Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
In this article, we discuss techniques to help you to optimize Copy activity with a SQL database source, using an Azure SQL Database as a reference. We cover different aspects of optimization including data transfer speeds, cost, monitoring, ease of development, and balancing these various considerations for the best outcome.
Copy activity options
Note
The metrics included in this article are the results of test cases comparing and contrasting behavior across various capabilities, and are not formal engineering benchmarks. All test cases are moving data from East US 2 to West US 2 regions.
When starting with a pipeline Copy activity, it's important to understand the source and destination systems before starting development. You should state what you are optimizing for, and understand how to monitor the source, destination, and pipeline to achieve the best resource utilization, performance, and consumption.
When sourcing from an Azure SQL Database, it's important to understand:
- Input/output operations per second (IOPS)
- Data volume
- DDL of one or more tables
- Partitioning schemas
- Primary Key or other column with a good distribution of data (skew)
- Compute allocated and associated limitations such as number of concurrent connections
The same applies to your destination. With an understanding of both, you can design a pipeline to operate within the bounds and limits of both the source and destination while optimizing for your priorities.
Note
Network bandwidth between the source and destination, along with input/output per second (IOPs) of each, can both be a bottleneck to throughput, and it is recommended to understand these boundaries. However, networking is not within the scope of this article.
Once you understand both your source and destination, you can use various options in the Copy activity to improve its performance for your priorities. These options could include:
- Source partitioning options - None, Physical partition, Dynamic range
- Source isolation level - None, Read uncommitted, Read committed, Snapshot
- Intelligent throughput optimization setting - Auto, Standard, Balanced, Maximum
- Degree of copy parallelism setting - Auto, Specified value
- Logical partitioning - Pipeline design to generate multiple concurrent Copy activities
Source details: Azure SQL Database
To provide concrete examples, we tested multiple scenarios, moving data from an Azure SQL Database into both Fabric Lakehouse (tables) and Fabric Warehouse tables. In these examples, we tested four source tables. All have the same schema and record count. One uses a heap, a second uses a clustered index, while the third and fourth use 8 and 85 partitions respectively. This example used a trial capacity (F64) in Microsoft Fabric (West US 2).
- Service Tier: General Purpose
- Compute Tier: Serverless
- Hardware Configuration: Standard-series (Gen5)
- Max vCores: 80
- Min vCores 20
- Record Count: 1,500,000,000
- Region: East US 2
Default Evaluation
Before setting the source Partition option, it's important to understand the default behavior of the Copy activity.
The default settings are:
Source
- Partition option - None
- Isolation level - None
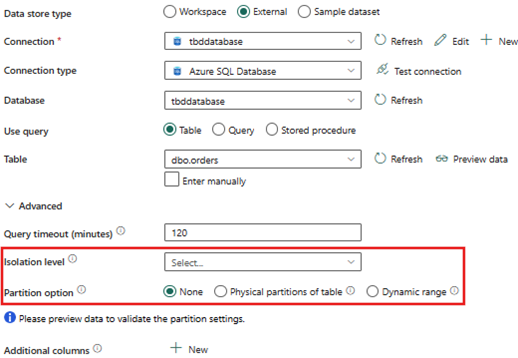
Advanced settings
- Intelligent throughput optimization - Auto
- Degree of copy parallelism - Auto
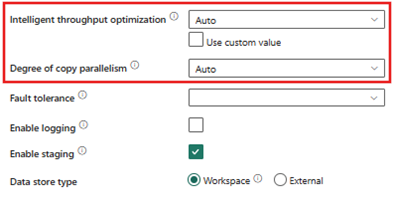


For the purposes of setting an initial benchmark for future comparison, we used the default settings for a copy activity run that loaded 1.5 billion records into each destination and took a little over 2 hours per copy activity.
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Lakehouse | None | Auto | 1 | 02:10:37 |
In this article, we focus on total duration. Total duration encompasses other stages such as queue, precopy script, and transfer duration. For more information on these stages, see Copy activity execution details. For an extensive overview of Copy activity properties for Azure SQL Database as the source, refer to Azure SQL Database source properties for the Copy activity.
Settings
Intelligent throughput optimization (ITO)
ITO determines the maximum amount of CPU, memory, and network resource allocation the activity can consume. If you set ITO to Maximum (or 256), the service selects the highest value that provides the most optimized throughput. In this article, all test cases have ITO set to Maximum, although the service uses only what it requires and the actual value is lower than 256.
For a deeper understanding of ITO, refer to Intelligent throughput optimization.
Note
Staging is required when the Copy activity sink is Fabric Warehouse. Options such as Degree of copy parallelism and Intelligent throughput optimization only apply in that case from Source to Staging. Test cases to Lakehouse did not have staging enabled.
Partition options
When your source is a relational database like Azure SQL database, in the Advanced section, you can specify a Partition option. By default, this setting is set to None, with two other options of Physical partitions of table and Dynamic Range.
Dynamic range
Heap table
Dynamic Range allows the service to intelligently generate queries against the source. The number of queries generated is equal to the number of Used parallel copies the service selected at runtime. The Degree of copy parallelism and Used parallel copies are important to consider when optimizing the use of the Dynamic range partition option.
Partition bounds
The Partition upper and lower bounds are optional fields that allow you to specify the partition stride. In these test cases, we predefined both the upper and lower bounds. If these fields aren't specified, the system incurs extra overhead in querying the source to determine the ranges. For optimal performance, obtain the boundaries beforehand, especially for one-time historical loads.
For more information reference the table in, the Parallel copy from SQL database section of the Azure SQL Database connector article.
The following SQL query determines our range min and max:

Then we provide those details in the Dynamic range configuration.

Here's an example query generated by the Copy activity using Dynamic range:
SELECT * FROM [dbo].[orders] WHERE [o_orderkey] > '4617187501' AND [o_orderkey] <= '4640625001'
Degree of copy parallelism
By default, Auto is assigned for the Degree of copy parallelism. However, Auto might not achieve the optimal number of parallel copies. Parallel copies correlates to the number of sessions established on the source database. If too many parallel copies are generated, the source database CPU is at risk of being overtaxed, leading to queries being in a suspended state.
In the original test case for Dynamic range using Auto, the service actually generated 251 parallel copies at runtime. By specifying a value in Degree of copy parallelism, you set the maximum number of parallel copies. This setting allows you to limit the number of concurrent sessions made to your source, allowing you to better control your resource management. In these test cases, by specifying 50 as the value, both total duration and source resource utilization improved.
| Destination | Partition Option | Degree of copy parallelism | Used Parallel Copies | Total Duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Warehouse | Dynamic Range | 50 | 50 | 00:13:05 |
Dynamic range with a Degree of parallel copies can significantly improve performance. However, using the setting requires either predefining the boundaries or allowing the service to determine the values at runtime. Allowing the service to determine the values at runtime can affect total duration, depending on the DDL and data volume of the source table. In addition, allowing the service to determine the values at runtime should also be paired with an understanding of how many parallel copies your source can handle. If the value is too high, source system and copy activity performance can be degraded.
For more information on parallel copies, see Copy activity performance features: Parallel copy.
Fabric Warehouse with dynamic range
By default, Isolation level isn't specified, and Degree of parallelism is set to Auto.
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Warehouse | Dynamic Range | Auto | 251 | 00:39:03 |
Fabric Lakehouse (Tables) with dynamic range
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Lakehouse | None | Auto | 1 | 02:23:21 |
| Fabric Lakehouse | Dynamic Range | Auto | 251 | 00:36:40 |
| Fabric Lakehouse | Dynamic Range | 50 | 50 | 00:12:01 |
Clustered index
Compared to a heap table, a table with a clustered key index on the column selected for the dynamic range’s partition column drastically improved performance and resource utilization. This was true even when degree of copy parallelism was set to auto.
Fabric Warehouse with clustered index
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Warehouse | Dynamic Range | Auto | 251 | 00:09:02 |
| Fabric Warehouse | Dynamic Range | 50 | 50 | 00:08:38 |
Fabric Lakehouse (Tables) with clustered index
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Lakehouse | None | Auto | 1 | 02:23:21 |
| Fabric Lakehouse | Dynamic Range | Auto | 251 | 00:06:44 |
| Fabric Lakehouse | Dynamic Range | 50 | 50 | 00:06:34 |
Logical partition design
The logical partition design pattern is more advanced and requires more developer effort. However, this design is used in scenarios with strict data loading requirements. This design was originally developed to meet the needs of an on-premises Oracle database to load 180 GB of data in under 1.5 hours. The original design, using defaults of the copy activity, took over 65 hours. By using a Logical Partitioning Design, we see the same data transferred in under 1.5 hours.
This design was also used in this blog series: Pipeline performance improvements Part 1: How to convert a time interval into seconds). This design is good to emulate in your environment when you're loading large source tables and need optimal loading performance by using techniques like setting a data range to partition the source data reads. This design generates many subdate ranges. Then using a For-Each activity to iterate over the ranges, many copy activities are invoked to source data between the specified range. Within the For-Each activity, all of the copy activities run in parallel (up to the batch count maximum of 50) and have degree of copy parallelism set to Auto.
For the below examples, the partitioned date values were set to these values:
- Starting value: 1992-01-01
- Ending value: 1998-08-02
- Bucket Interval Days: 50
Parallel copies and total duration are a max value observed across all 50 copy activities that were created. Since all 50 ran in parallel, the max value for Total Duration is how long all copy activities took to finish in parallel.
Fabric Warehouse with logical partition design
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Warehouse | Logical Design | Auto | 1 | 00:12:11 |
Fabric Lakehouse (Tables) with logical partition design
| Destination | Partition Option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Lakehouse | None | Auto | 1 | 02:10:37 |
| Fabric Lakehouse | Logical Design | Auto | 1 | 00:09:14 |
Physical partitions of table
Note
When using physical partitions, the partition column and mechanism will be automatically determined based on your physical table definition.
To use physical partitions of a table, the source table must be partitioned. To understand how the number of partitions affect performance, we created two partitioned tables, one with 8 partitions and the other with 85 partitions.
The number of physical partitions limits the Degree of copy parallelism. You can still limit the number by specifying a value less than the number of partitions.
Fabric Warehouse with physical partitions
| Destination | Partition option | Degree of copy parallelism | Used parallel Copies | Total duration |
|---|---|---|---|---|
| Fabric Warehouse | None | Auto | 1 | 02:23:21 |
| Fabric Warehouse | Physical | Auto | 8 | 00:26:29 |
| Fabric Warehouse | Physical | Auto | 85 | 00:08:31 |
Fabric Lakehouse (Tables) with physical partitions
| Destination | Partition option | Degree of copy parallelism | Used parallel copies | Total duration |
|---|---|---|---|---|
| Fabric Lakehouse | None | Auto | 1 | 02:10:37 |
| Fabric Lakehouse | Physical | Auto | 8 | 00:36:36 |
| Fabric Lakehouse | Physical | Auto | 85 | 00:12:21 |
Isolation levels
Let’s compare how specifying different Isolation level settings affect performance. When you select Isolation level with a Degree of copy parallelism set to Auto, the Copy activity is at risk of overtaxing the source system and failing. It's recommended to leave Isolation level as None if you want to leave Degree of copy parallelism set to Auto.
Note
Azure SQL Database defaults to the *Isolation level Read_Committed_Snapshot.
Let’s expand the test case for Dynamic range with Degree of copy parallelism set to 50 and see how Isolation level affects performance.
| Isolation level | Total duration | Capacity Units | DB Max CPU % | DB Max Session |
|---|---|---|---|---|
| None (default) | 00:14:23 | 93,960 | 70 | 76 |
| Read Uncommitted | 00:13:46 | 89,280 | 81 | 76 |
| Read Committed | 00:25:34 | 97,560 | 81 | 76 |
The Isolation level you choose for your database source queries would be more of a requirement rather than optimization path, however it's important to understand the differences in performance and Capacity Units consumption between each option.
For more information on Isolation level,** refer to IsolationLevel Enum.
ITO and capacity consumption
Similar to Degree of parallel copies, Intelligent throughput optimization (ITO) is another maximum value that can be set. If you're optimizing for cost, ITO is a great setting to consider adjusting to meet your desired outcome.
ITO Ranges:
| ITO | Max Value |
|---|---|
| Auto | Not specified |
| Standard | 64 |
| Balanced | 128 |
| Maximum | 256 |
While the drop-down allows for the above settings, we also allow for the use of custom values between 4 and 256.
Note
The actual number of ITO used can be found in the Copy activity output usedDataIntegrationUnits field.
For the Dynamic range Heap test case where Degree of parallel copies was set to Auto, the service selected Balanced with an actual value of 100. Let’s see what happens when the ITO is cut in half by specifying a Custom Value of 50:
| ITO specified | Total duration | Capacity Units | DB Max CPU % | DB Max Session | Use optimized throughput |
|---|---|---|---|---|---|
| Maximum (256) | 00:13:46 | 89,280 | 81 | 76 | Balanced (100) |
| 50 | 00:18:28 | 48,600 | 76 | 61 | Standard (48) |
By cutting the ITO by 50%, the total duration increased by 34%, however the service used 45.5% less Capacity Units. If you aren't optimizing for improved Total duration and want to reduce the Capacity Units used, it would be beneficial to set the ITO to a lower value.
Summary
The following charts summarize the behavior of loading into both the Fabric Warehouse and Fabric Lakehouse tables. If the table has a physical partition, then using the Partition option: Physical partitions of table would be the most balanced approach for transfer duration, capacity units, and compute overhead on the source. This setting is especially ideal if you have more sessions running against the database during the time of data movement.
If your table doesn't have physical partitions, you still have the option of using the Partition option: Dynamic Range. This option would require a prior step to determine the upper and lower bounds, but it still provides significant improvements in transfer duration compared to the default options at the cost of a bit higher capacity consumption, source compute utilization, and the need to test for optimal Degree of parallelism.
Another important factor to maximize performance of your copy jobs is to keep the data movement inside of a single cloud region. For example, data movement from a source and destination data store in US West, with a Data Factory in US West outperforms a copy job moving data from US East to US West.
Finally, if speed is the most important aspect of optimization, having an optimized DDL of your source table is critical in using physical partition options. For a nonpartitioned table, try Dynamic range, and this setting isn't fast enough, consider logical partitioning or a hybrid approach of logical partitioning plus Dynamic range within the subboundaries.
Guidelines
Cost Adjust Intelligent throughput optimization and Degree of Parallel Copies. Speed For partitioned tables, if there's a good number of partitions then use Partition option: Physical partitions of tables. Otherwise, if data is skewed or there's a limited number of partitions, consider using Dynamic range. For heap and tables with indexes, use Dynamic range with Degree of parallel copies that would limit the number of suspended queries on your source. If you can predefine the partition upper/lower bounds, you can realize further performance improvements.
Consider maintainability and developer effort. While leaving the default options take the longest time to move data, running with the defaults might be the best option, especially if the source table’s DDL is unknown. This also provides reasonable Capacity Units consumption.
Test cases
Fabric Warehouse test cases
| Partition option | Degree of copy parallelism | Used parallel copies | Total duration | Capacity Units | Max CPU % | Max Session Count |
|---|---|---|---|---|---|---|
| None | Auto | 1 | 02:23:21 | 51,839 | < 1 | 2 |
| Physical (8) | Auto | 8 | 00:26:29 | 49,320 | 3 | 10 |
| Physical (85) | Auto | 85 | 00:08:31 | 108,000 | 15 | 83 |
| Dynamic Range (Heap) | Auto | 242 | 00:39:03 | 282,600 | 100 | 272 |
| Dynamic Range (Heap) | 50 | 50 | 00:13:05 | 92,159 | 81 | 76 |
| Dynamic Range (Clustered Index) | Auto | 251 | 00:09:02 | 64,080 | 9 | 277 |
| Dynamic Range (Clustered Index) | 50 | 50 | 00:08:38 | 55,440 | 10 | 77 |
| Logical Design | Auto | 1 | 00:12:11 | 226,108 | 91 | 50 |
Fabric Lakehouse (Tables) test cases
| Partition option | Degree of copy parallelism | Used parallel copies | Total duration | Capacity Units | Max CPU % | Max Session Count |
|---|---|---|---|---|---|---|
| None | Auto | 1 | 02:10:37 | 47,520 | <1% | 2 |
| Physical (8) | Auto | 8 | 00:36:36 | 64,079 | 2 | 10 |
| Physical (85) | Auto | 85 | 00:12:21 | 275,759 | ||
| Dynamic Range (Heap) | Auto | 251 | 00:36:12 | 280,080 | 100 | 276 |
| Dynamic Range (Heap) | 50 | 50 | 00:12:01 | 101,159 | 68 | 76 |
| Dynamic Range (Clustered Index) | Auto | 251 | 00:06:44 | 59,760 | 11 | 276 |
| Dynamic Range (Clustered Index) | 50 | 50 | 00:06:34 | 54,760 | 10 | 76 |
| Logical Design | Auto | 1 | 00:09:14 | 164,908 | 82 | 50 |
Related content
- How to copy data using copy activity
- Copy activity performance and scalability guide
- Copy and transform data in Azure SQL Database
- Configure Azure SQL Database in a copy activity
- Create partitioned tables and indexes in Azure SQL Database
- Microsoft Fabric Blog: Pipeline performance improvement part 3 - Gaining more than 50% improvement for historical loads