Note
Access to this page requires authorization. You can try signing in or changing directories.
Access to this page requires authorization. You can try changing directories.
Copilot in Microsoft Fabric is a generative AI assistive technology that aims to enhance the data analytics experience in the Fabric platform. This article helps you understand how Copilot in Fabric works and provides some high-level guidance and considerations about how you might best use it.
Note
Copilot's capabilities are evolving over time. If you plan to use Copilot, ensure that you keep up to date with the monthly updates to Fabric and any changes or announcements to the Copilot experiences.
This article helps you to understand how Copilot in Fabric works, including its architecture and cost. The information in this article is intended to guide you and your organization to use and manage Copilot effectively. This article is primarily targeted at:
BI and analytics directors or managers: Decision makers who are responsible for overseeing the BI program and strategy, and who decide whether to enable and use Copilot in Fabric or other AI tools.
Fabric administrators: The people in the organization who oversee Microsoft Fabric and its various workloads. Fabric administrators oversee who can use Copilot in Fabric for each of these workloads and monitor how Copilot usage affects available Fabric capacity.
Data architects: The people responsible for designing, building, and managing the platforms and architecture that support data and analytics in the organization. Data architects consider the usage of Copilot in architecture design.
Center of Excellence (COE), IT, and BI teams: The teams that are responsible for facilitating successful adoption and use of data platforms like Fabric in the organization. These teams and individuals might use AI tools like Copilot themselves, but also support and mentor self-service users in the organization to benefit from them, as well.
Overview of how Copilot in Fabric works
Copilot in Fabric works similar to the other Microsoft Copilots, such as Microsoft 365 Copilot, Microsoft Security Copilot, and Copilots and generative AI in Power Platform. However, there are several aspects that are specific to how Copilot in Fabric works.
Process overview diagram
The following diagram depicts an overview of how Copilot in Fabric works.
Note
The following diagram depicts the general architecture of Copilot in Fabric. However, depending on the specific workload and experience, there might be additions or differences.
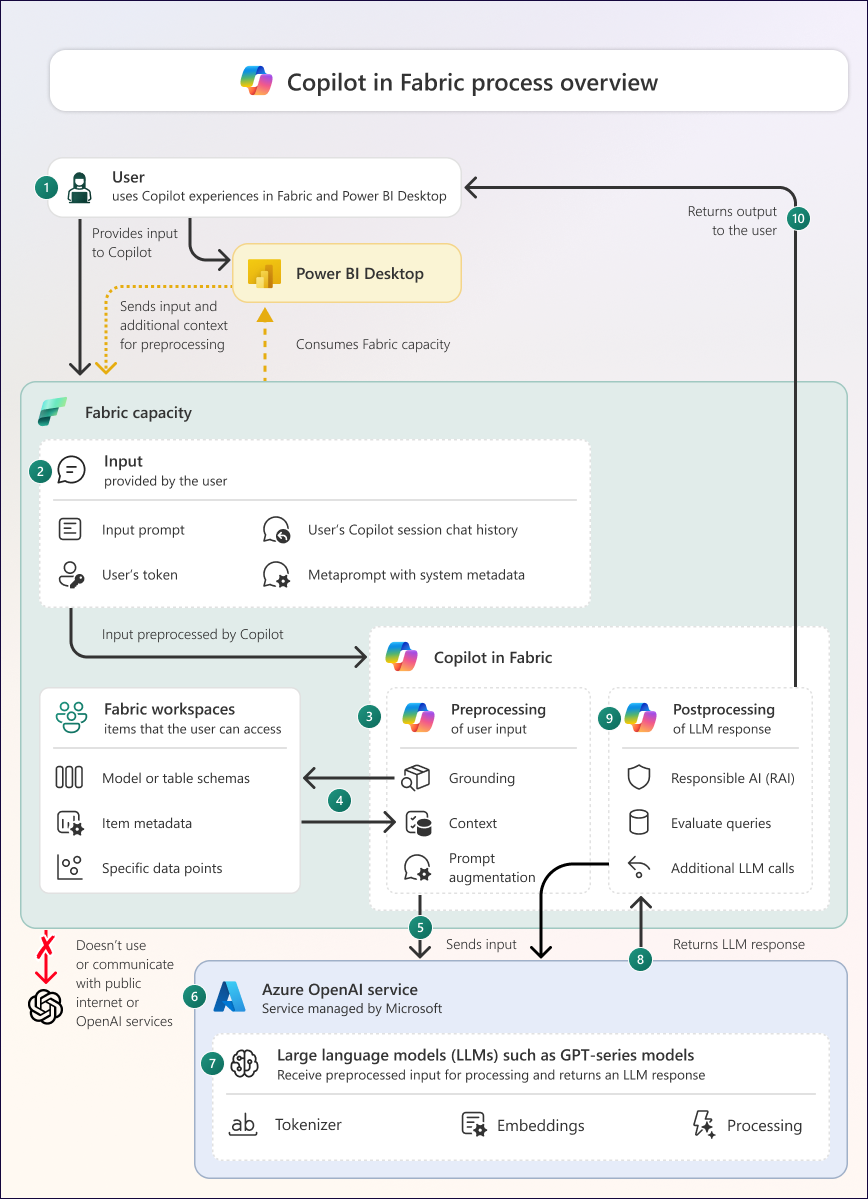
The diagram consists of the following parts and processes:
| Item | Description |
|---|---|
| 1 | The user provides an input to Copilot in Fabric, Power BI Desktop, or the Power BI mobile app. The input can be a written prompt or another interaction that generates a prompt. All interactions with Copilot are user-specific. |
| 2 | The input contains information that includes the prompt, the user's token, and context like the user's Copilot session chat history and a meta-prompt with system metadata, including where the user is and what they're doing in Fabric or Power BI Desktop. |
| 3 | Copilot handles preprocessing and postprocessing of user inputs and large language model (LLM) responses, respectively. Certain specific steps done during preprocessing and postprocessing depend on which Copilot experience an individual is using. Copilot must be enabled by a Fabric administrator in the tenant settings to use it. |
| 4 | During preprocessing, Copilot performs grounding to retrieve additional contextual information to improve the specificity and usefulness of the eventual LLM response. Grounding data might include metadata (such as the schema from a lakehouse or semantic model) or data points from items in a workspace, or the chat history from the current Copilot session. Copilot only retrieves grounding data that a user has access to. |
| 5 | Preprocessing results in the final inputs: a final prompt and grounding data. Which data is sent depends on the specific Copilot experience and what the user is asking for. |
| 6 | Copilot sends the input to the Azure OpenAI Service. This service is managed by Microsoft and isn't configurable by the user. Azure OpenAI doesn't train models with your data. If Azure OpenAI isn't available in your geographical area and you've enabled the tenant setting Data sent to Azure OpenAI can be processed outside your capacity's geographic region, compliance boundary, or national cloud instance, then Copilot might send your data outside of these geographical areas. |
| 7 | Azure OpenAI hosts LLMs like the GPT series of models. Azure OpenAI doesn't use the public services or APIs of OpenAI, and OpenAI doesn't have access to your data. These LLMs tokenize the input and use embeddings from their training data to process the inputs into a response. LLMs are limited in the scope and scale of their training data. Azure OpenAI contains configuration that determines how the LLM processes the input and which response it returns. It's not possible for customers to view or change this configuration. The call to the OpenAI Service is done via Azure, and not over the public internet. |
| 8 | The LLM response is sent from Azure OpenAI to Copilot in Fabric. This response comprises text, which might be natural language, code, or metadata. The response might include inaccurate or low-quality information. It's also non-deterministic, meaning that a different response might be returned for the same input. |
| 9 | Copilot postprocesses the LLM response. Postprocessing includes filtering for responsible AI, but also involves handling the LLM response and producing the final Copilot output. The specific steps taken during postprocessing depend on the Copilot experience an individual use. |
| 10 | Copilot returns the final output to the user. The user checks the output before use, as the output contains no indication of reliability, accuracy, or trustworthiness. |
The next sections describe the five steps in the Copilot process depicted in the previous diagram. These steps explain in detail how Copilot goes from user input to user output.
Step 1: A user provides input to Copilot
To use Copilot, a user must first submit an input. This input can be a written prompt that the user submits themselves, or it can be a prompt generated by Copilot when the user selects an interactive element in the UI. Depending on the specific Fabric workload, item, and Copilot experience that someone uses, they have different ways to provide an input to Copilot.
The following sections describe several examples of how a user can provide inputs to Copilot.
Input via the Copilot chat panel
With many Copilot experiences in Fabric, you can extend a Copilot chat panel to interact with Copilot using natural language like you would with a chatbot or messaging service. In the Copilot chat panel, you can write a natural language prompt describing the action that you want Copilot to take. Alternatively, the Copilot chat panel might contain buttons with suggested prompts that you can select. Interacting with these buttons causes Copilot to generate a corresponding prompt.
The following image shows an example of using the Copilot chat panel to ask a data question about a Power BI report.

Note
If you use the Microsoft Edge browser, you might also have access to Copilot there. Copilot in Edge can also open a Copilot chat panel (or sidebar) in your browser. The Copilot in Edge can't interact with or use any of the Copilot experiences in Fabric. While both Copilots have a similar user experience, Copilot in Edge is completely separate from Copilot in Fabric.
Input via context-dependent pop-up windows
In certain experiences, you can select the Copilot icon to trigger a pop-up window to interact with Copilot. Examples include when you use Copilot in the DAX query view or in the TMDL scripting view of Power BI Desktop. This pop-up window contains an area for you to enter a natural language prompt (similar to the Copilot chat panel) as well as context-specific buttons that can generate a prompt for you. This window might also contain output information, such as explanations about DAX queries or concepts when using Copilot in the DAX query view.
The following image shows an example of someone using the Copilot experience in the DAX query view to explain a query that they generated by using Copilot in Power BI.

Types of user inputs
Copilot inputs can be from a written prompt or a button in the UI:
Written prompt: A user can write a prompt in the Copilot chat panel, or in other Copilot experiences, like the DAX query view in Power BI Desktop. Written prompts require that the user adequately explains the instruction or question for Copilot. For instance, a user can ask a question about a semantic model or report when using Copilot in Power BI.
Button: A user can select a button in the Copilot chat panel or other Copilot experiences to provide an input. Copilot then produces the prompt based on the user selection. These buttons can be the initial input to Copilot, such as the suggestions in the Copilot chat panel. However, these buttons might also appear during a session when Copilot makes suggestions or requests clarifications. The prompt Copilot generates depends on the context, such as the chat history of the current session. An example of a button input is when you ask Copilot to suggest synonyms for model fields, or descriptions for model measures.
Additionally, you can provide inputs in different services or applications:
Fabric: You can use Copilot in Fabric from your web browser. This is the only way to use Copilot for any items that you exclusively create, manage, and consume in Fabric.
Power BI Desktop: You can use Copilot in Power BI Desktop with semantic models and reports. These include both the development and consumption Copilot experiences for the Power BI workload in Fabric.
Power BI mobile app: You can use Copilot in the Power BI mobile app if the report is in a supported workspace (or an app connected to that workspace) with Copilot enabled.
Note
To use Copilot with Power BI Desktop, you must configure Power BI Desktop to use Copilot consumption from a supported workspace backed by Fabric capacity. Then you can use Copilot with semantic models published to any workspace, including Pro and PPU workspaces.
While you can't alter the prompts that Copilot generates when you select a button with written prompts, you can ask questions and provide instructions using natural language. One of the most important ways to improve the results you get with Copilot is to write clear and descriptive prompts that accurately convey want you want to do.
Improve written prompts for Copilot
The clarity and quality of the prompt a user submits to Copilot can affect the usefulness of the output the user receives. What constitutes a good written prompt depends on the specific Copilot experience that you're using; however, there are some techniques that you can apply to all experiences to improve your prompts in general.
Here are several ways to improve prompts that you submit to Copilot:
Use English language prompts: Today, Copilot features work best in the English language. That's because the corpus of training data for these LLMs is mostly English. Other languages might not perform as well. You can try to write prompts in other languages, but for the best results, we recommend that you write and submit English language prompts.
Be specific: Avoid ambiguity or vagueness in questions and instructions. Include sufficient details to describe the task you want Copilot to perform, and what is the output that you expect.
Provide context: Where necessary, provide relevant context for your prompt, including what you intend to do or what question you want to answer with an output. For instance, the key components for a good prompt could include:
- Goal: What output you want Copilot to achieve.
- Context: What you intend to do with that particular output and why.
- Expectations: What you expect the output will look like.
- Source: What data or fields Copilot should use.
Use verbs: Refer explicitly to specific actions that you want Copilot to take, such as "create a report page" or "filter to customer key accounts".
Use correct and relevant terminology: Refer explicitly to the appropriate terms in your prompt, like function, field, or table names, visual types, or technical terminology. Avoid misspellings, acronyms, or abbreviations, as well as superfluous grammar, or atypical characters like Unicode characters or emojis.
Iterate and troubleshoot: When you don't get the expected result, try to adjust your prompt and re-submit it to see if this improves the output. Some Copilot experiences also provide a Retry button to re-submit the same prompt and check for a different result.
Important
Consider training users to write good prompts before you enable Copilot for them. Ensure that users understand the difference between a clear prompt that can produce useful results, and a vague prompt that doesn't.
Also, Copilot and many other LLM tools are non-deterministic. This means that two users submitting the same prompt that uses the same grounding data can obtain different results. This non-determinism is inherent to the underlying technology of generative AI, and is an important consideration when you expect or need deterministic results, such as an answer to a data question, like "What are the sales in August 2021?"
Other input information that Copilot uses in preprocessing
Aside from input that a user provides, Copilot also retrieves additional information that it uses in preprocessing during the next step. This information includes:
The user's token. Copilot doesn't operate under a system account or authority. All information sent to and used by Copilot is specific to the user; Copilot can't allow a user to view or access items or data that they don't already have permission to view.
The Copilot session chat history for the current session. For chat experiences or the Copilot chat panel, Copilot always provides the Chat history for use in preprocessing as part of the grounding data context. Copilot doesn't remember or use chat history from previous sessions.
Meta-prompt with system metadata. A meta-prompt provides additional context about where the user is and what they're doing in Fabric or Power BI Desktop. This meta-prompt information is used during preprocessing to determine which skill or tool Copilot should use to answer the user's question.
Once a user submits their input, Copilot proceeds to the next step.
Step 2: Copilot preprocesses the input
Before submitting a prompt to the Azure OpenAI Service, Copilot preprocesses it. Preprocessing constitutes all actions that are handled by Copilot between when it receives the input and when this input is processed in the Azure OpenAI Service. Preprocessing is necessary to ensure that Copilot's output is specific and appropriate to your instructions or questions.
You can't affect what preprocessing is done by Copilot. However, it's important to understand preprocessing so that you know what data Copilot uses and how it gets it. This is pertinent to understanding the cost of Copilot in Fabric, and when you troubleshoot why it produces an incorrect or unexpected result.
Tip
In certain experiences, you can also make changes to items so that their grounding data is better structured for Copilot to use. An example is performing linguistic modeling in a semantic model, or adding synonyms and descriptions to semantic model measures and columns.
The following diagram depicts what happens during preprocessing by Copilot in Fabric.
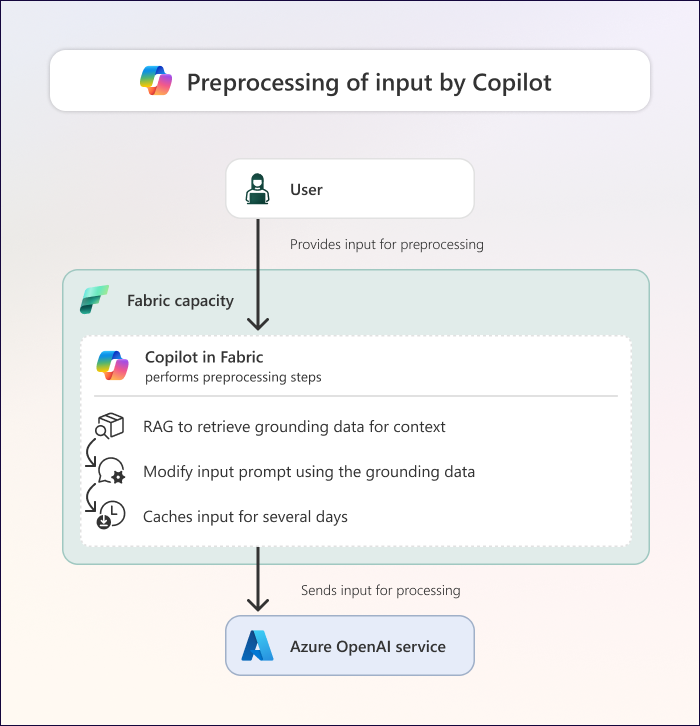
After receiving user input, Copilot performs preprocessing, which involves the following steps:
Grounding: Copilot performs retrieval augmented generation (RAG) to collect grounding data. Grounding data comprises relevant information from the current context in which you're using Copilot in Fabric. Grounding data might include context such as:
- The chat history from the current session with Copilot.
- Metadata about the Fabric item that you're using with Copilot (like the schema of your semantic model or lakehouse, or metadata from a report visual).
- Specific data points, such as those displayed in a report visual. Report metadata in the visual configuration also contains data points.
- Meta-prompts, which are supplemental instructions provided for each experience to help ensure a more specific and consistent output.
Prompt augmentation: Depending on the scenario, Copilot rewrites (or augments) the prompt based on the input and grounding data. The augmented prompt should be better and more context-aware than your original input prompt.
Caching: In certain scenarios, Copilot caches your prompt and the grounding data for 48 hours. Caching the prompt ensures that repeated prompts return the same results while cached, that they return these results faster, and that you aren’t consuming Fabric capacity just for repeating a prompt in the same context. Caching occurs in two different places:
- The browser cache of the user.
- The first back-end cache in the home region of the tenant, where it's stored for auditing purposes. No data is cached in the Azure OpenAI Service or the location of the GPUs. For more information about caching in Fabric, refer to the Microsoft Fabric security whitepaper.
Sending input to Azure OpenAI: Copilot sends the augmented prompt and the relevant grounding data to the Azure OpenAI Service.
When Copilot performs grounding, it only collects information from data or items that a user can access normally. Copilot respects workspace roles, item permissions, and data security. Copilot also can't access data from other users; interactions with Copilot are specific to each individual user.
The data that Copilot collects during the grounding process and what Azure OpenAI processes depends on the specific Copilot experience that you use. For more information, see What data does Copilot use and how is it processed?.
After the preprocessing is finished and Copilot has sent the input to Azure OpenAI, the Azure OpenAI Service can process that input to produce a response and output that's sent back to Copilot.
Step 3: Azure OpenAI processes the prompt and generates an output
All Copilot experiences are powered by the Azure OpenAI Service.
Understand the Azure OpenAI Service
Copilot uses Azure OpenAI—not OpenAI's publicly available services—to process all data and return a response. As mentioned earlier, this response is produced by an LLM. LLMs are a specific approach to "narrow" AI that focus on using deep learning to find and reproduce patterns in unstructured data; specifically, text. Text in this context includes natural language, metadata, code, and any other semantically meaningful arrangement of characters.
Copilot currently uses a combination of GPT models, including the Generative Pre-trained Transformer (GPT) series of models from OpenAI.
Note
You can't choose or change the models Copilot uses, including using other foundation models or your own models. Copilot in Fabric uses various models. It's also not possible for you to alter or configure the Azure OpenAI Service to behave differently with Copilot in Fabric; this service is managed by Microsoft.
The models used by Copilot in Fabric presently don't use any fine-tuning. The models instead rely on grounding data and meta-prompts to create more specific and useful outputs.
The models used by Copilot in Fabric presently don't use any fine-tuning. The models instead rely on grounding data and meta-prompts to create more specific and useful outputs.
Microsoft hosts the OpenAI models in Microsoft's Azure environment and the service doesn't interact with any public services by OpenAI (for example, ChatGPT or the public OpenAI APIs). Your data isn't used to train models and isn't available to other customers. For more information, see Azure OpenAI Service.
Understand tokenization
It's essential that you understand tokenization since the cost of Copilot in Fabric (which is how much Fabric capacity Copilot consumes) is determined by the number of tokens produced by your Copilot inputs and outputs.
To process the text input from Copilot, Azure OpenAI must first convert that input into a numerical representation. A key step in this process is tokenization, which is the partitioning of input text into different, smaller parts, called tokens. A token is a set of co-occurring characters, and it's the smallest unit of information that an LLM uses to produce its output. Each token has a corresponding numerical ID, which becomes the vocabulary of the LLM to encode and use text as numbers. There are different ways to tokenize text, and different LLMs tokenize input text in different ways. Azure OpenAI uses Byte-Pair Encoding (BPE), which is a method of sub-word tokenization.
To better understand what a token is and how a prompt becomes tokens, consider the following example. This example shows an input prompt and its tokens, estimated using the OpenAI Platform tokenizer(for GPT4). Beneath the highlighted tokens in the prompt text is an array (or list) of the numerical token IDs.

In the example, each differently colored highlight indicates a single token. As mentioned previously, Azure OpenAI uses subword tokenization, so a token isn't a word, but it also isn't a character, or a fixed number of characters. For instance "report" is a single token, but "." is, too.
To reiterate, you should understand what a token is because the cost of Copilot (or its Fabric capacity consumption rate) is determined by tokens. Therefore, understanding what a token is and how input and output tokens are created helps you understand and anticipate how Copilot usage results in consumption of Fabric CUs. For more information about the cost of Copilot in Fabric, see the appropriate section later in this article.
Copilot in Fabric uses both input and output tokens, as depicted in the following diagram.

Copilot creates two different kinds of tokens:
- Input tokens result from tokenizing both the final prompt and any grounding data.
- Output tokens result from tokenizing the LLM response.
Some Copilot experiences result in multiple LLM calls. For instance, when asking a data question about models and reports, the first LLM response might be a query evaluated against a semantic model. Copilot then sends the result of that evaluated query to Azure OpenAI again and requests a summary, which Azure OpenAI returns with another response. These additional LLM calls might be handled and the LLM responses combined during the postprocessing step.
Note
With Copilot in Fabric, except for changes to a written input prompt, you can only optimize input and output tokens by adjusting the configuration of the relevant items, like hiding columns in a semantic model or reducing the number of visuals or pages in a report. You can't intercept or modify the grounding data before it's sent to Azure OpenAI by Copilot.
Understand processing
It's important that you understand how an LLM in Azure OpenAI processes your data and produces an output, so that you can better understand why you get certain outputs from Copilot and why you should critically appraise them before further use or decision-making.
Note
This article provides a simple, high-level overview of how the LLMs that Copilot uses (like GPTs) work. For technical details and a deeper understanding of how GPT models process input to produce a response, or about their architecture, read the research papers Attention Is All You Need (2017) by Ashish Vaswani and others, and Language Models are Few-Shot Learners (2020) by Tom Brown and others.
The purpose of Copilot (and LLMs in general) is to provide a context-appropriate, useful output, based on the input that a user provides and other relevant grounding data. An LLM does this by interpreting the meaning of tokens in a similar context, as seen in their training data. To get a meaningful semantic understanding of tokens, LLMs have been trained on massive datasets thought to comprise both copyrighted and public domain information. However, this training data is limited in terms of content freshness, quality, and scope, which creates limitations for LLMs and the tools that use them, such as Copilot. For more information about these limitations, see Understand the limitations of Copilot and LLMs later in this article.
The semantic meaning of a token is captured in a mathematical construct referred to as an embedding, which turns tokens into dense vectors of real numbers. In simpler terms, embeddings provide LLMs with the semantic meaning of a given token, based on the other tokens around it. This meaning depends on the LLM training data. Think of tokens like unique building blocks, while embeddings help an LLM know what block to use when.
Using tokens and embeddings, the LLM in Azure OpenAI processes your input and generates a response. This processing is a computationally intensive task that requires significant resources, which is where the cost comes from. An LLM produces its response one token at a time, where it selects each token using a computed probability based on the input context. Each generated token is also added to that existing context before producing the next token. The final response of the LLM must therefore always be text, which Copilot might later postprocess to make a more useful output for the user.
It's important to understand several key aspects about this generated response:
- It's non-deterministic; the same input can produce a different response.
- It can be interpreted as low-quality or incorrect by the user in their context.
- It's based on the LLM training data, which is finite and limited in its scope.
Understand the limitations of Copilot and LLMs
It's important to understand and acknowledge the limitations of Copilot and the underlying technology that it uses. Understanding these limitations helps you to get value from Copilot while also mitigating risks inherent to using it. To use Copilot in Fabric effectively, you should understand the use-cases and scenarios that best fit this technology.
It's important to keep the following considerations in mind when you use Copilot in Fabric:
Copilot in Fabric is non-deterministic. Except for when a prompt and its output are cached, the same input can produce different outputs. When you accept a range of possible outputs—like a report page, a code pattern, or a summary—this is less of a problem, because you can tolerate and might even expect variety in the response. However, for scenarios when you expect only one correct answer, you might want to consider an alternative approach to Copilot.
Copilot in Fabric can produce low quality or inaccurate outputs: Like all LLM tools, it's possible for Copilot to produce outputs that might not be correct, expected, or suitable for your scenario. This means that you should avoid using Copilot in Fabric with sensitive data or in high-risk areas. For example, you shouldn't use Copilot outputs to answer data questions about business-critical processes, or to create data solutions that might affect the personal or collective well-being of individuals. Users should check and validate Copilot outputs before they use them.
Copilot has no understanding of "accuracy" or "truthfulness": The outputs that Copilot provides don't provide an indication of trustworthiness, reliability, or similar sentiments. The underlying technology involves pattern recognition and is unable to evaluate the quality or usefulness of its outputs. Users should critically evaluate outputs before they use these outputs in other work or decision-making.
Copilot can't reason, understand your intent, or know context beyond its input: While the grounding process of Copilot ensures that outputs are more specific, grounding alone can't give Copilot all the information that it needs to answer your questions. For instance, if you use Copilot to generate code, Copilot still doesn't know what you'll do with that code. This means that the code might work in one context, but not another, and users must either modify the output or their prompt to address this.
Copilot outputs are limited by the training data of the LLMs it uses: In certain Copilot experiences, such as those where you generate code, you might want Copilot to generate code with a newly released function or pattern. However, Copilot won't be able to do this effectively if there are no examples of that in the training data of the GPT models it uses, which has a cutoff in the past. This also happens when you try to apply Copilot to contexts that are sparse in its training data, like when using Copilot with the TMDL editor in Power BI Desktop. In these scenarios, you should be particularly vigilant and critical of low-quality or inaccurate outputs.
Warning
To mitigate the risks of these limitations and considerations, and the fact that Copilot, LLMs, and generative AI are nascent technology, you should not use Copilot in Fabric for autonomous, high-risk, or business-critical processes and decision-making.
For more information, see Security guidance for LLMs.
Once the Azure OpenAI Service processes the input and produces a response, it returns this response as an output to Copilot.
Step 4: Copilot performs postprocessing on the output
Upon receiving the response from Azure OpenAI, Copilot performs additional postprocessing to ensure that the response is appropriate. The purpose of postprocessing is to filter out inappropriate content.
To perform postprocessing, Copilot might perform the following tasks:
Responsible AI checks: Ensuring Copilot complies with the responsible AI standards at Microsoft. For more information, see What should I know to use Copilot responsibly?
Filtering with Azure content moderation: Filtering responses to ensure that Copilot only returns responses appropriate to the scenario and experience. Here are some examples of how Copilot performs filtering with Azure content moderation:
- Unintended or improper use: Content moderation ensures that you can't use Copilot in unintended or improper ways, such as asking questions about other topics outside the scope of the workload, item, or experience you're using.
- Inappropriate or offensive outputs: Copilot prevents outputs that could contain unacceptable language, terms, or phrases.
- Attempts of prompt injection: Copilot prevents prompt injection, where users attempt to hide disruptive instructions in grounding data, like in object names, descriptions, or code comments in a semantic model.
Scenario-specific constraints: Depending on which Copilot experience you use, there might be additional checks and handling of the LLM response before you receive the output. Here are some examples of how Copilot enforces scenario-specific constraints:
- Code parsers: Generated code might be put through a parser to filter out low-quality responses and errors to ensure that the code runs. This happens when you generate DAX queries by using Copilot in the DAX query view of Power BI Desktop.
- Validation of visuals and reports: Copilot checks that visuals and reports can render before returning them in an output. Copilot doesn't validate whether the results are accurate or useful, or whether the resulting query will time out (and produce an error).
Handling and using the response: Taking the response and adding additional information or using it in other processes to provide the output to the user. Here are some examples of how Copilot might handle and use a response during postprocessing:
- Power BI report page creation: Copilot combines the LLM response (report visual metadata) with other report metadata, which results in creating a new report page. Copilot might also apply a Copilot theme if you haven't created any visuals in the report yet. The theme isn't part of the LLM response, and it includes a background image, as well as colors and visual styles. If you've created visuals, then Copilot doesn't apply the Copilot theme and uses the theme you already have applied. When changing a report page, Copilot will also delete the existing page and replace it with a new one with the adjustments applied.
- Power BI data questions: Copilot evaluates a query against a semantic model.
- Data factory dataflow gen2 transformation step suggestion: Copilot modifies the item metadata to insert the new step, adjusting the query.
Additional LLM calls: In certain scenarios, Copilot might perform additional LLM calls to enrich the output. For instance, Copilot might submit the result of an evaluated query to the LLM as a new input and request an explanation. This natural language explanation is then packaged together with the query result in the output that a user sees in the Copilot chat panel.
If content is filtered out in the output, then Copilot will either re-submit a new, modified prompt, or return a standard response.
Resubmit a new prompt: When a response doesn't meet scenario-specific constraints, Copilot will produce another modified prompt to try again. In some circumstances, Copilot might suggest several new prompts for the user to select before submitting the prompt to generate a new output.
Standard response: The standard response in this case would indicate a generic error. Depending on the scenario, Copilot might provide additional information to guide the user to produce another input.
Note
It isn't possible to view the original, filtered responses from Azure OpenAI, or to alter the standard responses from or behavior of Copilot. This is managed by Microsoft.
After postprocessing is complete, Copilot will then return an output to the user.
Step 5: Copilot returns the output to the user
The output for a user can take the form of natural language, code, or metadata. This metadata will typically be rendered in the UI of Fabric or Power BI Desktop, such as when Copilot returns a Power BI visual or suggests a report page. For some Copilot in Power BI experiences, the user can provide both inputs and outputs to Copilot via the Power BI mobile app.
In general, outputs can either allow user intervention or be fully autonomous and not allow the user to alter the result.
User intervention: These outputs allow a user to modify the result before it's evaluated or displayed. Some examples of outputs that allow user intervention include:
- Generation of code like DAX or SQL queries, which a user can choose to keep or run.
- Generation of measure descriptions in a semantic model, which a user can choose to keep, modify, or delete.
Autonomous: These outputs can't be altered by the user. The code might be evaluated directly against a Fabric item, or the text isn't editable in the pane. Some examples of autonomous outputs include:
- Answers to data questions about a semantic model or report in the Copilot chat panel, which automatically evaluate queries against the model and show the result.
- Summaries or explanations of code, items, or data, which automatically choose what to summarize and explain, and show the result.
- Creation of a report page, which automatically creates the page and visuals in the report.
Sometimes, as part of the output, Copilot might also suggest an additional, follow-up prompt, such as requesting clarification, or another suggestion. This is typically useful when the user wants to improve the result or continue working on a specific output, like explaining a concept to understand generated code.
Outputs from Copilot might contain low-quality or inaccurate content
Copilot has no way to evaluate or indicate the usefulness or accuracy of its outputs. As such, it's important that users evaluate this themselves whenever they use Copilot.
To mitigate risks or challenges from LLM hallucinations in Copilot, consider the following advice:
Train users to use Copilot and other similar tools that leverage LLMs. Consider training them on the following topics:
- What Copilot can and can't do.
- When to use Copilot and when not to use it.
- How to write better prompts.
- How to troubleshoot unexpected results.
- How to validate outputs by using trusted online sources, techniques, or resources.
Test items with Copilot before you allow these items to be used with it. Certain items require certain preparatory tasks to ensure that they work well with Copilot.
Avoid using Copilot in autonomous, high-risk, or business-critical decision-making processes.
Important
Additionally, review the supplemental preview terms for Fabric, which include terms of use for Microsoft Generative AI Service Previews. While you can try and experiment with these preview features, we recommend that you don't use Copilot features in preview in production solutions.
Privacy, security, and responsible AI
Microsoft is committed to ensuring that our AI systems are guided by our AI principles and Responsible AI Standard. See Privacy, security, and responsible use of Copilot in Fabric for a detailed overview. See also Data, privacy, and security for Azure OpenAI Service for detailed information specific for Azure OpenAI.
For an overview specifically for each Fabric workload, see the following articles:
- Responsible use in Data Factory
- Responsible use in Data Science and Data Engineering
- Responsible use in Data Warehousing
- Responsible use in Power BI
- Responsible use in Real-Time Intelligence
Cost of Copilot in Fabric
Unlike other Microsoft Copilots, Copilot in Fabric doesn't require additional per-user or per-capacity licenses. Rather, Copilot in Fabric consumes from your available Fabric capacity units (CUs). The consumption rate of Copilot is determined by the number of tokens in your inputs and outputs when you use it across the various experiences in Fabric.
If you have a Fabric capacity, you're using either a pay-as-you-go or reserved instance. In both cases, Copilot consumption works the same. In a pay-as-you-go scenario, you're billed per second that your capacity is active until you pause your capacity. Billing rates have no relationship to the usage of your Fabric CUs; you pay the same amount if your capacity is fully utilized or completely unused. As such, Copilot doesn't have a direct cost or impact on your Azure billing. Rather, Copilot consumes from the available CUs which other Fabric workloads and items also use, and if you use too much, users will experience reduced performance and throttling. It's also possible to enter a state of CU debt called carryforward. For more information about throttling and carryforward, see Throttle triggers and throttle stages.
The following sections explain more about how you should understand and manage Copilot consumption in Fabric.
Note
For more information, see Copilot in Fabric consumption.
Copilot consumption in Fabric is determined by tokens
Copilot consumes your available Fabric CUs, also commonly referred to as capacity, compute, or resources. The consumption is determined by the input and output tokens when you use it. To review, you can understand input and output tokens as a result of tokenizing the following:
- Input tokens: Tokenization of your written prompt and grounding data.
- Output tokens: Tokenization of the Azure OpenAI response, based on the input. Output tokens are three times more expensive than input tokens.
You can limit the number of input tokens by using shorter prompts, but you can't control what grounding data Copilot uses for preprocessing, or the number of output tokens that the LLM in Azure OpenAI returns. For instance, you can expect that the report creation experience for Copilot in Power BI will have a high consumption rate, since it might use grounding data (like your model schema) and might produce a verbose output (report metadata).
Inputs, outputs, and grounding data are converted to tokens
To reiterate from an earlier section in this article, it's important to understand the tokenization process so that you know what kinds of inputs and outputs produce the highest consumption.
Optimizing prompt tokens isn't likely to have a significant effect on your Copilot costs. For instance, the number of tokens in a written user prompt is typically much smaller than the tokens of grounding data and outputs. Copilot handles the grounding data and outputs autonomously; you can't optimize or influence these tokens. For instance, when using Copilot in Power BI, Copilot might use the schema from of your semantic model or metadata from your report as grounding data during preprocessing. This metadata likely comprises many more tokens than your initial prompt.
Copilot performs various system optimizations to reduce input and output tokens. These optimizations depend on the Copilot experience that you're using. Examples of system optimizations include:
Schema reduction: Copilot doesn't send the entire schema of a semantic model or lakehouse table. Instead, it uses embeddings to determine which columns to send.
Prompt augmentation: When rewriting the prompt during preprocessing, Copilot tries to produce a final prompt that will return a more specific result.
Additionally, there are various user optimizations that you can implement to limit what grounding data Copilot can see and use. These user optimizations depend on the item and experience that you're using. Some examples of user optimizations include:
Hiding fields or marking tables as private in a semantic model: Any hidden or private objects won't be considered by Copilot.
Hiding report pages or visuals: Similarly, any hidden report pages or visuals hidden behind a report bookmark are also not considered by Copilot.
Tip
User optimizations are mainly effective for improving the usefulness of Copilot outputs, rather than optimizing Copilot cost. For more information, see articles specific to the various workloads and Copilot experiences.
You have no visibility on the tokenization process, and you can only minimally impact the input and output tokens. As such, the most effective way for you to manage Copilot consumption and avoid throttling is by managing Copilot usage.
Copilot is a background operation that's smoothed
Concurrent usage of Copilot in Fabric—when many individuals are using it at the same time—is handled by a process called smoothing. In Fabric, any operation classified as a background operation has its CU consumption divided over a 24-hour window, starting from the time of the operation to exactly 24 hours later. This is in contrast to interactive operations, like semantic model queries from individuals using a Power BI report, which aren't smoothed.
Note
To simplify your understanding, background and interactive operations classify different things that happen in Fabric for billing purposes. They don't necessarily relate to whether an item or feature is interactive for a user or happening in the background, as their names might suggest.
For example, if you use 48 CUs with a background operation now, it results in 2 CUs of consumption now, and also 2 CUs each hour from now until 24 hours from now. If you use 48 CUs with an interactive operation, it results in an observed 48 CUs used now, and has no effect on future consumption. However, smoothing also means that you can potentially accumulate CU consumption in that window if your usage of Copilot or other Fabric workloads is sufficiently high.
To better understand smoothing and its effects on your Fabric CU consumption, consider the following diagram:

The diagram depicts an example of a scenario with high concurrent usage of an interactive operation (which isn't smoothed). An interactive operation crosses the throttling limit (the available Fabric capacity) and enters carryforward. This is the scenario without smoothing. In contrast, background operations like Copilot have the consumption spread over 24 hours. Subsequent operations within that 24-hour window will "stack" and contribute to total cumulative consumption in that period. In the smoothed scenario of this example, the background operations like Copilot would contribute to future CU consumption, but don't trigger throttling or cross any limits.
Monitor Copilot consumption in Fabric
Fabric administrators can monitor how much Copilot consumption is occurring in your Fabric capacity by using the Microsoft Fabric Capacity Metrics app. In the app, a Fabric administrator can view a breakdown by activity and user, helping them to identify the individuals and areas where they might need to focus during periods of high consumption.
Tip
Rather than considering abstract calculations like tokens to CUs, we recommend that you focus on the percentage of your Fabric capacity that you've utilized. This metric is the simplest to understand and act upon, because once you reach 100% utilization, you can experience throttling.
You can find this information on the timepoint page of the app.
Note
When you pause a capacity, the smoothed usage is compacted into the timepoint in which the capacity becomes paused. This compaction of the smoothed consumption results in a peak of observed consumption, which doesn't reflect your actual usage. This peak will often produce notifications and warnings that you've exhausted your available Fabric capacity, but these are false positives.
Alleviate high utilization and throttling
Copilot consumes Fabric CUs, and even with smoothing, you might encounter situations of high utilization, which leads to high consumption, and throttling of your other Fabric workloads. The following sections discuss some strategies you can use to alleviate the impact on your Fabric capacity in this scenario.
User training and allowlisting
An important way to ensure effective adoption of any tool is to equip users with sufficient mentoring and training, and to gradually roll out access as people complete such training. Effective training is a preventative measure to avoid high utilization and throttling preemptively, by educating users about how to use Copilot effectively and on what not to do.
You can best control who can use Copilot in Fabric by creating an allowlist of users with access to the feature from the Fabric tenant settings. This means that you enable Copilot in Fabric only for users who belong to specific security groups. If necessary, you might create separate security groups for each of the Fabric workloads where you can enable Copilot to obtain finer grain control over who can use which Copilot experiences. For more information about creating security groups, see Create, edit, or delete a security group.
Once you add specific security groups to the Copilot tenant settings, you can put together onboarding training for users. A Copilot training course should cover basic topics, such as the following.
Tip
Consider creating an overview training for basic concepts about LLMs and generative AI, but then create workload-specific training for users. Not every individual needs to learn about every Fabric workload if it isn't necessarily relevant to them.
LLMs: Explain the basics of what an LLM is and how it works. You shouldn't go into technical details, but you should explain concepts like prompts, grounding, and tokens. You can also explain how LLMs can get meaning from input and produce context-appropriate responses because of their training data. Teaching this to users helps them understand how the technology works and what it can and can't do.
What Copilot and other generative AI tools are used for: You should explain that Copilot isn't an autonomous agent and isn't intended to replace humans in their tasks, but meant to augment individuals to potentially perform their current tasks better and faster. You should also emphasize cases where Copilot isn't suitable, using specific examples, and explain what other tools and information individuals might use to address their problems in those scenarios.
How to critically appraise Copilot outputs: It's important that you guide users about how they can validate Copilot outputs. This validation depends on the Copilot experience they're using, but in general, you should emphasize the following points:
- Check each output before you use it.
- Evaluate and ask yourself if the output is correct or not.
- Add comments to generated code to understand how it works. Alternatively, ask Copilot for explanations for that code, if necessary, and cross-reference that explanation with trusted sources.
- If the output produces an unexpected result, troubleshoot with different prompts or by performing manual validation.
Risks and limitations of LLMs and generative AI: You should explain key risks and limitations of Copilot, LLMs, and generative AI, such as those mentioned in this article:
- They're non-deterministic.
- They provide no indication or guarantees of accuracy, reliability, or truthfulness.
- They can hallucinate and produce inaccurate or low-quality outputs.
- They can't generate information that spans outside the scope of their training data.
Where to find Copilot in Fabric: Provide A a high-level overview of the different workloads, items, and Copilot experiences that someone might use.
Scale your capacity
When you experience throttling in Fabric due to Copilot consumption or other operations, you can temporarily scale (or resize) your capacity to a higher SKU. This is a reactive measure that temporarily elevates your cost to alleviate short-term issues due to throttling or carryforward. This is particularly helpful when you experience throttling primarily due to background operations, since the consumption (and thus the impact) might be spread over a 24-hour window.
Split-capacity strategies
In scenarios where you expect a high usage of Copilot in Fabric (such as in large organizations), you might consider isolating Copilot consumption from your other Fabric workloads. In this split-capacity scenario, you prevent Copilot consumption from negatively impacting other Fabric workloads by enabling Copilot only on a separate F64 or higher SKU, which you only use for dedicated Copilot experiences. This split-capacity strategy produces higher cost, but it might make it easier to manage and govern Copilot usage.
Tip
You can use some Copilot experiences with items in other capacities that don't support or enable Copilot. For example, in Power BI Desktop, you can link to a workspace with an F64 SKU Fabric capacity, but then connect to a semantic model in an F2 or PPU workspace. Then, you can use Copilot experiences in Power BI Desktop, and the Copilot consumption will only affect the F64 SKU.
The following diagram depicts an example of a split-capacity strategy to isolate Copilot consumption with experiences like those in Copilot in Power BI Desktop.

You can also use a split-capacity solution by assigning Copilot consumption to a separate capacity. Assigning Copilot consumption to a separate capacity ensures that high utilization of Copilot doesn't impact your other Fabric workloads and the business-critical processes that depend on them. Of course, using any split-capacity strategy requires that you already have two or more F64 or higher SKUs. As such, this strategy might not be manageable for smaller organizations or organizations with a limited budget to spend on their data platforms.
Irrespective of how you choose to manage Copilot, what's most important is that you monitor Copilot consumption in your Fabric capacity.