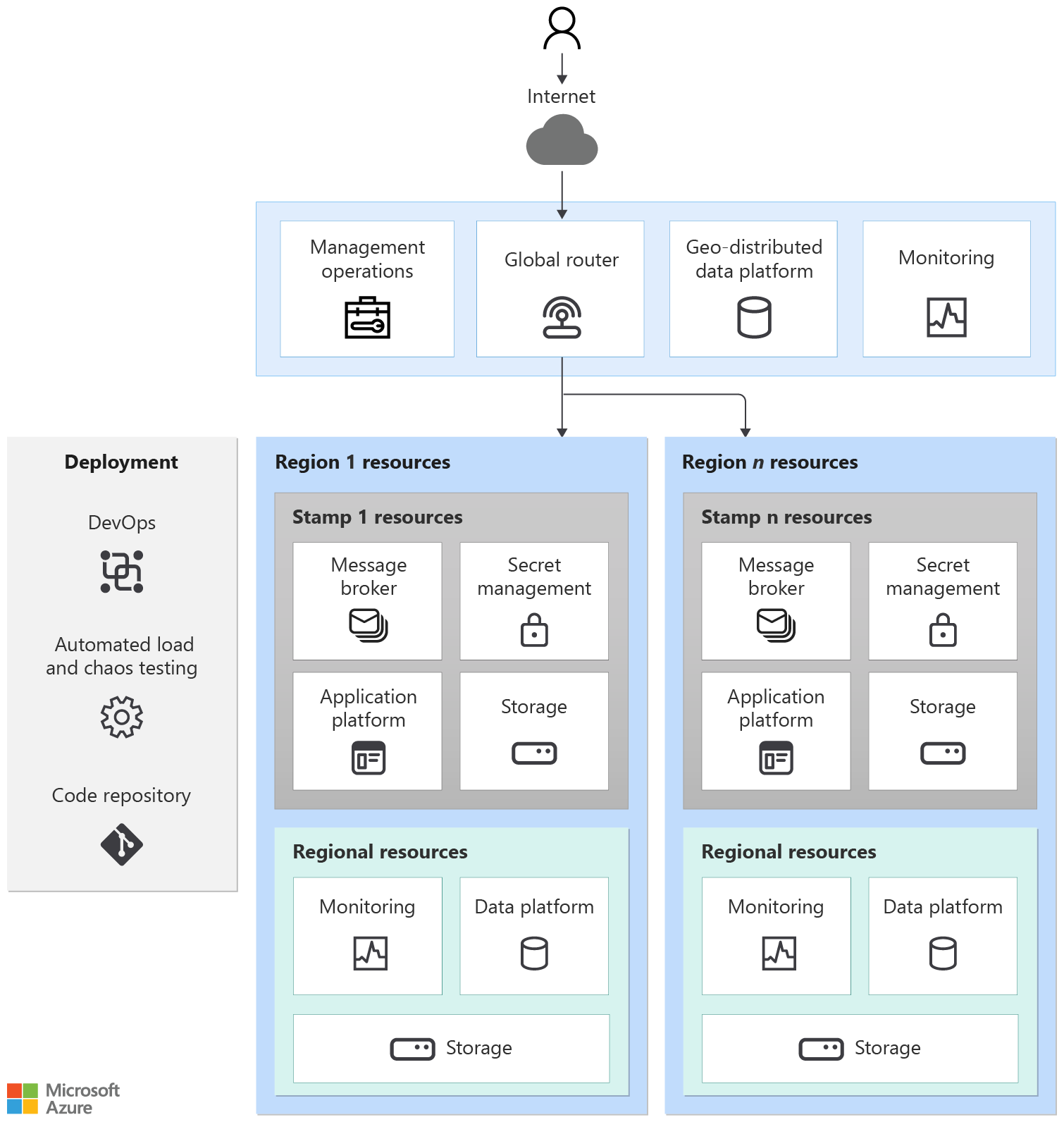
Based on the preceding characteristics, classify and identify mission-critical resources. That activity can help track resource utilization and associated costs, while helping you focus optimization efforts where they matter most. We recommend that you tag groups of resources deemed critical to your business. Keep in mind that some of these resources may be shared across multiple workloads.
Certain resources are globally shared by resources deployed within each region. Common examples are resources that are used to distribute traffic across multiple regions, store permanent state for the whole application, and monitor resources for them.
Characteristic
Considerations
Lifetime
These resources are expected to be long living (non-ephemeral). Their lifetime spans the life of the system or longer. Often the resources are managed with in-place data and control plane updates, assuming they support zero-downtime update operations.
State
Because these resources exist for at least the lifetime of the system, this layer is often responsible for storing global, geo-replicated state.
Reach
The resources should be globally distributed and replicated to the regions that host those resources. It’s recommended that these resources communicate with regional or other resources with low latency and the desired consistency.
Dependencies
The resources should avoid dependencies on regional resources because their unavailability can be a cause for global failure. For example, certificates or secrets kept in a single vault could have global impact if there's a regional failure where the vault is located.
Scale limits
Often these resources are singleton instances in the system, and they should be able to scale such that they can handle throughput of the system as a whole.
Availability/disaster recovery
Regional and stamp resources can use global resources. It's critical that global resources are configured with high availability and disaster recovery for the health of the whole system.
Regional stamp resources
The stamp contains the application and resources that participate in completing business transactions. A stamp typically corresponds to a deployment to an Azure region. Although a region can have more than one stamp.
Characteristic
Considerations
Lifetime
The resources are expected to have a short life span (ephemeral) with the intent that they can get added and removed dynamically while regional resources outside the stamp continue to persist. The ephemeral nature is needed to provide more resiliency, scale, and proximity to users.
State
Because stamps are ephemeral and will be destroyed with each deployment, a stamp should be stateless as much as possible.
Reach
Can communicate with regional and global resources. However, communication with other regions or other stamps should be avoided.
Dependencies
The stamp resources must be independent. They're expected to have regional and global dependencies but shouldn't rely on components in other stamps in the same or other regions.
Scale limits
Throughput is established through testing. The throughput of the overall stamp is limited to the least performant resource. Stamp throughput needs to estimate the high-level of demand caused by a failover to another stamp.
Availability/disaster recovery
Because of the temporary nature of stamps, disaster recovery is done by redeploying the stamp. If resources are in an unhealthy state, the stamp, as a whole, can be destroyed and redeployed.
Regional resources
A system can have resources that are deployed in region but outlive the stamp resources. For example, observability resources that monitor resources at the regional level, including the stamps.
Characteristic
Consideration
Lifetime
The resources share the lifetime of the region and out live the stamp resources.
State
State stored in a region can't live beyond the lifetime of the region. If state needs to be shared across regions, consider using a global data store.
Reach
The resources don't need to be globally distributed. Direct communication with other regions should be avoided at all cost.
Dependencies
The resources can have dependencies on global resources, but not on stamp resources because stamps are meant to be short lived.
Scale limits
Determine the scale limit of regional resources by combining all stamps within the region.
Baseline architectures for mission-critical workloads
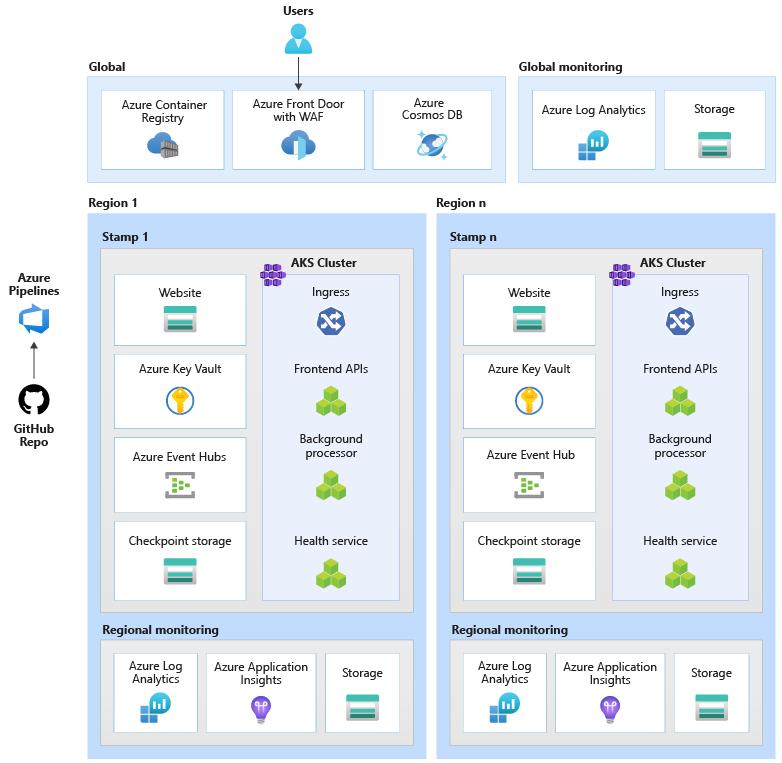
These baseline examples serve as the recommended north star architecture for mission-critical applications. The baseline strongly recommends containerization and using a container orchestrator for the application platform. The baseline uses Azure Kubernetes Service (AKS).
If you're just starting your mission-critical journey, use this architecture as a reference. The workload is accessed over a public endpoint and doesn't require private network connectivity to other company resources.
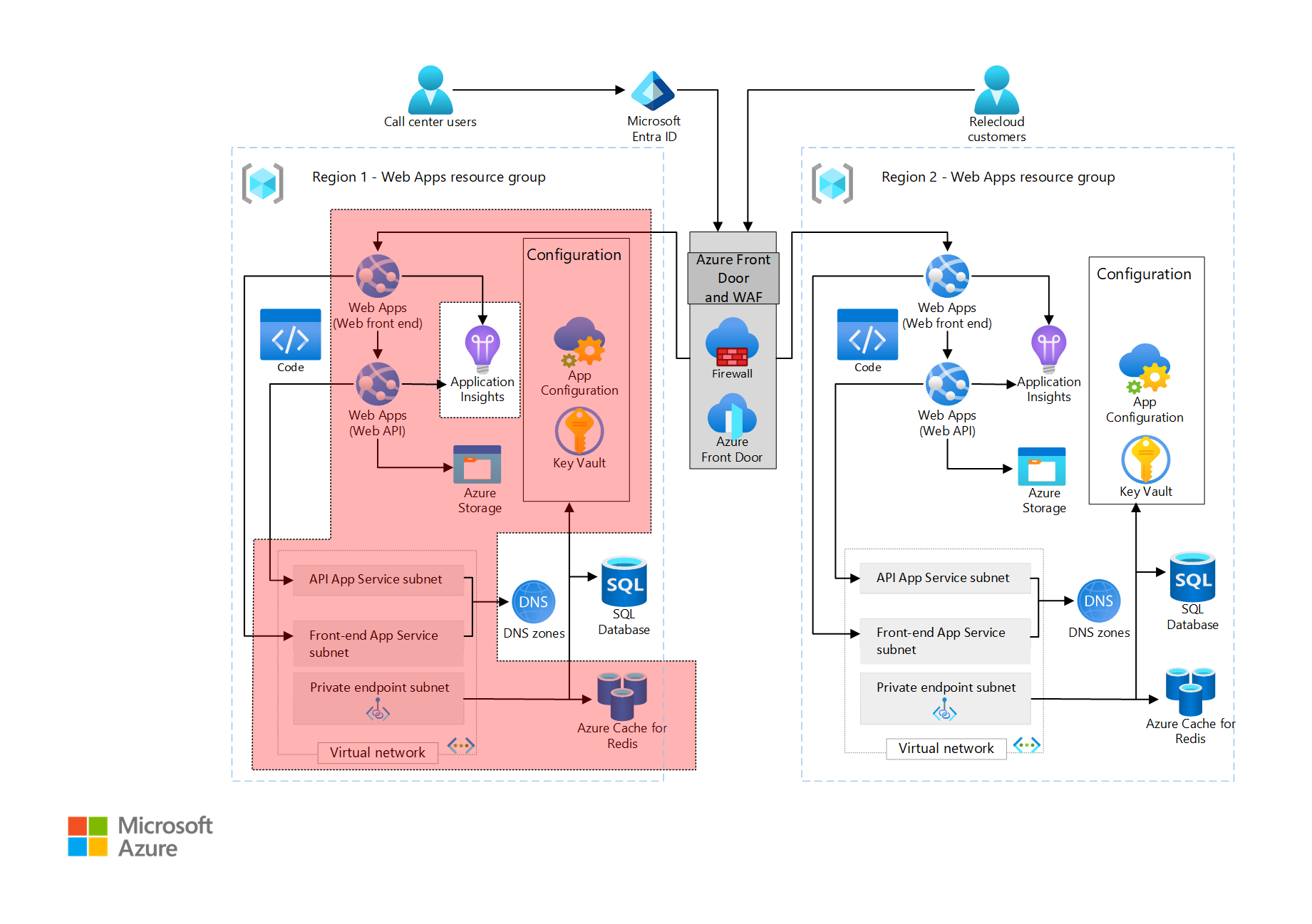
Baseline with network controls
This architecture builds on the baseline architecture. The design is extended to provide strict network controls to prevent unauthorized public access from the internet to the workload resources.
Baseline in Azure landing zones
This architecture is appropriate if you're deploying the workload in an enterprise setup where integration within a broader organization is required. The workload uses centralized shared services, needs on-premises connectivity, and integrates with other workloads within the enterprise. It's deployed in an Azure landing zone subscription that inherits from the Corp. management group.
Baseline with App Services
This architecture extends the baseline reference by considering App Services as the primary application hosting technology, providing an easy to use environment for container deployments.
Design areas
We recommend that you use the provided design guidance to navigate the key design decisions to reach an optimal solution. For information, see What are the key design areas?
Next step
Review the best practices for designing mission-critical application scenarios.