Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
When you execute a notebook step within a pipeline, an Apache Spark session is started and is used to run the queries submitted from the notebook. When you enable high concurrency mode for pipelines, your notebooks will be automatically packed into the existing spark sessions.
This gives you session sharing capability across all the notebooks within a single user boundary. The system automatically packs all the notebooks in an existing high concurrency session.

Note
Session sharing with high concurrency mode is always within a single user boundary. To share a single spark session, the notebooks must have matching spark configurations, they should be part of the same workspace, and share the same default lakehouse and libraries.
Session sharing conditions
For notebooks to share a single Spark session, they must:
- Be run by the same user.
- Have the same default lakehouse. Notebooks without a default lakehouse can share sessions with other notebooks that don't have a default lakehouse.
- Have the same Spark compute configurations.
- Have the same library packages. You can have different inline library installations as part of notebook cells and still share the session with notebooks having different library dependencies.
Configure high concurrency mode
Fabric workspace admins can enable the high concurrency mode for pipelines using the workspace settings. Use the following steps to configure the high concurrency feature:
Select the Workspace settings option in your Fabric workspace.
Navigate to the Data Engineering/Science section > Spark settings > High concurrency.
In the High concurrency section, enable the For pipeline running multiple notebooks setting.

Enabling the high concurrency option allows all the notebook sessions triggered by pipelines as a high concurrency session.
The system automatically packs the incoming notebook sessions to active high concurrency sessions. If there are no active high concurrency sessions, a new high concurrency session is created and the concurrent notebooks submitted are packed into the new session.

Use session tag in notebook to group shared sessions
Navigate to your workspace, select the New item button, and create a new Pipeline.
Navigate to the Activities tab in the menu ribbon and add a Notebook activity.
From Advanced settings, specify any string value for the session tag property.
After the session tag is added, the notebook sharing uses this tag as matching criteria bundling all notebooks with the same session tag.


Note
To optimize performance, a single high-concurrency session can share resources across a maximum of 5 notebooks identified by the same session tag. When more than 5 notebooks are submitted with the same tag, the system will automatically create a new high-concurrency session to host the subsequent notebook steps. This allows for efficient scaling and load balancing by distributing the workload across multiple sessions.
Monitor and debug notebooks triggered by pipelines
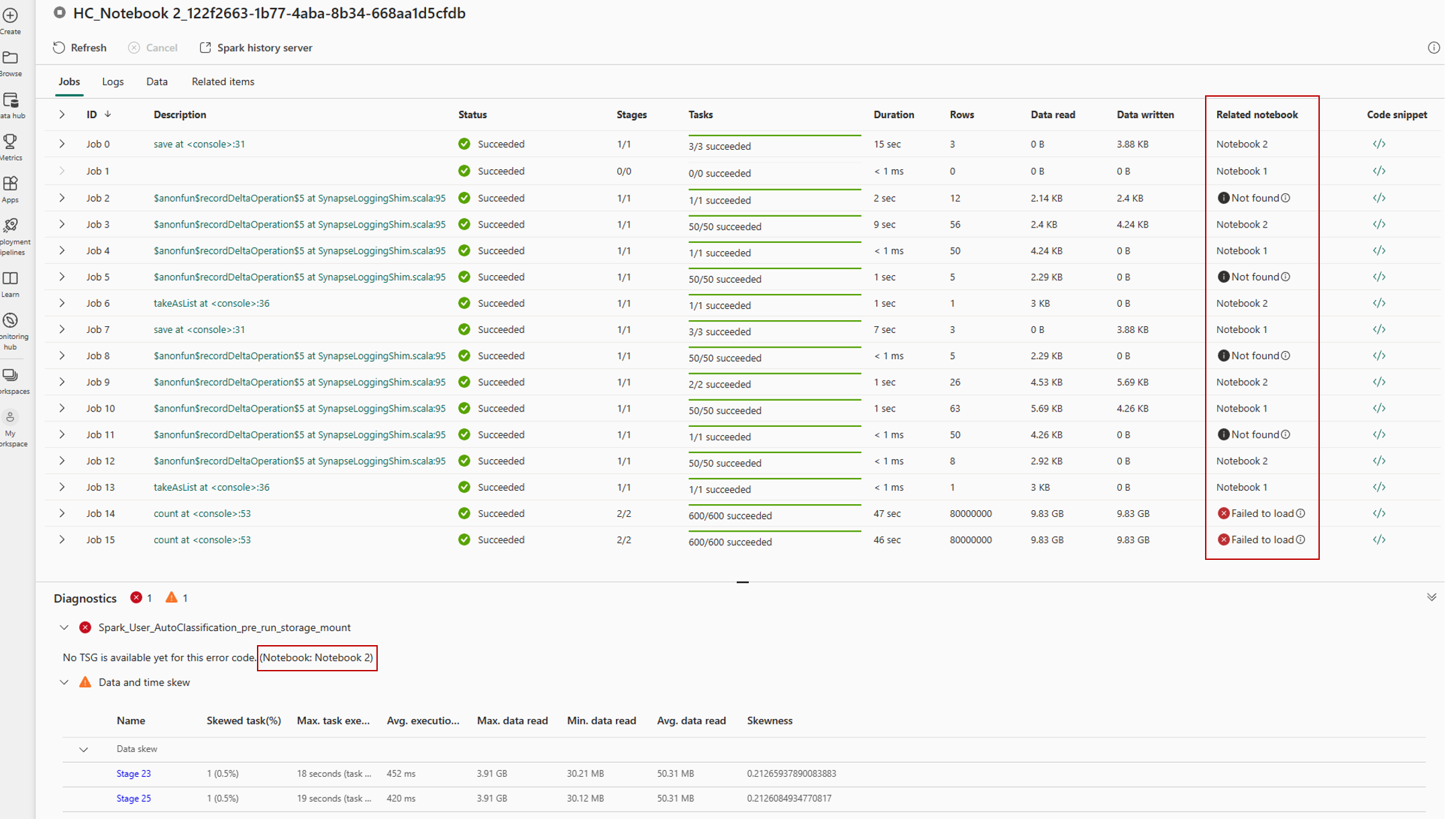
Monitoring and debugging can be challenging when multiple notebooks are running within a shared session. In high concurrency mode, log separation is provided, enabling you to trace logs from Spark events for each individual notebook.
When the session is in progress or in completed state, you can view the session status by navigating to the Run menu and selecting the All Runs option.
This opens the run history of the notebook with the list of current active and historic spark sessions.

By selecting a session, you can access the monitoring detail view, which displays a list of all Spark jobs executed within that session.
For high concurrency session, you can identify the jobs and its associated logs from different notebooks using the Related notebook tab, which shows the notebook from which that job was run.


Related content
- To learn more about high concurrency mode in Microsoft Fabric, see High concurrency mode in Apache Spark for Fabric.
- To get started with high concurrency mode for notebooks, see Configure high concurrency mode for Fabric notebooks.