Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
The Copy job in Data Factory makes it easy to move data from your source to your destination without creating a pipeline. You can set up data transfers using built-in patterns for both batch and incremental copy, and copy once or on a schedule. Follow the steps in this article to start copying your data either from a database or from storage.
Create a Copy job to ingest data from a database
Follow these steps to set up a Copy job that moves data from a database:
Create a new workspace or use an existing workspace.
Select + New Item, choose the Copy job icon, name your Copy job, and select Create.

Choose the database to copy data from. In this example, we're using Azure SQL DB.

For Azure SQL DB enter your server path and credentials. You can copy data securely within a virtual network environment using on-premises or virtual network gateway. For other databases, the connection details will vary.
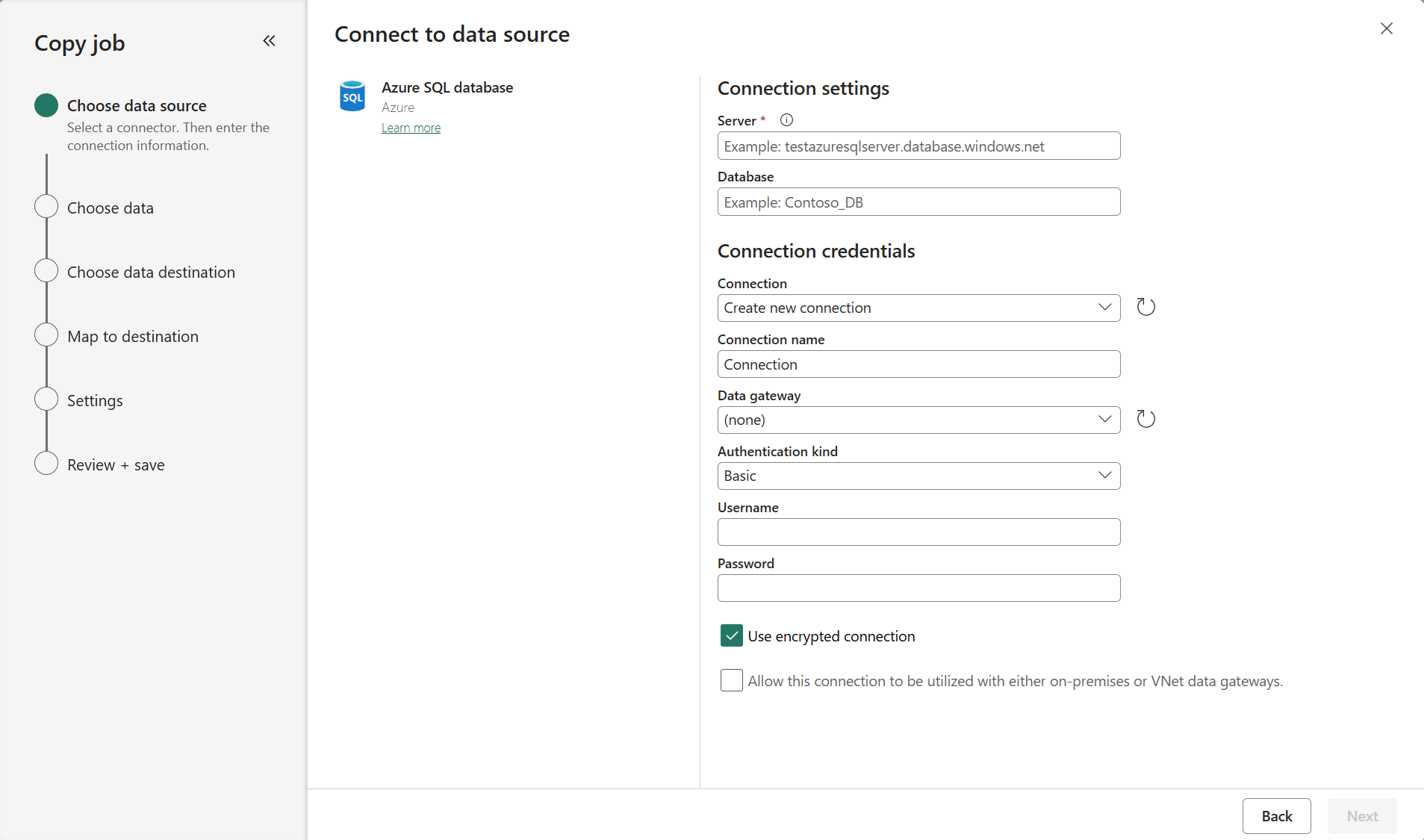
Select the tables and columns to copy. Use the search box to identify specific tables and columns you want to copy.

Select your destination store. In this example, we're using another Azure SQL DB.

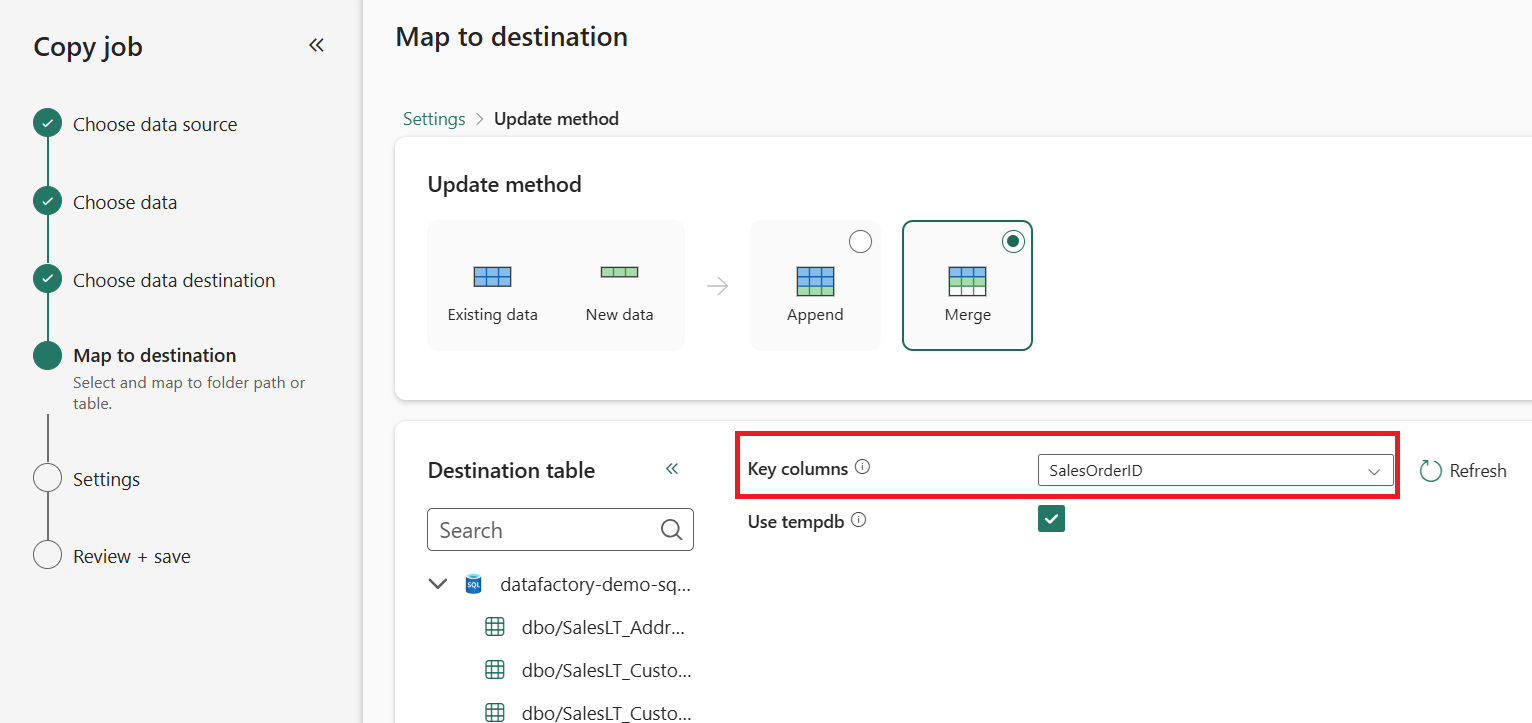
(Optional) Choose Update method to decide how data gets written to your destination. If you pick Merge, select the Key columns that identify each row.

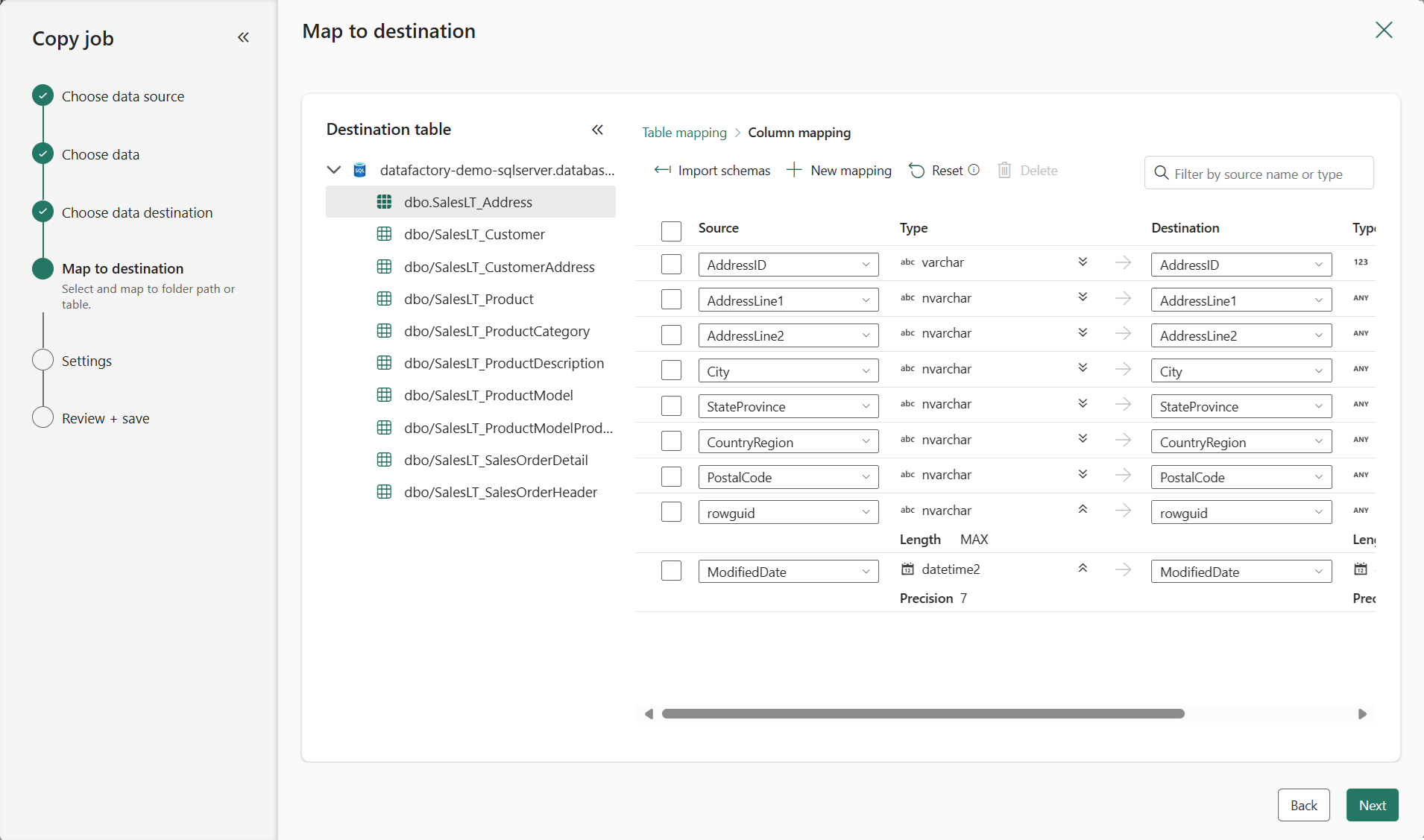
(Optional) Configure table or column mapping to rename tables or columns in the destination, or apply data type conversions. By default, data is copied with the same table name, column name, and data type as the source.

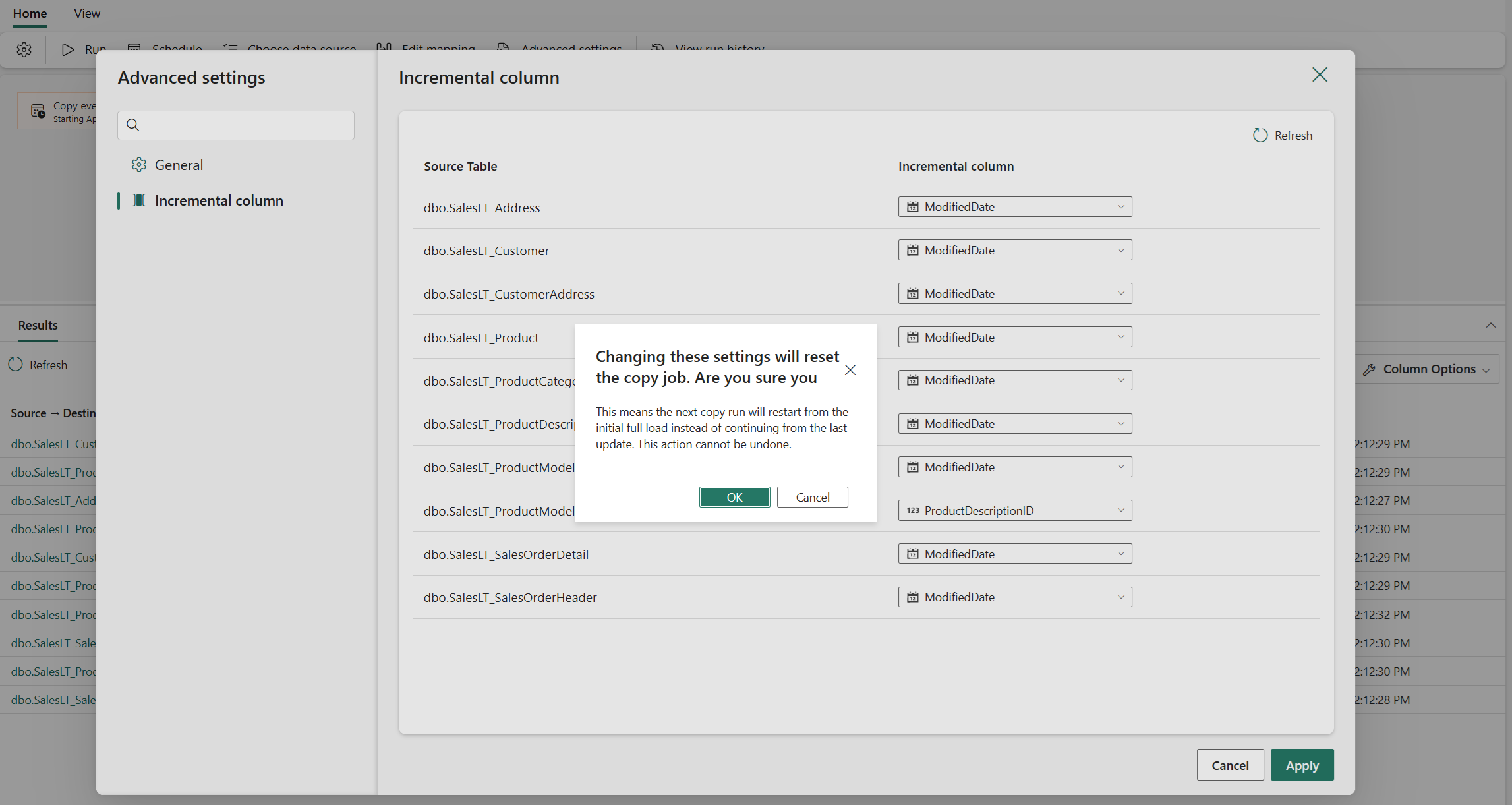
Choose a copy mode: Full data copy or Incremental copy. In this example, we use Incremental copy. Choose an Incremental column for each table, to track which rows have changed. You can use the preview button to find the right column. For more information about that column, see: Incremental column.
Note
When you choose incremental copy mode, Copy job initially performs a full load and performs incremental copies in the next runs.

Review the job summary, select your run option to run once or on a schedule, and select Save + Run.

Your Copy job will start immediately, and you can track the job's status from the inline monitoring panel that has information including row counts and copy duration for each table. Learn more in How to monitor a Copy job

You can run your Copy job whenever you want, even if it's set to run on a schedule. Just select the Run button at any time, and Copy job copies only the data that's changed since the last run.
You can also edit your Copy job at any time, including adding or removing tables and columns to be copied, configuring the schedule, or adjusting advanced settings. Some changes, such as updating the incremental column, will reset the incremental copy to start from an initial full load in the next run.












Create a Copy job to ingest files from a storage
Follow these steps to set up a Copy job that moves data from file storage:
Create a new workspace or use an existing workspace.
Select + New Item, choose the Copy job icon, name your Copy job, and select Create.
Choose the data stores to copy data from. In this example, we used Azure Data Lake Storage Gen2.
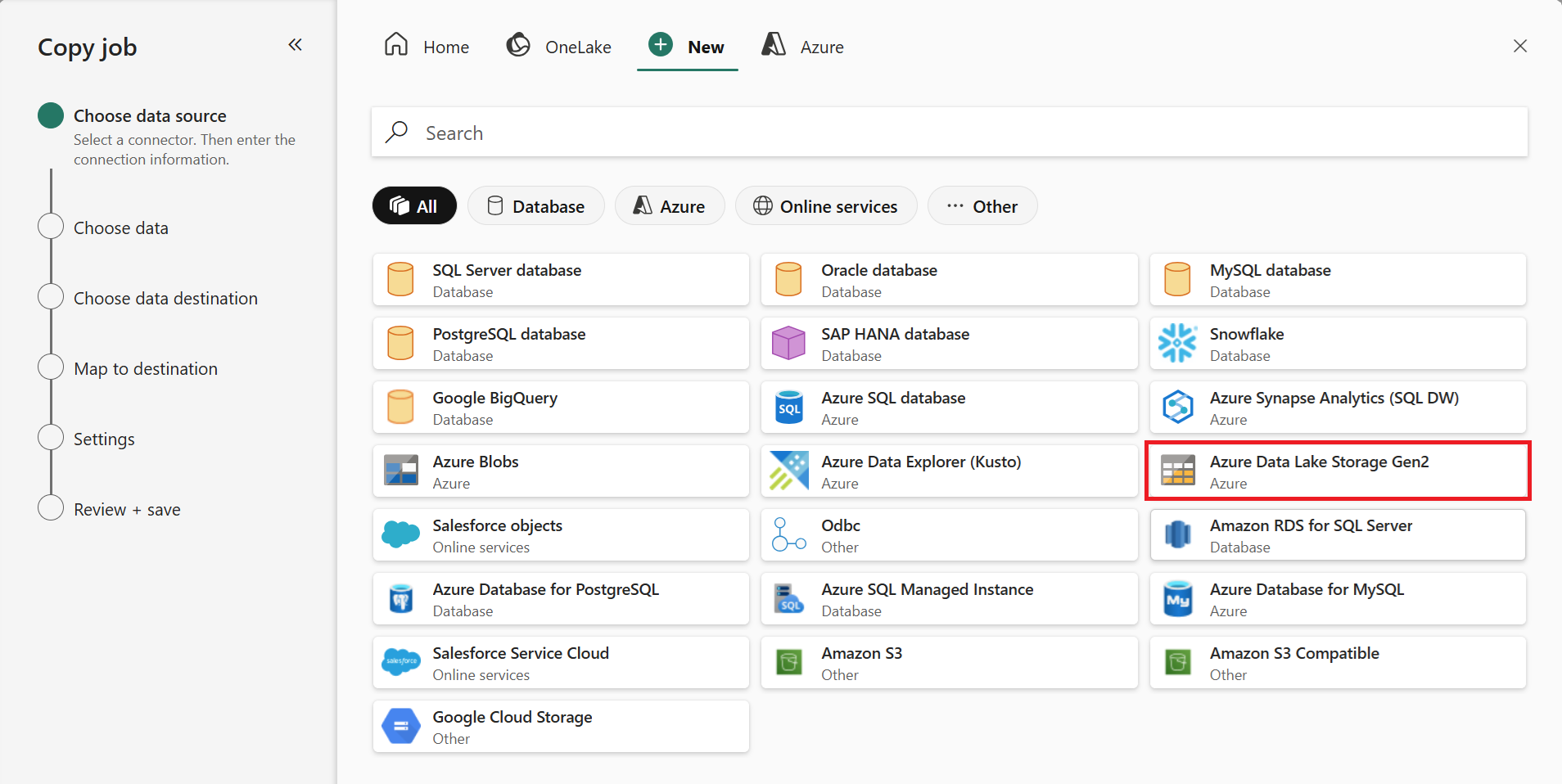
To connect to Azure Data Lake Storage Gen2, enter your Storage url and Credentials to connect to Azure Data Lake Storage Gen2. For other data stores, the connection details will vary. You can copy data securely within a virtual network environment using on-premises or virtual network gateway.
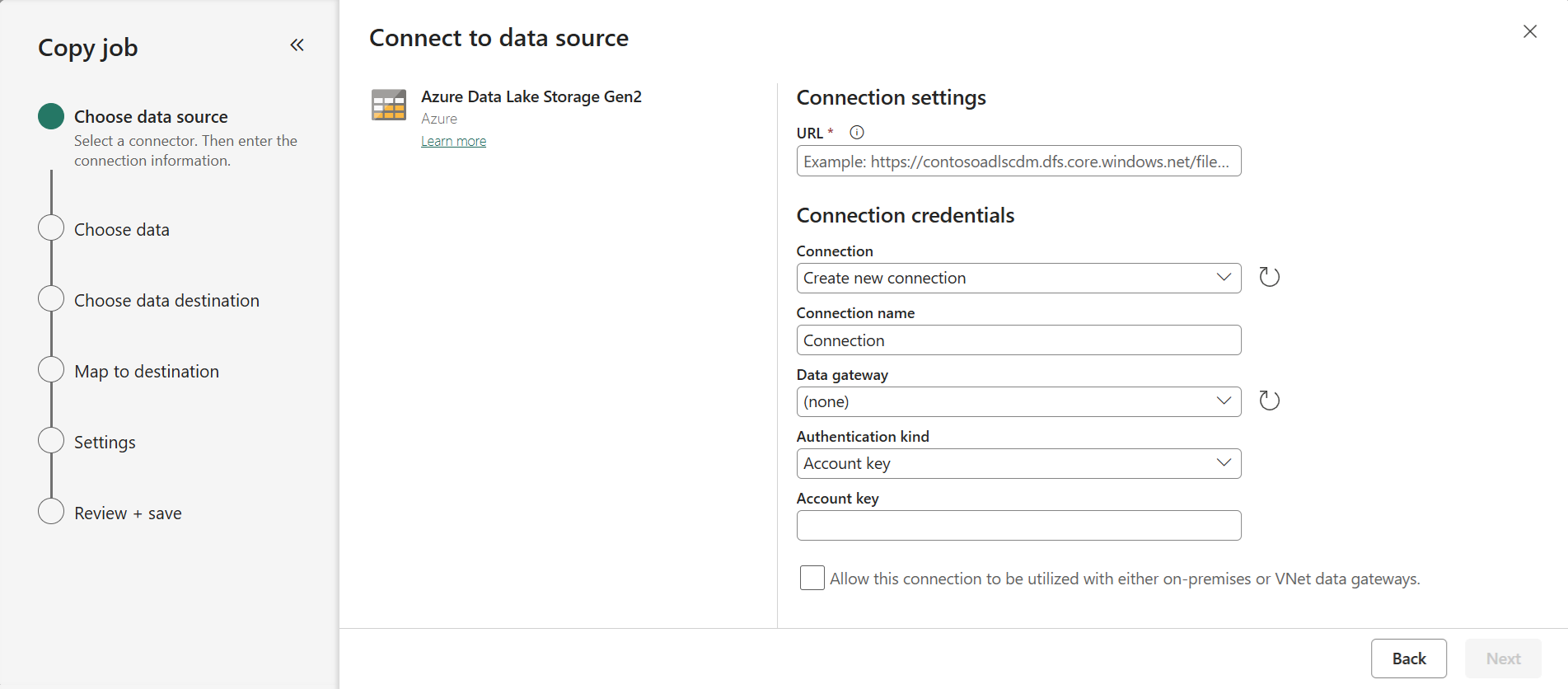
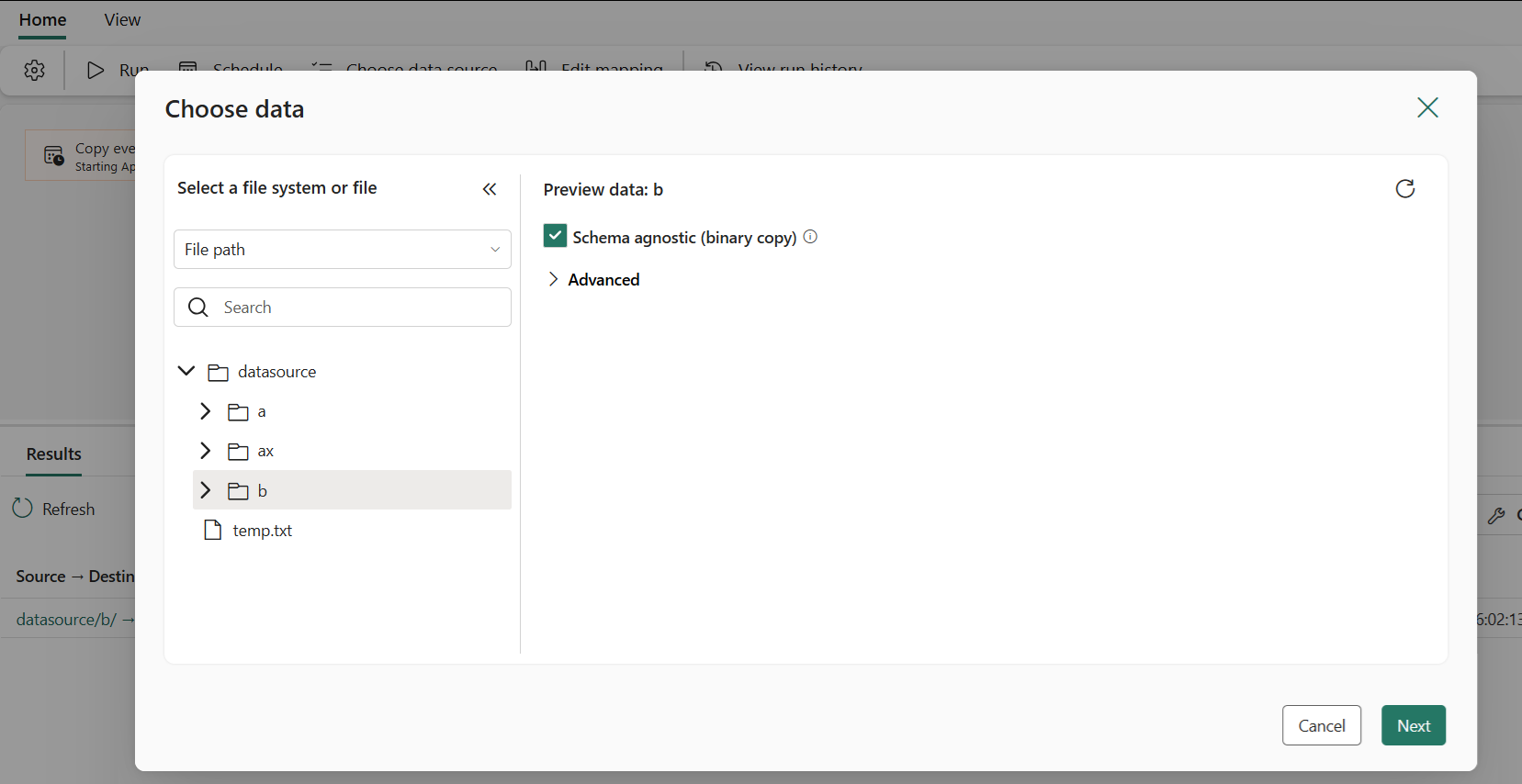
Select the folder or files to copy. You can choose to copy an entire folder with all its files, or a single file.
Tip
Schema agnostic (binary copy) copies files to another data store without parsing the schema. This can significantly improve copy performance.
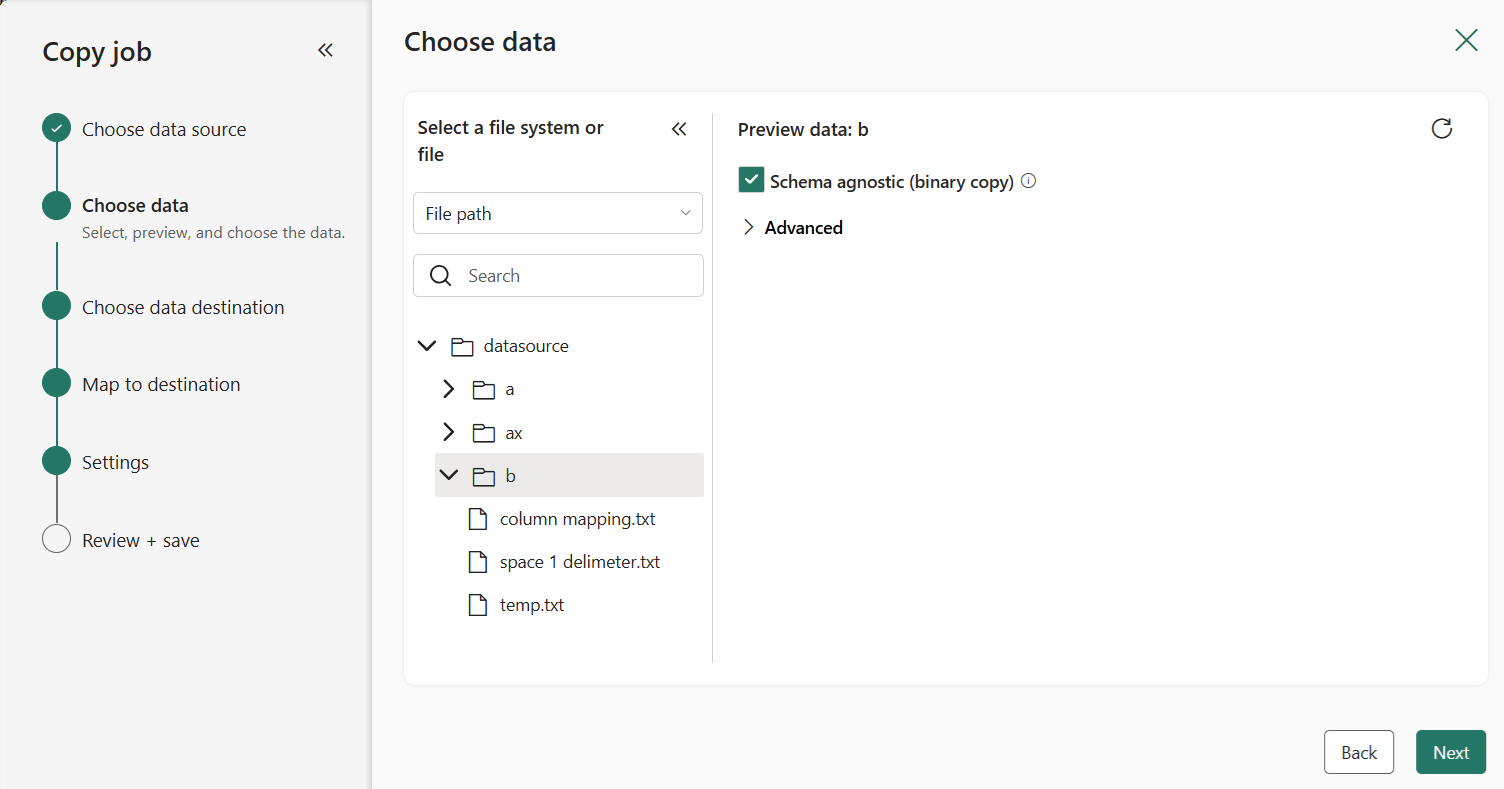
Select your destination store. In this example, we chose Lakehouse.
Select the Folder path in your destination storage. Choose Preserve Hierarchy to maintain the same folder structure as the source, or Flatten Hierarchy to place all files in a single folder.
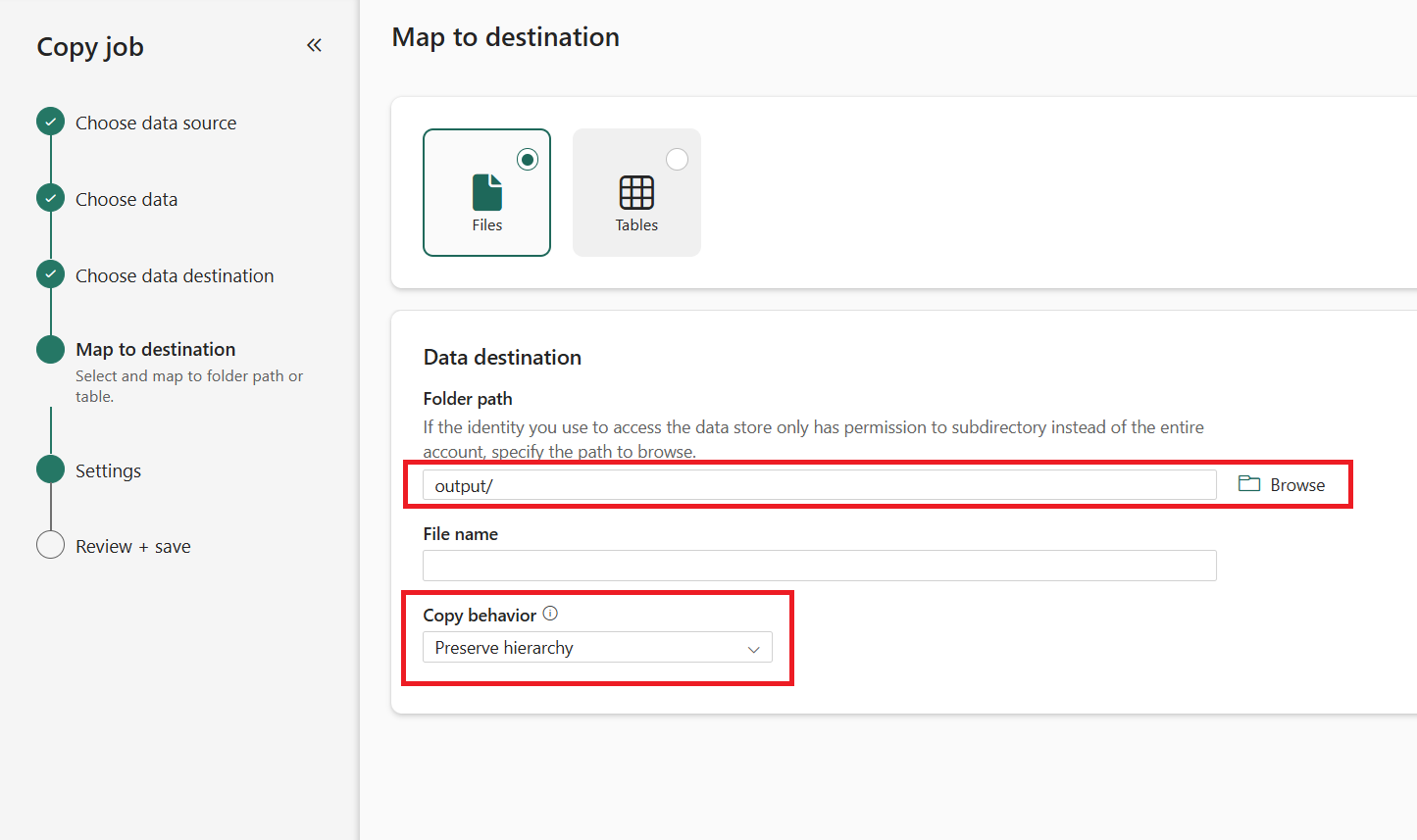
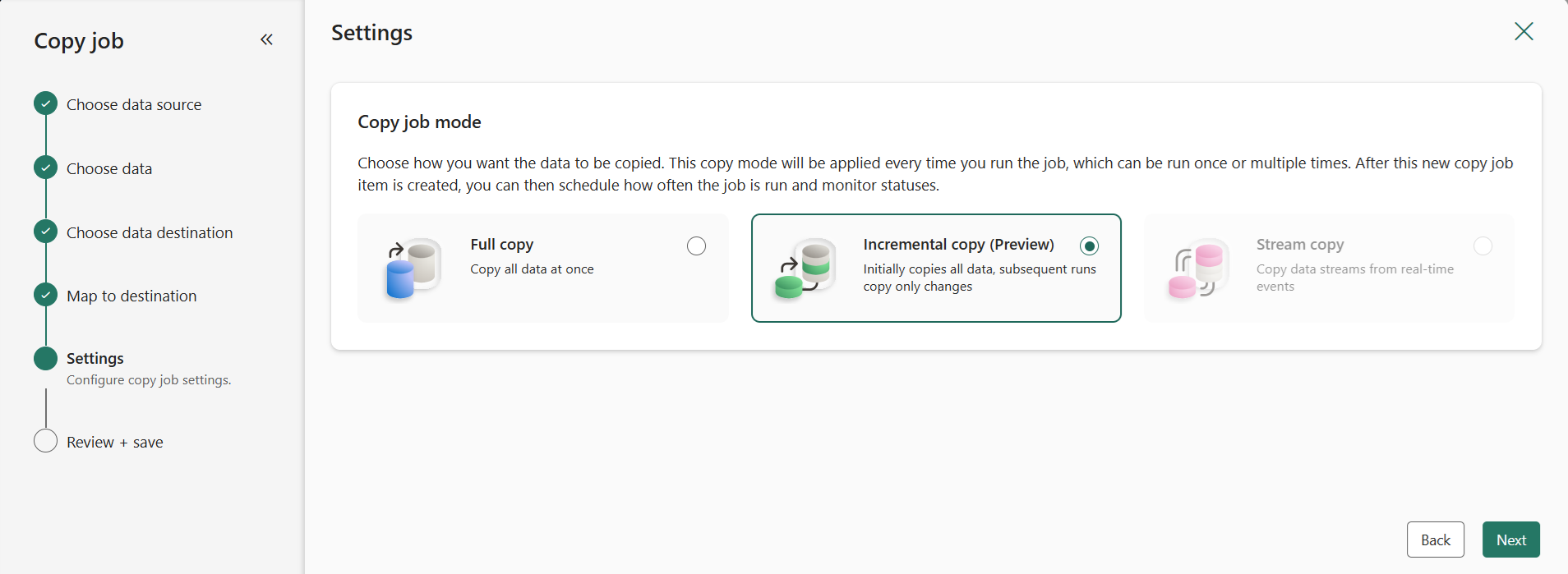
Choose a copy mode: Full data copy or Incremental copy. In this example, we use Incremental copy so that the Copy job will copy all files on the first run, and then copy only new or updated files in the next runs.
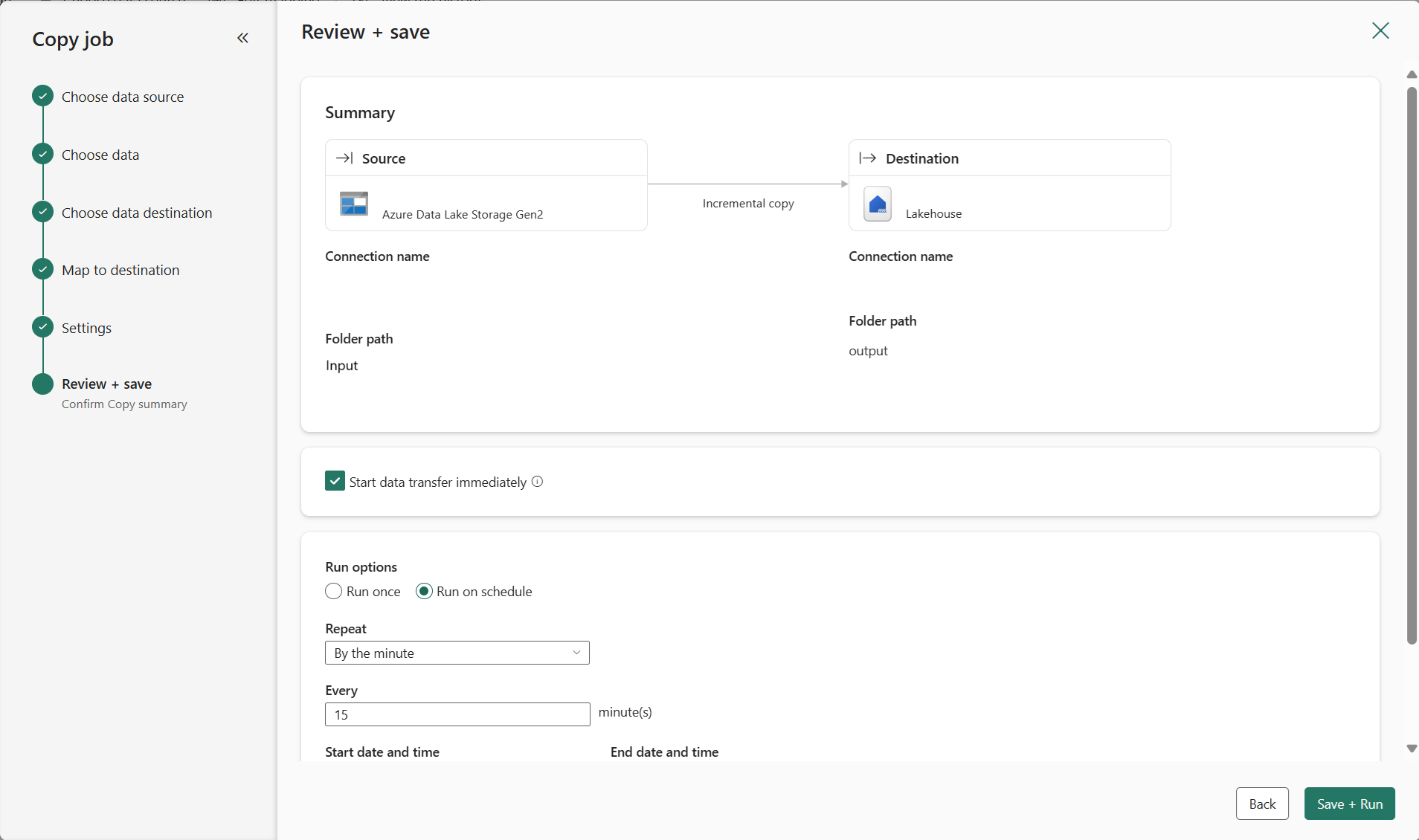
Review the job summary, select your run option to run once or on a schedule, and select Save + Run.
Your Copy job will start immediately, and you can track the job's status from the inline monitoring panel that has information including row counts and copy duration for each table. Learn more in How to monitor a Copy job
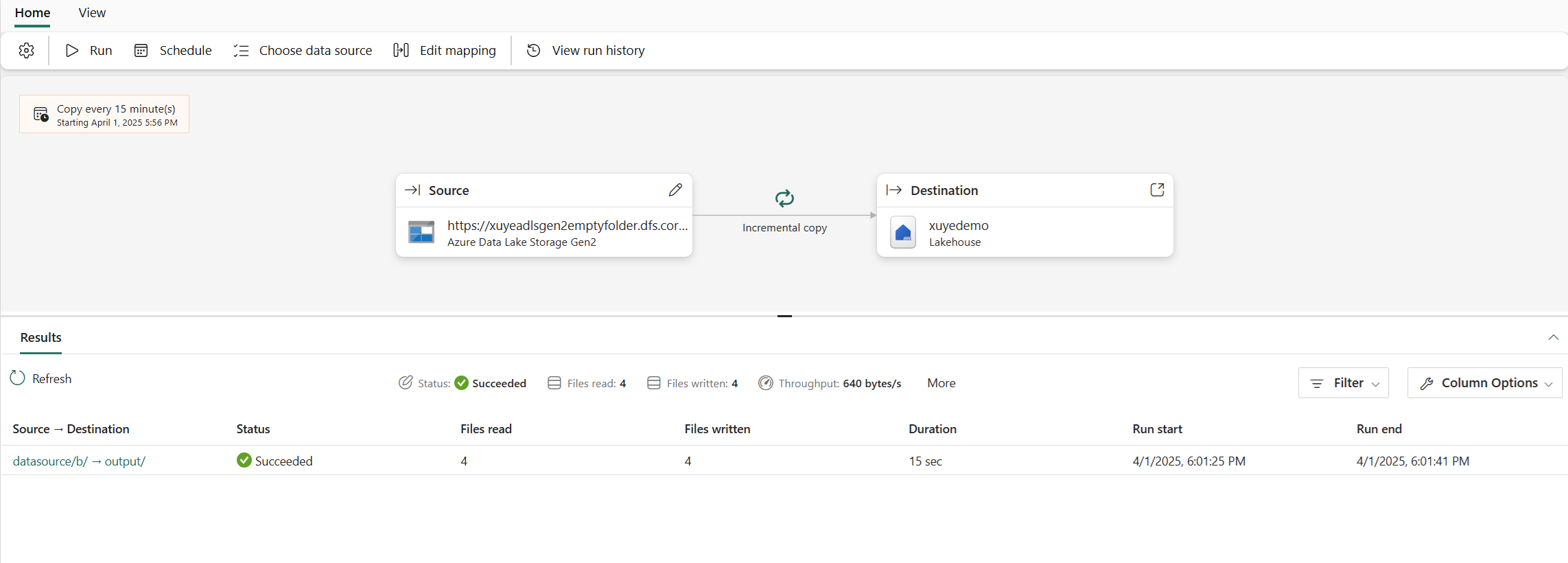
You can re-run your Copy job whenever you want, even if it's set to run on a schedule. Just select the Run button at any time, and Copy job copies only the data that's changed since the last run.
You can also edit your Copy job at any time, including configuring the schedule, or adjusting advanced settings.









Known limitations
- Currently, incremental copy mode only works with some sources. For details, see supported connectors for Copy job.
- Row deletion can't be captured from a source store.
- When copying files to storage locations, empty files will be created at the destination if no data is loaded from the source.