Application platform considerations for mission-critical workloads on Azure
Azure provides many compute services for hosting highly available applications. The services differ in capability and complexity. We recommend that you choose services based on:
- Non-functional requirements for reliability, availability, performance, and security.
- Decision factors like scalability, cost, operability, and complexity.
The choice of an application hosting platform is a critical decision that affects all other design areas. For example, legacy or proprietary development software might not run in PaaS services or containerized applications. This limitation would influence your choice of compute platform.
A mission-critical application can use more than one compute service to support multiple composite workloads and microservices, each with distinct requirements.
This design area provides recommendations related to compute selection, design, and configuration options. We also recommend that you familiarize yourself with the Compute decision tree.
Important
This article is part of the Azure Well-Architected Framework mission-critical workload series. If you aren't familiar with this series, we recommend that you start with What is a mission-critical workload?.
Global distribution of platform resources
A typical pattern for a mission-critical workload includes global resources and regional resources.
Azure services, which aren't constrained to a particular Azure region, are deployed or configured as global resources. Some use cases include distributing traffic across multiple regions, storing permanent state for a whole application, and caching global static data. If you need to accommodate both a scale-unit architecture and global distribution, consider how resources are optimally distributed or replicated across Azure regions.
Other resources are deployed regionally. These resources, which are deployed as part of a deployment stamp, typically correspond to a scale unit. However, a region can have more than one stamp, and a stamp can have more than one unit. The reliability of regional resources is crucial because they're responsible for running the main workload.
The following image shows the high-level design. A user accesses the application via a central global entry point that then redirects requests to a suitable regional deployment stamp:
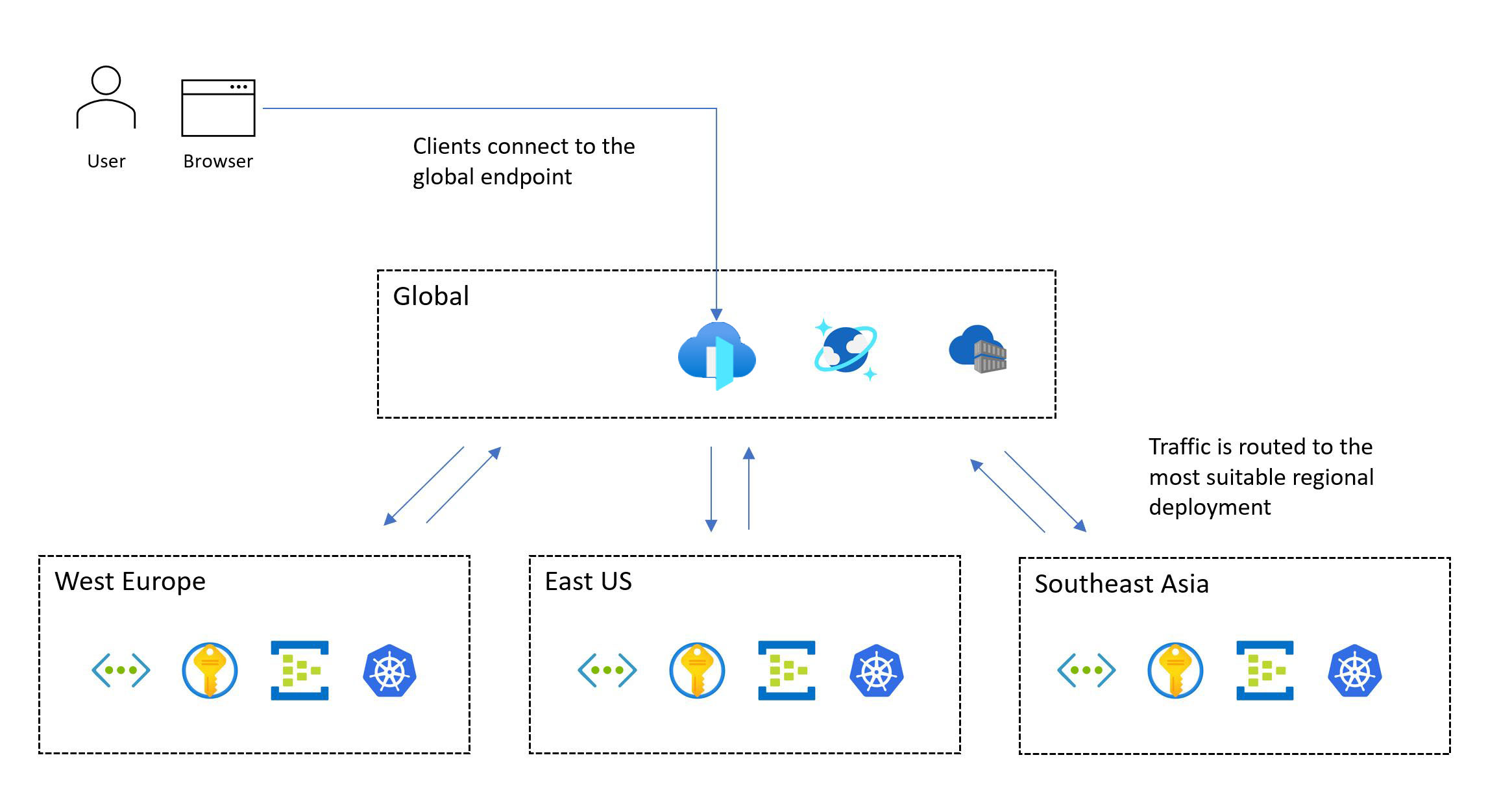
The mission-critical design methodology requires a multi-region deployment. This model ensures regional fault tolerance, so that the application remains available even when an entire region goes down. When you design a multi-region application, consider different deployment strategies, like active/active and active/passive, together with application requirements, because there are significant trade-offs for each approach. For mission-critical workloads, we strongly recommend the active/active model.
Not every workload supports or requires running multiple regions simultaneously. You should weigh specific application requirements against trade-offs to determine an optimal design decision. For certain application scenarios that have lower reliability targets, active/passive or sharding can be suitable alternatives.
Availability zones can provide highly available regional deployments across different datacenters within a region. Nearly all Azure services are available in either a zonal configuration, where the service is delegated to a specific zone, or a zone-redundant configuration, where the platform automatically ensures that the service spans across zones and can withstand a zone outage. These configurations provide fault tolerance up to the datacenter level.
Design considerations
Regional and zonal capabilities. Not all services and capabilities are available in every Azure region. This consideration could affect the regions you choose. Also, availability zones aren't available in every region.
Regional pairs. Azure regions are grouped into regional pairs that consist of two regions in a single geography. Some Azure services use paired regions to ensure business continuity and to provide a level of protection against data loss. For example, Azure geo-redundant storage (GRS) replicates data to a secondary paired region automatically, ensuring that data is durable if the primary region isn't recoverable. If an outage affects multiple Azure regions, at least one region in each pair is prioritized for recovery.
Data consistency. For consistency challenges, consider using a globally distributed data store, a stamped regional architecture, and a partially active/active deployment. In a partial deployment, some components are active across all regions while others are located centrally within the primary region.
Safe deployment. The Azure safe deployment practice (SDP) framework ensures that all code and configuration changes (planned maintenance) to the Azure platform undergo a phased rollout. Health is analyzed for degradation during the release. After canary and pilot phases complete successfully, platform updates are serialized across regional pairs, so only one region in each pair is updated at a given time.
Platform capacity. Like any cloud provider, Azure has finite resources. Unavailability can be the result of capacity limitations in regions. If there's a regional outage, there's an increase in demand for resources as the workload attempts to recover within the paired region. The outage might create a capacity problem, where supply temporarily doesn't meet demand.
Design recommendations
Deploy your solution in at least two Azure regions to help protect against regional outages. Deploy it in regions that have the capabilities and characteristics that the workload requires. The capabilities should meet performance and availability targets while fulfilling data residency and retention requirements.
For example, some data compliance requirements might constrain the number of available regions and potentially force design compromises. In such cases, we strongly recommend that you add extra investment in operational wrappers to predict, detect, and respond to failures. Suppose you're constrained to a geography with two regions, and only one of those regions supports availability zones (3 + 1 datacenter model). Create a secondary deployment pattern using fault domain isolation to allow both regions to be deployed in an active configuration, and ensure that the primary region houses multiple deployment stamps.
If suitable Azure regions don't all offer capabilities that you need, be prepared to compromise on the consistency of regional deployment stamps to prioritize geographical distribution and maximize reliability. If only a single Azure region is suitable, deploy multiple deployment stamps (regional scale units) in the selected region to mitigate some risk, and use availability zones to provide datacenter-level fault tolerance. However, such a significant compromise in geographical distribution dramatically constrains the attainable composite SLA and overall reliability.
Important
For scenarios that target an SLO that's greater than or equal to 99.99%, we recommend a minimum of three deployment regions to maximize the composite SLA and overall reliability. Calculate the composite SLA for all user flows. Ensure that the composite SLA is aligned with business targets.
For high-scale application scenarios that have significant volumes of traffic, design the solution to scale across multiple regions to navigate potential capacity constraints within a single region. Additional regional deployment stamps will achieve a higher composite SLA. Using global resources constrains the increase in composite SLA that you achieve by adding more regions.
Define and validate your recovery point objectives (RPO) and recovery time objectives (RTO).
Within a single geography, prioritize the use of regional pairs to benefit from SDP serialized rollouts for planned maintenance and regional prioritization for unplanned maintenance.
Geographically colocate Azure resources with users to minimize network latency and maximize end-to-end performance.
- You can also use solutions like a Content Delivery Network (CDN) or edge caching to drive optimal network latency for distributed user bases. For more information, see Global traffic routing, Application delivery services, and Caching and static content delivery.
Align current service availability with product roadmaps when you choose deployment regions. Some services might not be immediately available in every region.
Containerization
A container includes application code and the related configuration files, libraries, and dependencies that the application needs to run. Containerization provides an abstraction layer for application code and its dependencies and creates separation from the underlying hosting platform. The single software package is highly portable and can run consistently across various infrastructure platforms and cloud providers. Developers don't need to rewrite code and can deploy applications faster and more reliably.
Important
We recommend that you use containers for mission-critical application packages. They improve infrastructure utilization because you can host multiple containers on the same virtualized infrastructure. Also, because all software is included in the container, you can move the application across various operating systems, regardless of runtimes or library versions. Management is also easier with containers than it is with traditional virtualized hosting.
Mission-critical applications need to scale fast to avoid performance bottlenecks. Because container images are pre-built, you can limit startup to occur only during bootstrapping of the application, which provides rapid scalability.
Design considerations
Monitoring. It can be difficult for monitoring services to access applications that are in containers. You typically need third-party software to collect and store container state indicators like CPU or RAM usage.
Security. The hosting platform OS kernel is shared across multiple containers, creating a single point of attack. However, the risk of host VM access is limited because containers are isolated from the underlying operating system.
State. Although it's possible to store data in a running container's file system, the data won't persist when the container is re-created. Instead, persist data by mounting external storage or using an external database.
Design recommendations
Containerize all application components. Use container images as the primary model for application deployment packages.
Prioritize Linux-based container runtimes when possible. The images are more lightweight, and new features for Linux nodes/containers are released frequently.
Make containers immutable and replaceable, with short lifecycles.
Be sure to gather all relevant logs and metrics from the container, container host, and underlying cluster. Send the gathered logs and metrics to a unified data sink for further processing and analysis.
Store container images in Azure Container Registry. Use geo-replication to replicate container images across all regions. Enable Microsoft Defender for container registries to provide vulnerability scanning for container images. Make sure access to the registry is managed by Microsoft Entra ID.
Container hosting and orchestration
Several Azure application platforms can effectively host containers. There are advantages and disadvantages associated with each of these platforms. Compare the options in the context of your business requirements. However, always optimize reliability, scalability, and performance. For more information, see these articles:
Important
Azure Kubernetes Service (AKS) and Azure Container Apps should be among your first choices for container management depending on your requirements. Although Azure App Service isn't an orchestrator, as a low-friction container platform, it's still a feasible alternative to AKS.
Design considerations and recommendations for Azure Kubernetes Service
AKS, a managed Kubernetes service, enables quick cluster provisioning without requiring complex cluster administration activities and offers a feature set that includes advanced networking and identity capabilities. For a complete set of recommendations, see Azure Well-Architected Framework review - AKS.
Important
There are some foundational configuration decisions that you can't change without re-deploying the AKS cluster. Examples include the choice between public and private AKS clusters, enabling Azure Network Policy, Microsoft Entra integration, and the use of managed identities for AKS instead of service principals.
Reliability
AKS manages the native Kubernetes control plane. If the control plane isn't available, the workload experiences downtime. Take advantage of the reliability features offered by AKS:
Deploy AKS clusters across different Azure regions as a scale unit to maximize reliability and availability. Use availability zones to maximize resilience within an Azure region by distributing AKS control plane and agent nodes across physically separate datacenters. However, if colocation latency is a problem, you can do AKS deployment within a single zone or use proximity placement groups to minimize internode latency.
Use the AKS Uptime SLA for production clusters to maximize Kubernetes API endpoint availability guarantees.
Scalability
Take into account AKS scale limits, like the number of nodes, node pools per cluster, and clusters per subscription.
If scale limits are a constraint, take advantage of the scale-unit strategy, and deploy more units with clusters.
Enable cluster autoscaler to automatically adjust the number of agent nodes in response to resource constraints.
Use the horizontal pod autoscaler to adjust the number of pods in a deployment based on CPU utilization or other metrics.
For high scale and burst scenarios, consider using virtual nodes for extensive and rapid scale.
Define pod resource requests and limits in application deployment manifests. If you don't, you might experience performance problems.
Isolation
Maintain boundaries between the infrastructure used by the workload and system tools. Sharing infrastructure might lead to high-resource utilization and noisy neighbor scenarios.
Use separate node pools for system and workload services. Dedicated node pools for workload components should be based on requirements for specialized infrastructure resources like high-memory GPU VMs. In general, to reduce unnecessary management overhead, avoid deploying large numbers of node pools.
Use taints and tolerations to provide dedicated nodes and limit resource-intensive applications.
Evaluate application affinity and anti-affinity requirements and configure the appropriate colocation of containers on nodes.
Security
Default vanilla Kubernetes requires significant configuration to ensure a suitable security posture for mission-critical scenarios. AKS addresses various security risks out of the box. Features include private clusters, auditing and logging into Log Analytics, hardened node images, and managed identities.
Apply configuration guidance provided in the AKS security baseline.
Use AKS features for handling cluster identity and access management to reduce operational overhead and apply consistent access management.
Use managed identities instead of service principals to avoid management and rotation of credentials. You can add managed identities at the cluster level. At the pod level, you can use managed identities via Microsoft Entra Workload ID.
Use Microsoft Entra integration for centralized account management and passwords, application access management, and enhanced identity protection. Use Kubernetes RBAC with Microsoft Entra ID for least privilege, and minimize granting administrator privileges to help protect configuration and secrets access. Also, limit access to the Kubernetes cluster configuration file by using Azure role-based access control. Limit access to actions that containers can perform, provide the least number of permissions, and avoid the use of root privilege escalation.
Upgrades
Clusters and nodes need to be upgraded regularly. AKS supports Kubernetes versions in alignment with the release cycle of native Kubernetes.
Subscribe to the public AKS Roadmap and Release Notes on GitHub to stay up-to-date on upcoming changes, improvements, and, most importantly, Kubernetes version releases and deprecations.
Apply the guidance provided in the AKS checklist to ensure alignment with best practices.
Be aware of the various methods supported by AKS for updating nodes and/or clusters. These methods can be manual or automated. You can use Planned Maintenance to define maintenance windows for these operations. New images are released weekly. AKS also supports auto-upgrade channels for automatically upgrading AKS clusters to newer versions of Kubernetes and/or newer node images when they're available.
Networking
Evaluate the network plugins that best fit your use case. Determine whether you need granular control of traffic between pods. Azure supports kubenet, Azure CNI, and bring your own CNI for specific use cases.
Prioritize the use of Azure CNI after assessing network requirements and the size of the cluster. Azure CNI enables the use of Azure or Calico network policies for controlling traffic within the cluster.
Monitoring
Your monitoring tools should be able to capture logs and metrics from running pods. You should also gather information from the Kubernetes Metrics API to monitor the health of running resources and workloads.
Use Azure Monitor and Application Insights to collect metrics, logs, and diagnostics from AKS resources for troubleshooting.
Enable and review Kubernetes resource logs.
Configure Prometheus metrics in Azure Monitor. Container insights in Monitor provides onboarding, enables monitoring capabilities out of the box, and enables more advanced capabilities via built-in Prometheus support.
Governance
Use policies to apply centralized safeguards to AKS clusters in a consistent way. Apply policy assignments at a subscription scope or higher to drive consistency across development teams.
Control which functions are granted to pods, and whether running contradicts policy, by using Azure Policy. This access is defined through built-in policies provided by the Azure Policy Add-on for AKS.
Establish a consistent reliability and security baseline for AKS cluster and pod configurations by using Azure Policy.
Use the Azure Policy Add-on for AKS to control pod functions, like root privileges, and to disallow pods that don't conform to policy.
Note
When you deploy into an Azure landing zone, the Azure policies to help you ensure consistent reliability and security should be provided by the landing zone implementation.
The mission-critical reference implementations provide a suite of baseline policies to drive recommended reliability and security configurations.
Design considerations and recommendations for Azure App Service
For web and API-based workload scenarios, App Service might be a feasible alternative to AKS. It provides a low-friction container platform without the complexity of Kubernetes. For a complete set of recommendations, see Reliability considerations for App Service and Operational excellence for App Service.
Reliability
Evaluate the use of TCP and SNAT ports. TCP connections are used for all outbound connections. SNAT ports are used for outbound connections to public IP addresses. SNAT port exhaustion is a common failure scenario. You should predictively detect this problem by load testing while using Azure Diagnostics to monitor ports. If SNAT errors occur, you need to either scale across more or larger workers or implement coding practices to help preserve and reuse SNAT ports. Examples of coding practices that you can use include connection pooling and the lazy loading of resources.
TCP port exhaustion is another failure scenario. It occurs when the sum of outbound connections from a given worker exceeds capacity. The number of available TCP ports depends on the size of the worker. For recommendations, see TCP and SNAT ports.
Scalability
Plan for future scalability requirements and application growth so that you can apply appropriate recommendations from the start. By doing so, you can avoid technical migration debt as the solution grows.
Enable autoscale to ensure that adequate resources are available to service requests. Evaluate per-app scaling for high-density hosting on App Service.
Be aware that App Service has a default, soft limit of instances per App Service plan.
Apply autoscale rules. An App Service plan scales out if any rule within the profile is met but only scales in if all rules within the profile are met. Use a scale-out and scale-in rule combination to ensure that autoscale can take action to both scale out and scale in. Understand the behavior of multiple scaling rules in a single profile.
Be aware that you can enable per-app scaling at the level of the App Service plan to allow an application to scale independently from the App Service plan that hosts it. Apps are allocated to available nodes via a best-effort approach for an even distribution. Although an even distribution isn't guaranteed, the platform ensures that two instances of the same app aren't hosted on the same instance.
Monitoring
Monitor application behavior and get access to relevant logs and metrics to ensure that your application works as expected.
You can use diagnostic logging to ingest application-level and platform-level logs into Log Analytics, Azure Storage, or a third-party tool via Azure Event Hubs.
Application performance monitoring with Application Insights provides deep insights into application performance.
Mission-critical applications must have the ability to self-heal if there are failures. Enable Auto Heal to automatically recycle unhealthy workers.
You need to use appropriate health checks to assess all critical downstream dependencies, which helps to ensure overall health. We strongly recommend that you enable Health Check to identify non-responsive workers.
Deployment
To work around the default limit of instances per App Service plan, deploy App Service plans in multiple scale units in a single region. Deploy App Service plans in an availability zone configuration to ensure that worker nodes are distributed across zones within a region. Consider opening a support ticket to increase the maximum number of workers to twice the instance count that you need to serve normal peak load.
Container registry
Container registries host images that are deployed to container runtime environments like AKS. You need to configure your container registries for mission-critical workloads carefully. An outage shouldn't cause delays in pulling images, especially during scaling operations. The following considerations and recommendations focus on Azure Container Registry and explore the trade-offs that are associated with centralized and federated deployment models.
Design considerations
Format. Consider using a container registry that relies on the Docker-provided format and standards for both push and pull operations. These solutions are compatible and mostly interchangeable.
Deployment model. You can deploy the container registry as a centralized service that's consumed by multiple applications within your organization. Or you can deploy it as a dedicated component for a specific application workload.
Public registries. Container images are stored in Docker Hub or other public registries that exist outside of Azure and a given virtual network. This isn't necessarily a problem, but it can lead to various issues that are related to service availability, throttling, and data exfiltration. For some application scenarios, you need to replicate public container images in a private container registry to limit egress traffic, increase availability, or avoid potential throttling.
Design recommendations
Use container registry instances that are dedicated to the application workload. Avoid creating a dependency on a centralized service unless organizational availability and reliability requirements are fully aligned with the application.
In the recommended core architecture pattern, container registries are global resources that are long living. Consider using a single global container registry per environment. For example, use a global production registry.
Ensure that the SLA for public registry is aligned with your reliability and security targets. Take special note of throttling limits for use cases that depend on Docker Hub.
Prioritize Azure Container Registry for hosting container images.
Design considerations and recommendations for Azure Container Registry
This native service provides a range of features, including geo-replication, Microsoft Entra authentication, automated container building, and patching via Container Registry tasks.
Reliability
Configure geo-replication to all deployment regions to remove regional dependencies and optimize latency. Container Registry supports high availability through geo-replication to multiple configured regions, providing resiliency against regional outages. If a region becomes unavailable, the other regions continue to serve image requests. When the region is back online, Container Registry recovers and replicates changes to it. This capability also provides registry colocation within each configured region, reducing network latency and cross-region data transfer costs.
In Azure regions that provide availability zone support, the Premium Container Registry tier supports zone redundancy to provide protection against zonal failure. The Premium tier also supports private endpoints to help prevent unauthorized access to the registry, which can lead to reliability issues.
Host images close to the consuming compute resources, within the same Azure regions.
Image locking
Images can get deleted, as a result of, for example, manual error. Container Registry supports locking an image version or a repository to prevent changes or deletions. When a previously deployed image version is changed in place, same-version deployments might provide different results before and after the change.
If you want to protect the Container Registry instance from deletion, use resource locks.
Tagged images
Tagged Container Registry images are mutable by default, which means that the same tag can be used on multiple images pushed to the registry. In production scenarios, this can lead to unpredictable behavior that could affect application uptime.
Identity and access management
Use Microsoft Entra integrated authentication to push and pull images instead of relying on access keys. For enhanced security, fully disable the use of the admin access key.
Serverless compute
Serverless computing provides resources on demand and eliminates the need to manage infrastructure. The cloud provider automatically provisions, scales, and manages the resources required to run deployed application code. Azure provides several serverless compute platforms:
Azure Functions. When you use Azure Functions, application logic is implemented as distinct blocks of code, or functions, that run in response to events, like an HTTP request or queue message. Each function scales as necessary to meet demand.
Azure Logic Apps. Logic Apps is best suited for creating and running automated workflows that integrate various apps, data sources, services, and systems. Like Azure Functions, Logic Apps uses built-in triggers for event-driven processing. However, instead of deploying application code, you can create logic apps by using a graphical user interface that supports code blocks like conditionals and loops.
Azure API Management. You can use API Management to publish, transform, maintain, and monitor enhanced-security APIs by using the Consumption tier.
Power Apps and Power Automate. These tools provide a low-code or no-code development experience, with simple workflow logic and integrations that are configurable through connections in a user interface.
For mission-critical applications, serverless technologies provide simplified development and operations, which can be valuable for simple business use cases. However, this simplicity comes at the cost of flexibility in terms of scalability, reliability, and performance, and that's not viable for most mission-critical application scenarios.
The following sections provide design considerations and recommendations for using Azure Functions and Logic Apps as alternative platforms for non-critical workflow scenarios.
Design considerations and recommendations for Azure Functions
Mission-critical workloads have critical and non-critical system flows. Azure Functions is a viable choice for flows that don't have the same stringent business requirements as critical system flows. It's well suited for event-driven flows that have short-lived processes because functions perform distinct operations that run as fast as possible.
Choose an Azure Functions hosting option that's appropriate for the application's reliability tier. We recommend the Premium plan because it allows you to configure compute instance size. The Dedicated plan is the least serverless option. It provides autoscale, but these scale operations are slower than those of the other plans. We recommend that you use the Premium plan to maximize reliability and performance.
There are some security considerations. When you use an HTTP trigger to expose an external endpoint, use a web application firewall (WAF) to provide a level of protection for the HTTP endpoint from common external attack vectors.
We recommend the use of private endpoints for restricting access to private virtual networks. They can also mitigate data exfiltration risks, like malicious admin scenarios.
You need to use code scanning tools on Azure Functions code and integrate those tools with CI/CD pipelines.
Design considerations and recommendations for Azure Logic Apps
Like Azure Functions, Logic Apps uses built-in triggers for event-driven processing. However, instead of deploying application code, you can create logic apps by using a graphical user interface that supports blocks like conditionals, loops, and other constructs.
Multiple deployment modes are available. We recommend the Standard mode to ensure a single-tenant deployment and mitigate noisy neighbor scenarios. This mode uses the containerized single-tenant Logic Apps runtime, which is based on Azure Functions. In this mode, the logic app can have multiple stateful and stateless workflows. You should be aware of the configuration limits.
Constrained migrations via IaaS
Many applications that have existing on-premises deployments use virtualization technologies and redundant hardware to provide mission-critical levels of reliability. Modernization is often hindered by business constraints that prevent full alignment with the cloud-native baseline (North Star) architecture pattern that's recommended for mission-critical workloads. That's why many applications adopt a phased approach, with initial cloud deployments using virtualization and Azure Virtual Machines as the primary application hosting model. The use of IaaS virtual machines might be required in certain scenarios:
- Available PaaS services don't provide the required performance or level of control.
- The workload requires operating system access, specific drivers, or network and system configurations.
- The workload doesn't support running in containers.
- There's no vendor support for third-party workloads.
This section focuses on the best ways to use Azure Virtual Machines and associated services to maximize the reliability of the application platform. It highlights key aspects of the mission-critical design methodology that transpose cloud-native and IaaS migration scenarios.
Design considerations
The operational costs of using IaaS virtual machines are significantly higher than the costs of using PaaS services because of the management requirements of the virtual machines and the operating systems. Managing virtual machines necessitates the frequent rollout of software packages and updates.
Azure provides capabilities to increase the availability of virtual machines:
- Availability sets can help protect against network, disk, and power failures by distributing virtual machines across fault domains and update domains.
- Availability zones can help you achieve even higher levels of reliability by distributing VMs across physically separated datacenters within a region.
- Virtual Machine Scale Sets provide functionality for automatically scaling the number of virtual machines in a group. They also provide capabilities for monitoring instance health and automatically repairing unhealthy instances.
Design recommendations
Important
Use PaaS services and containers when possible to reduce operational complexity and cost. Use IaaS virtual machines only when you need to.
Right-size VM SKU sizes to ensure effective resource utilization.
Deploy three or more virtual machines across availability zones to achieve datacenter-level fault tolerance.
- If you're deploying commercial off-the-shelf software, consult the software vendor and test adequately before deploying the software into production.
For workloads that can't be deployed across availability zones, use availability sets that contain three or more VMs.
- Consider availability sets only if availability zones don't meet workload requirements, such as for chatty workloads with low latency requirements.
Prioritize the use of Virtual Machine Scale Sets for scalability and zone redundancy. This point is particularly important for workloads that have varying loads. For example, if the number of active users or requests per second is a varying load.
Don't access individual virtual machines directly. Use load balancers in front of them when possible.
To protect against regional outages, deploy application virtual machines across multiple Azure regions.
- See the networking and connectivity design area for details about how to optimally route traffic between active deployment regions.
For workloads that don't support multi-region active/active deployments, consider implementing active/passive deployments by using hot/warm standby virtual machines for regional failover.
Use standard images from Azure Marketplace rather than custom images that need to be maintained.
Implement automated processes to deploy and roll out changes to virtual machines, avoiding any manual intervention. For more information, see IaaS considerations in the Operational procedures design area.
Implement chaos experiments to inject application faults into virtual machine components, and observe the mitigation of faults. For more information, see Continuous validation and testing.
Monitor virtual machines and ensure that diagnostic logs and metrics are ingested into a unified data sink.
Implement security practices for mission-critical application scenarios, when applicable, and the Security best practices for IaaS workloads in Azure.
Next step
Review the considerations for the data platform.
Feedback
Coming soon: Throughout 2024 we will be phasing out GitHub Issues as the feedback mechanism for content and replacing it with a new feedback system. For more information see: https://aka.ms/ContentUserFeedback.
Submit and view feedback for