Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
When you run a notebook in Microsoft Fabric, an Apache Spark session is started and is used to run the queries submitted as part of the notebook cell executions. With high concurrency mode enabled, there's no need to start new spark sessions every time to run a notebook.
If you already have a high concurrency session running, you could attach notebooks to the high concurrency session getting a spark session instantly to run the queries and achieve a greater session utilization rate.

Note
The high concurrency mode-based session sharing is always within a single user boundary. The notebooks need to have matching spark configurations, should be part of the same workspace, share the same default lakehouse and libraries to share a single spark session.
Session sharing conditions
For notebooks to share a single Spark session, they must:
- Be run by the same user.
- Have the same default lakehouse. Notebooks without a default lakehouse can share sessions with other notebooks that don't have a default lakehouse.
- Have the same Spark compute configurations.
- Have the same library packages. You can have different inline library installations as part of notebook cells and still share the session with notebooks having different library dependencies.
Configure high concurrency mode
By default, all the Fabric workspaces are enabled with high concurrency mode. Use the following steps to configure the high concurrency feature:
Click on Workspace settings option in your Fabric workspace.
Navigate to the Data Engineering/Science section > Spark settings > High concurrency.
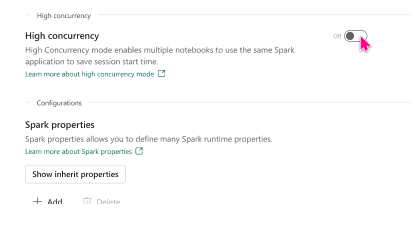
In the High concurrency section, enable the For notebooks setting. You can choose to enable or disable the setting from this pane.
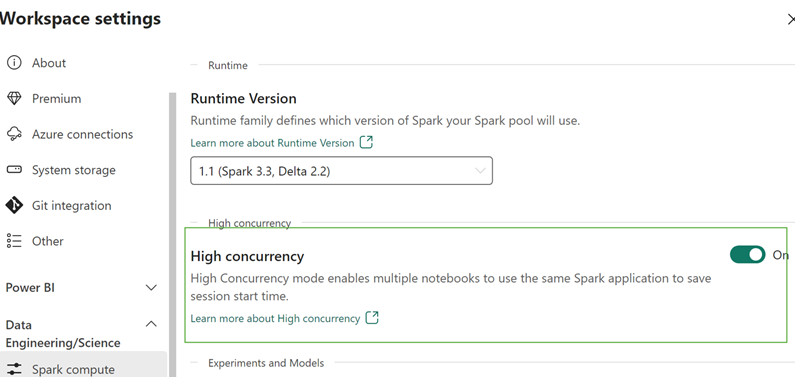
Enabling the high concurrency option allows users to start a high concurrency session in their notebooks or attach to existing high concurrency session.
Disabling the high concurrency mode hides the section to configure the time period of inactivity and also hides the option to start a new high concurrency session from the notebook menu.


Run notebooks in high concurrency session
Open the Fabric workspace.
Create a notebook or open an existing notebook.
Navigate to the Run tab in the menu ribbon and select the session type dropdown that has Standard selected as the default option.
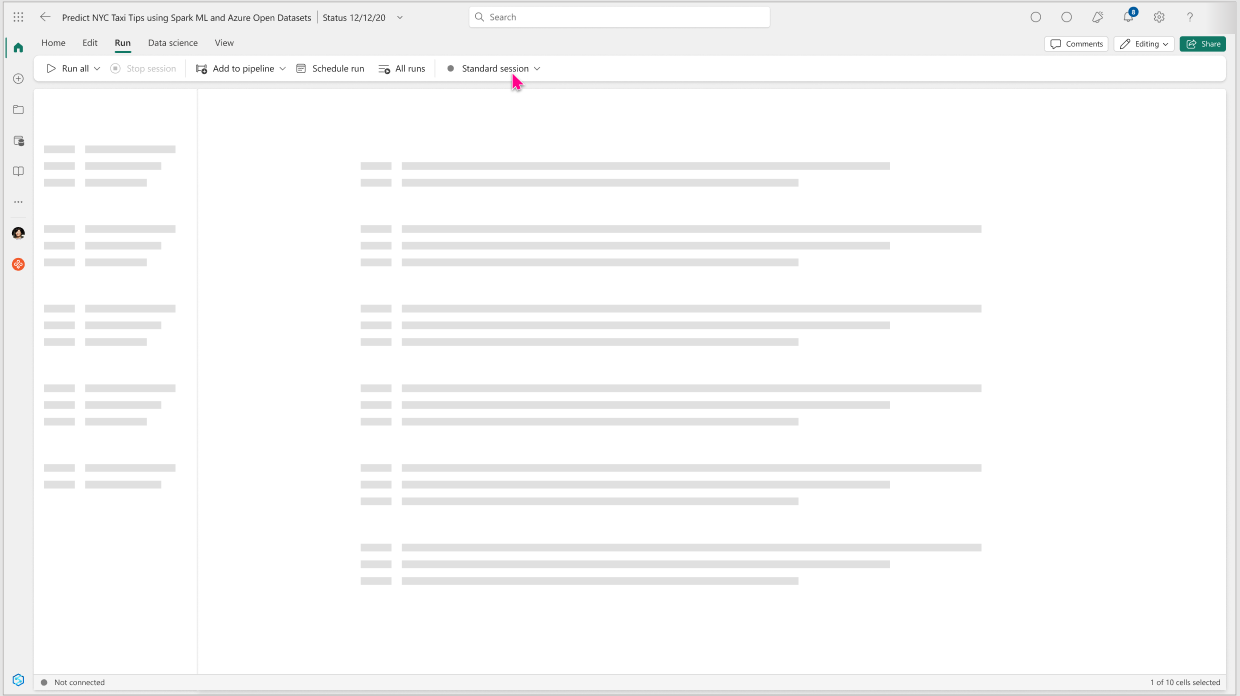
Select New high concurrency session.
Once the high concurrency session has started, you could now add upto 5 notebooks in the high concurrency session.
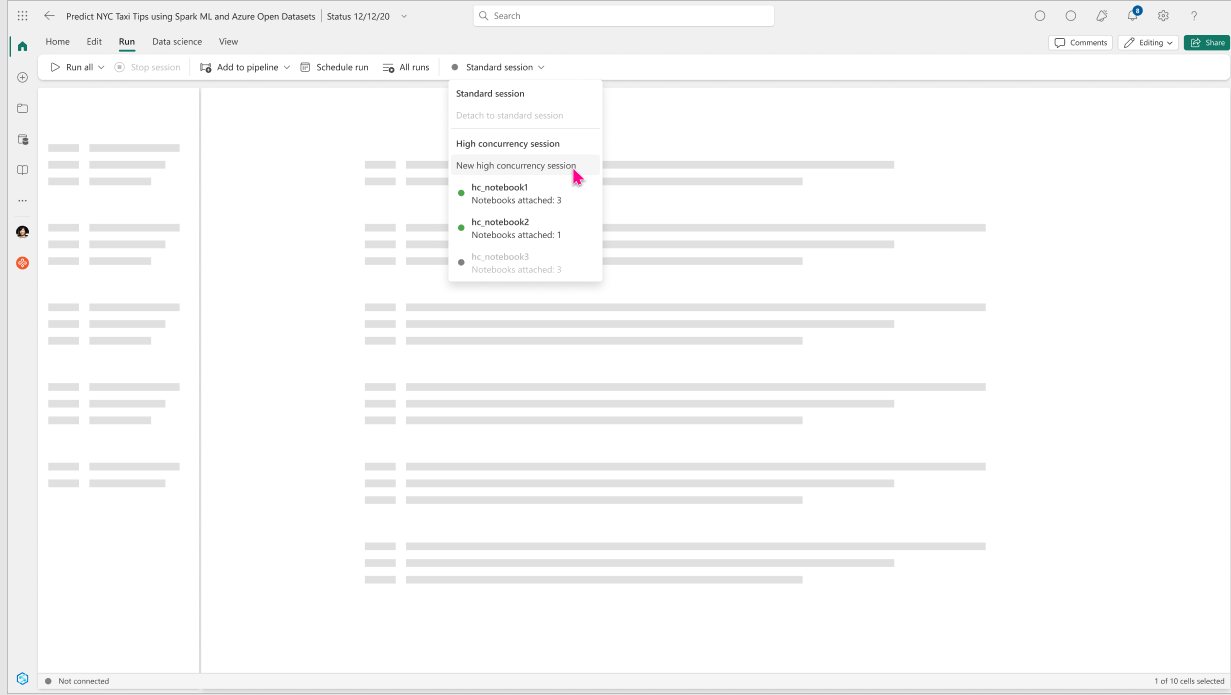
Create a new notebook and by navigating to the Run menu as mentioned in the above steps, in the drop-down menu you will now see the newly created high concurrency session listed.
Selecting the existing high concurrency session attaches the second notebook to the session.
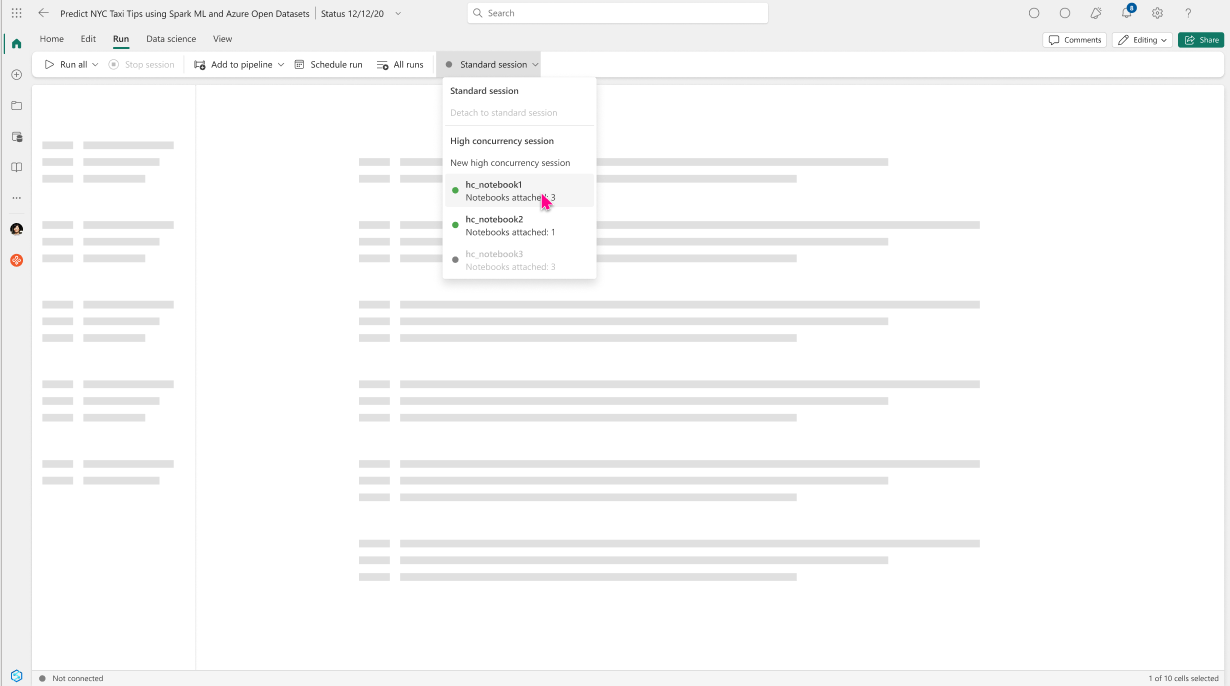
Once the notebook has been attached, you can start executing the notebook steps instantly.
The high concurrency session status also shows the number of notebooks attached to a given session at any point in time.
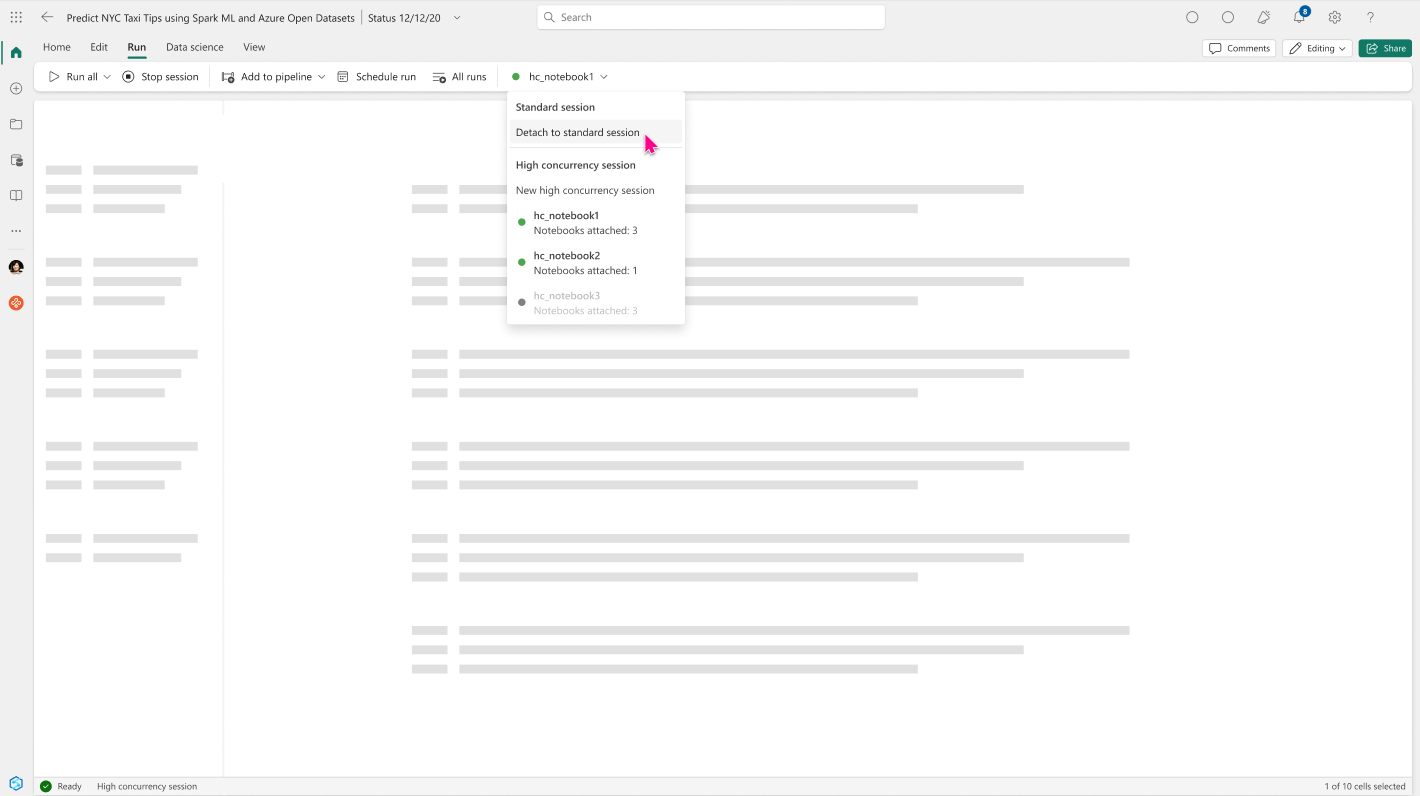
At any point in time if you feel the notebook attached to a high concurrency session requires more dedicated compute, you can choose to switch the notebook to a standard session by selecting the option to detach the notebook from the high concurrency in the Run menu tab.
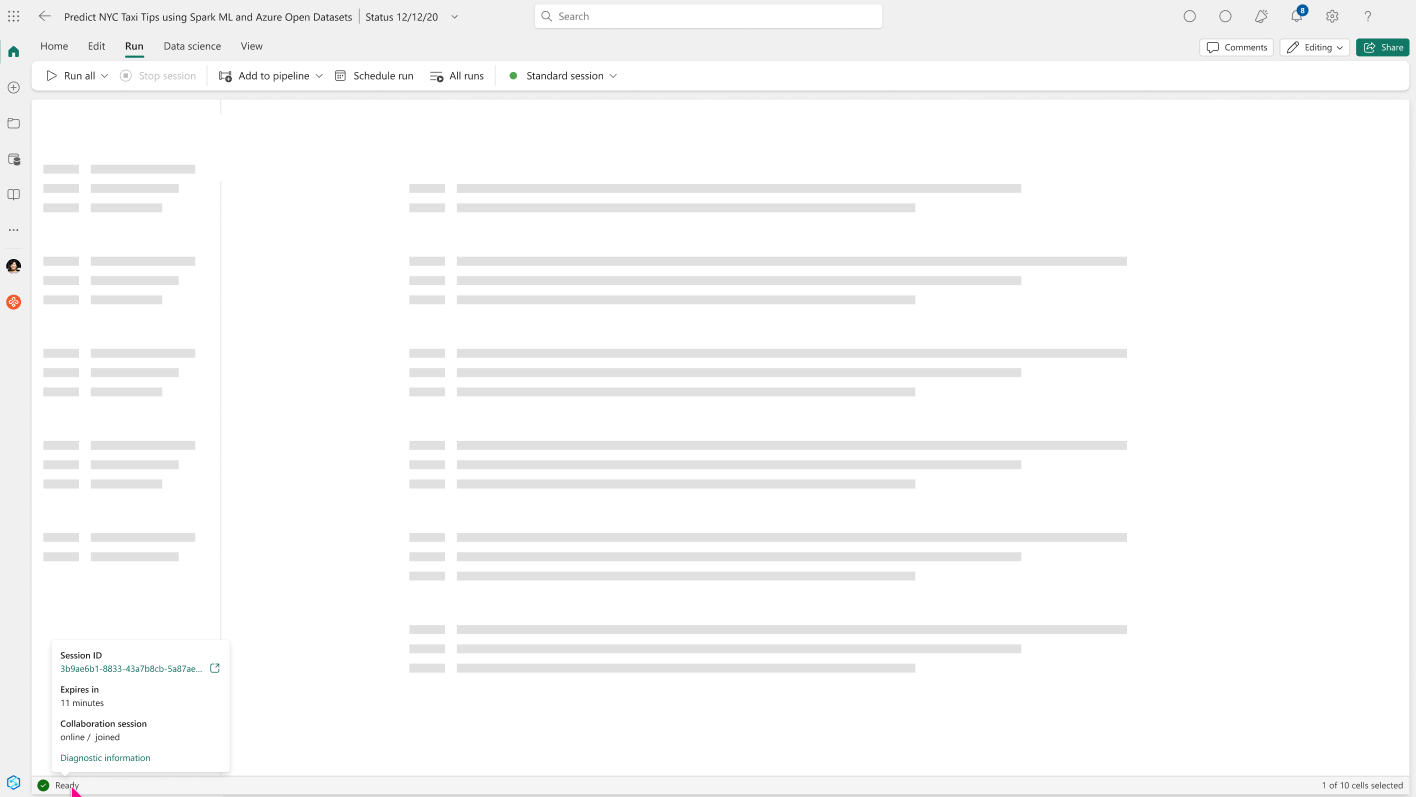
You can view the session status, type, and ID in the status bar. Select the Session ID to explore the jobs executed in this high concurrency session and to view logs of the spark session on the monitoring detail page.





You can also configure high concurrency mode for notebooks in pipelines and use session tags to group shared sessions.
Monitoring and debugging notebooks running in high concurrency session
Monitoring and debugging are often a non-trivial task when you are running multiple notebooks in a shared session. For high concurrency mode in Fabric, separation of logs is offered which would allow users to trace the logs emitted by spark events from different notebooks.
When the session is in progress or in completed state, you can view the session status by navigating to the Run menu and selecting the All Runs option
This would open up the run history of the notebook showing the list of current active and historic spark sessions

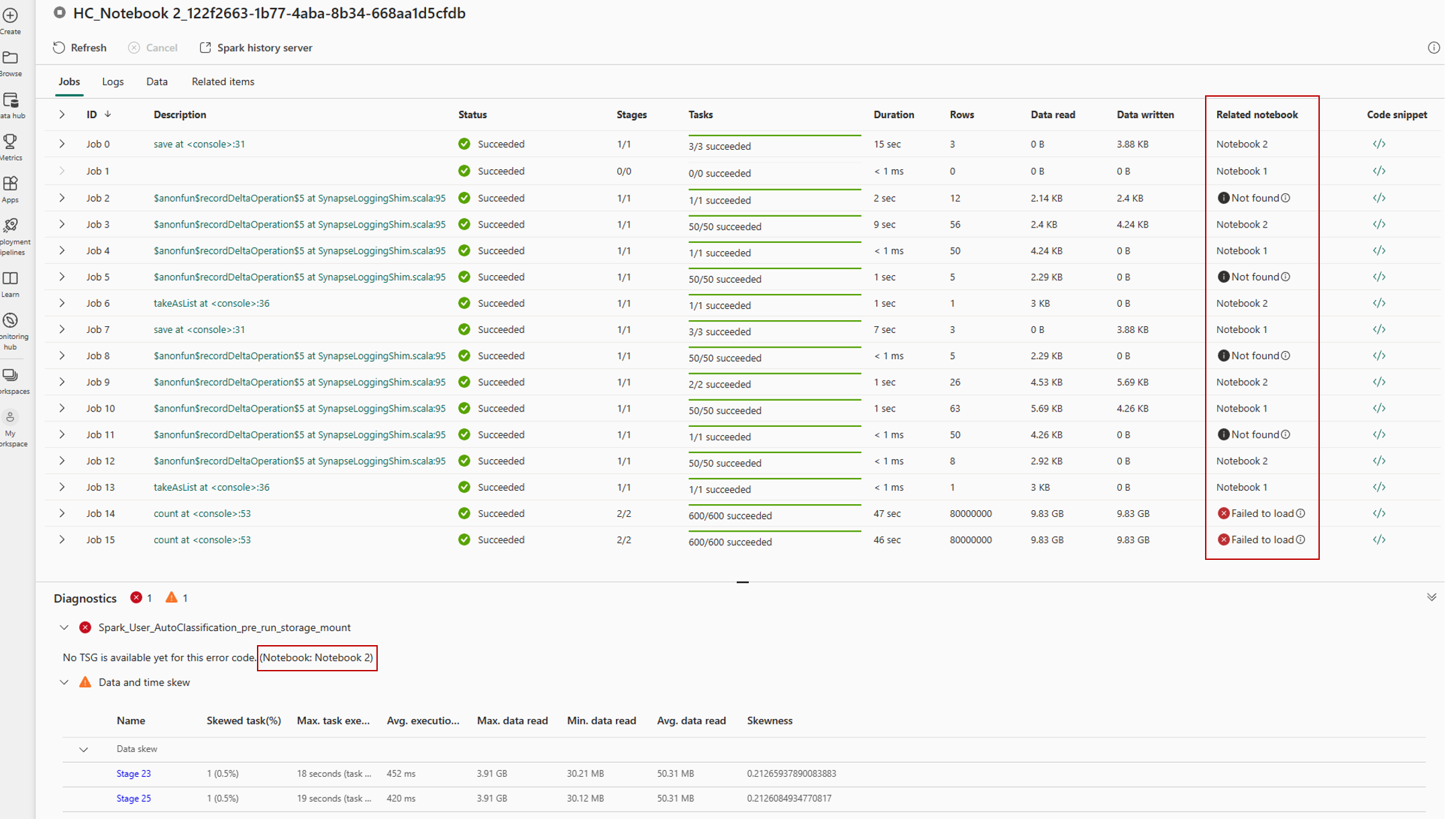
Users by selecting a session, can access the monitoring detail view, which shows the list of all the spark jobs that have been run in the session.
In the case of high concurrency session, users could identify the jobs and its associated logs from different notebooks using the Related notebook tab, which shows the notebook from which that job has been run.


Related content
In this document, you get a basic understanding of a session sharing through high concurrency mode in notebooks. Advance to the next articles to learn how to create and get started with your own Data Engineering experiences using Lakehouse and Notebooks:
- To get started with Lakehouse, see Create a lakehouse in Microsoft Fabric.
- To get started with notebooks, see How to use a Microsoft Fabric notebooks.